Initial commit
This commit is contained in:
parent
054cbd03c4
commit
b6dbdad80f
|
|
@ -0,0 +1,27 @@
|
||||||
|
name: Django CI
|
||||||
|
|
||||||
|
on:
|
||||||
|
push:
|
||||||
|
branches: [ main ]
|
||||||
|
pull_request:
|
||||||
|
branches: [ main ]
|
||||||
|
|
||||||
|
jobs:
|
||||||
|
test:
|
||||||
|
runs-on: ubuntu-latest
|
||||||
|
steps:
|
||||||
|
- uses: actions/checkout@v2
|
||||||
|
- name: Set up Python
|
||||||
|
uses: actions/setup-python@v2
|
||||||
|
with:
|
||||||
|
python-version: 3.7
|
||||||
|
- name: Install Dependencies
|
||||||
|
run: |
|
||||||
|
python -m pip install --upgrade pip
|
||||||
|
pip install -r requirements.txt
|
||||||
|
- name: Run Tests
|
||||||
|
env:
|
||||||
|
DJANGO_SETTINGS_MODULE: academic_graph.settings.test
|
||||||
|
SECRET_KEY: ${{ secrets.DJANGO_SECRET_KEY }}
|
||||||
|
run: |
|
||||||
|
python manage.py test --noinput
|
||||||
|
|
@ -0,0 +1,18 @@
|
||||||
|
# PyCharm
|
||||||
|
/.idea/
|
||||||
|
|
||||||
|
# Python
|
||||||
|
__pycache__/
|
||||||
|
|
||||||
|
# 数据集
|
||||||
|
/data/
|
||||||
|
|
||||||
|
# 保存的模型
|
||||||
|
/model/
|
||||||
|
|
||||||
|
# 日志输出目录
|
||||||
|
/output/
|
||||||
|
|
||||||
|
# Django
|
||||||
|
/static/
|
||||||
|
/.mylogin.cnf
|
||||||
411
README.md
411
README.md
|
|
@ -1,3 +1,410 @@
|
||||||
# GNNRecom
|
# 基于图神经网络的异构图表示学习和推荐算法研究
|
||||||
|
|
||||||
毕业设计:基于图神经网络的异构图表示学习和推荐算法研究。包含基于对比学习的关系感知异构图神经网络(Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning, RHCO)、基于图神经网络的学术推荐算法(Graph Neural Network based Academic Recommendation Algorithm, GARec),详细设计见md文件。
|
## 目录结构
|
||||||
|
|
||||||
|
```
|
||||||
|
GNN-Recommendation/
|
||||||
|
gnnrec/ 算法模块顶级包
|
||||||
|
hge/ 异构图表示学习模块
|
||||||
|
kgrec/ 基于图神经网络的推荐算法模块
|
||||||
|
data/ 数据集目录(已添加.gitignore)
|
||||||
|
model/ 模型保存目录(已添加.gitignore)
|
||||||
|
img/ 图片目录
|
||||||
|
academic_graph/ Django项目模块
|
||||||
|
rank/ Django应用
|
||||||
|
manage.py Django管理脚本
|
||||||
|
```
|
||||||
|
|
||||||
|
## 安装依赖
|
||||||
|
|
||||||
|
Python 3.7
|
||||||
|
|
||||||
|
### CUDA 11.0
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install -r requirements_cuda.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
### CPU
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install -r requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
## 异构图表示学习(附录)
|
||||||
|
|
||||||
|
基于对比学习的关系感知异构图神经网络(Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning, RHCO)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 实验
|
||||||
|
|
||||||
|
见 [readme](gnnrec/hge/readme.md)
|
||||||
|
|
||||||
|
## 基于图神经网络的推荐算法(附录)
|
||||||
|
|
||||||
|
基于图神经网络的学术推荐算法(Graph Neural Network based Academic Recommendation Algorithm, GARec)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 实验
|
||||||
|
|
||||||
|
见 [readme](gnnrec/kgrec/readme.md)
|
||||||
|
|
||||||
|
## Django 配置
|
||||||
|
|
||||||
|
### MySQL 数据库配置
|
||||||
|
|
||||||
|
1. 创建数据库及用户
|
||||||
|
|
||||||
|
```sql
|
||||||
|
CREATE DATABASE academic_graph CHARACTER SET utf8mb4;
|
||||||
|
CREATE USER 'academic_graph'@'%' IDENTIFIED BY 'password';
|
||||||
|
GRANT ALL ON academic_graph.* TO 'academic_graph'@'%';
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 在根目录下创建文件.mylogin.cnf
|
||||||
|
|
||||||
|
```ini
|
||||||
|
[client]
|
||||||
|
host = x.x.x.x
|
||||||
|
port = 3306
|
||||||
|
user = username
|
||||||
|
password = password
|
||||||
|
database = database
|
||||||
|
default-character-set = utf8mb4
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 创建数据库表
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python manage.py makemigrations --settings=academic_graph.settings.prod rank
|
||||||
|
python manage.py migrate --settings=academic_graph.settings.prod
|
||||||
|
```
|
||||||
|
|
||||||
|
4. 导入 oag-cs 数据集
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python manage.py loadoagcs --settings=academic_graph.settings.prod
|
||||||
|
```
|
||||||
|
|
||||||
|
注:由于导入一次时间很长(约 9 小时),为了避免中途发生错误,可以先用 data/oag/test 中的测试数据调试一下
|
||||||
|
|
||||||
|
### 拷贝静态文件
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python manage.py collectstatic --settings=academic_graph.settings.prod
|
||||||
|
```
|
||||||
|
|
||||||
|
### 启动 Web 服务器
|
||||||
|
|
||||||
|
```shell
|
||||||
|
export SECRET_KEY=xxx
|
||||||
|
python manage.py runserver --settings=academic_graph.settings.prod 0.0.0.0:8000
|
||||||
|
```
|
||||||
|
|
||||||
|
### 系统截图
|
||||||
|
|
||||||
|
搜索论文
|
||||||
|
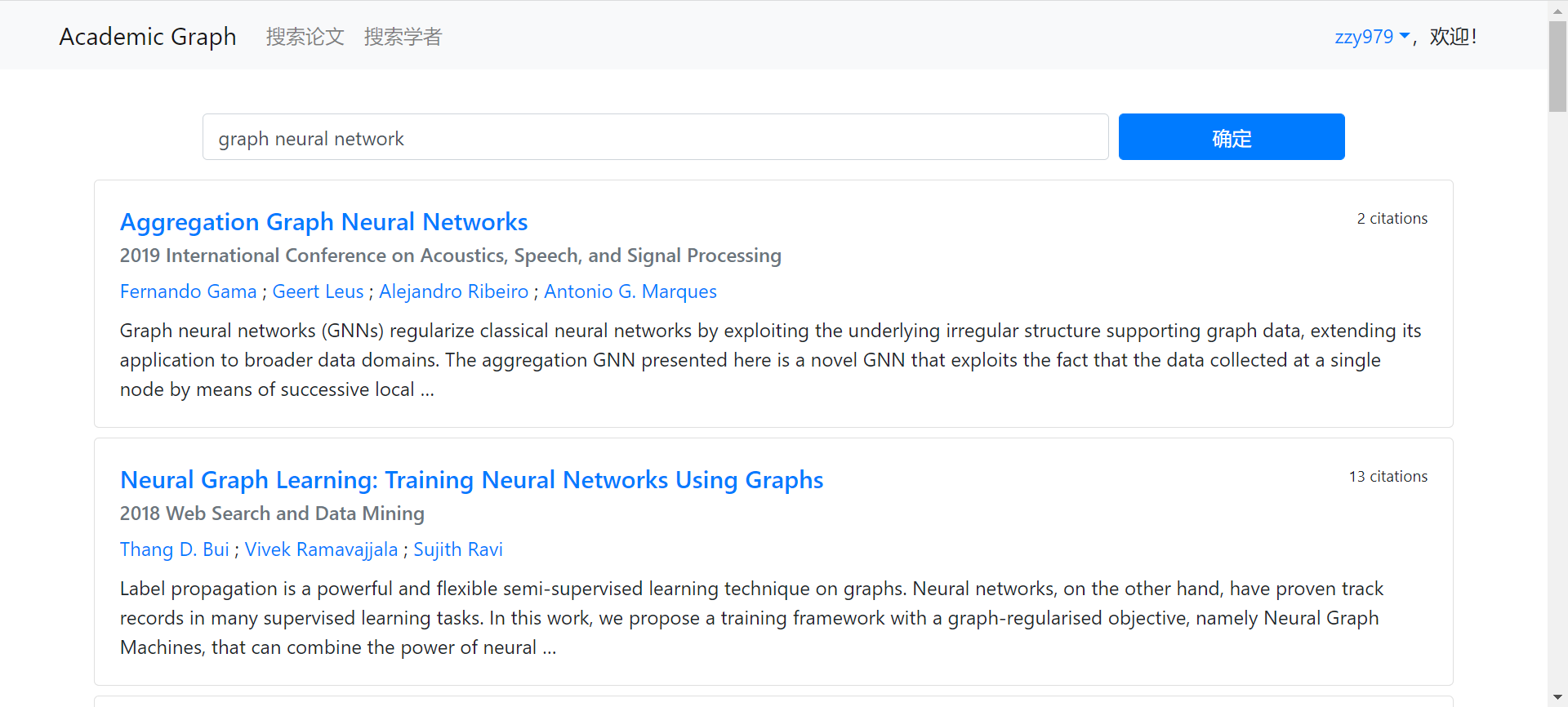
|
||||||
|
|
||||||
|
论文详情
|
||||||
|
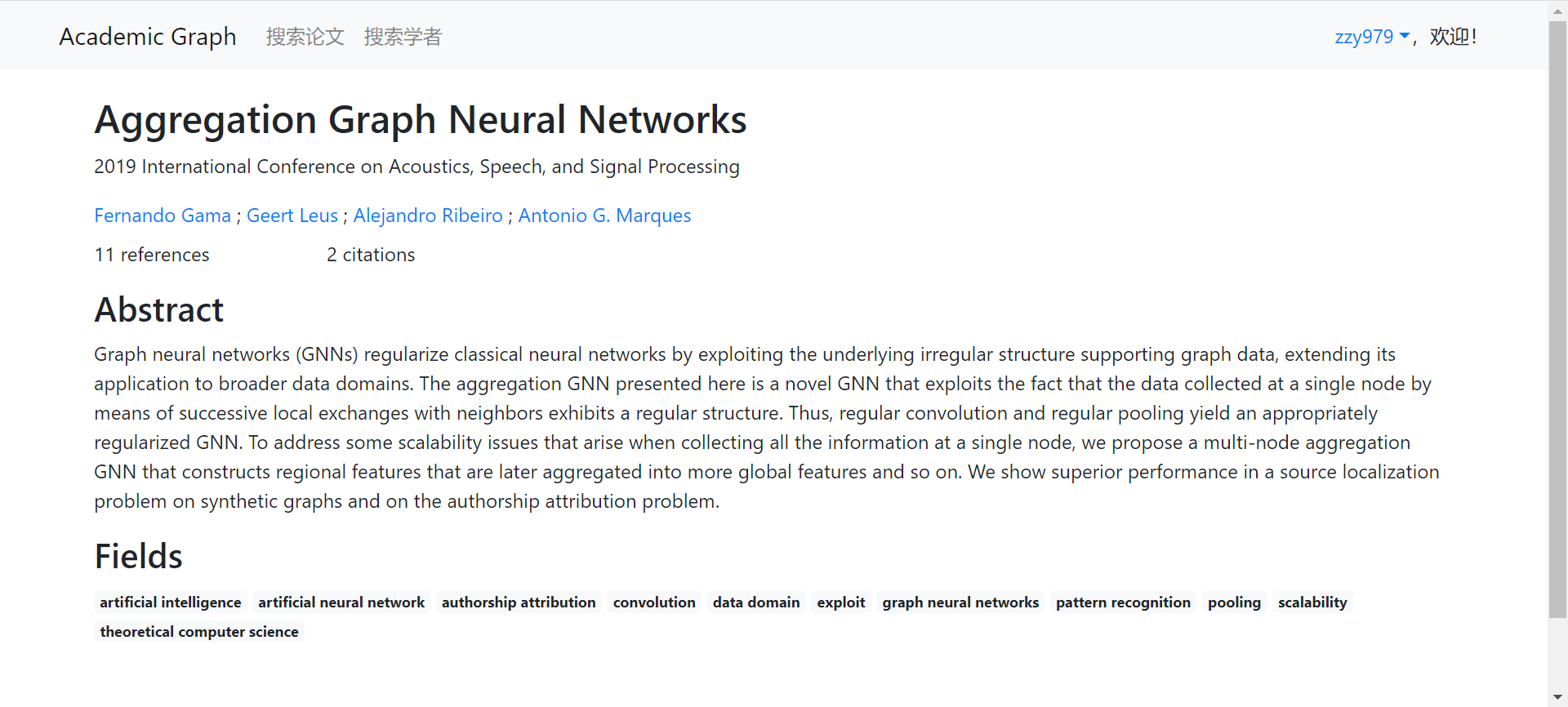
|
||||||
|
|
||||||
|
搜索学者
|
||||||
|

|
||||||
|
|
||||||
|
学者详情
|
||||||
|
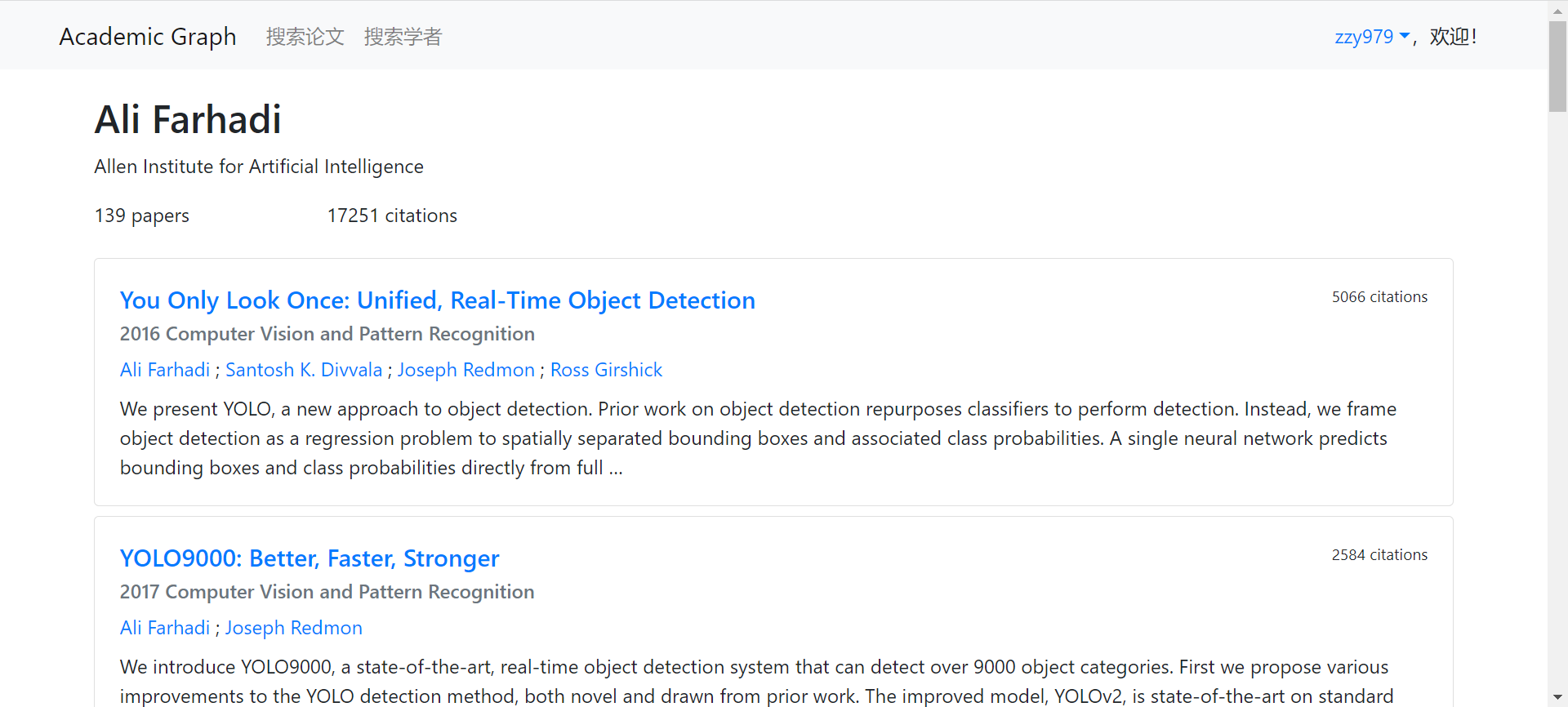
|
||||||
|
|
||||||
|
## 附录
|
||||||
|
|
||||||
|
### 基于图神经网络的推荐算法
|
||||||
|
|
||||||
|
#### 数据集
|
||||||
|
|
||||||
|
oag-cs - 使用 OAG 微软学术数据构造的计算机领域的学术网络(见 [readme](data/readme.md))
|
||||||
|
|
||||||
|
#### 预训练顶点嵌入
|
||||||
|
|
||||||
|
使用 metapath2vec(随机游走 +word2vec)预训练顶点嵌入,作为 GNN 模型的顶点输入特征
|
||||||
|
|
||||||
|
1. 随机游走
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.random_walk model/word2vec/oag_cs_corpus.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 训练词向量
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.metapath2vec.train_word2vec --size=128 --workers=8 model/word2vec/oag_cs_corpus.txt model/word2vec/oag_cs.model
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 召回
|
||||||
|
|
||||||
|
使用微调后的 SciBERT 模型(见 [readme](data/readme.md) 第 2 步)将查询词编码为向量,与预先计算好的论文标题向量计算余弦相似度,取 top k
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.recall
|
||||||
|
```
|
||||||
|
|
||||||
|
召回结果示例:
|
||||||
|
|
||||||
|
graph neural network
|
||||||
|
|
||||||
|
```
|
||||||
|
0.9629 Aggregation Graph Neural Networks
|
||||||
|
0.9579 Neural Graph Learning: Training Neural Networks Using Graphs
|
||||||
|
0.9556 Heterogeneous Graph Neural Network
|
||||||
|
0.9552 Neural Graph Machines: Learning Neural Networks Using Graphs
|
||||||
|
0.9490 On the choice of graph neural network architectures
|
||||||
|
0.9474 Measuring and Improving the Use of Graph Information in Graph Neural Networks
|
||||||
|
0.9362 Challenging the generalization capabilities of Graph Neural Networks for network modeling
|
||||||
|
0.9295 Strategies for Pre-training Graph Neural Networks
|
||||||
|
0.9142 Supervised Neural Network Models for Processing Graphs
|
||||||
|
0.9112 Geometrically Principled Connections in Graph Neural Networks
|
||||||
|
```
|
||||||
|
|
||||||
|
recommendation algorithm based on knowledge graph
|
||||||
|
|
||||||
|
```
|
||||||
|
0.9172 Research on Video Recommendation Algorithm Based on Knowledge Reasoning of Knowledge Graph
|
||||||
|
0.8972 An Improved Recommendation Algorithm in Knowledge Network
|
||||||
|
0.8558 A personalized recommendation algorithm based on interest graph
|
||||||
|
0.8431 An Improved Recommendation Algorithm Based on Graph Model
|
||||||
|
0.8334 The Research of Recommendation Algorithm based on Complete Tripartite Graph Model
|
||||||
|
0.8220 Recommendation Algorithm based on Link Prediction and Domain Knowledge in Retail Transactions
|
||||||
|
0.8167 Recommendation Algorithm Based on Graph-Model Considering User Background Information
|
||||||
|
0.8034 A Tripartite Graph Recommendation Algorithm Based on Item Information and User Preference
|
||||||
|
0.7774 Improvement of TF-IDF Algorithm Based on Knowledge Graph
|
||||||
|
0.7770 Graph Searching Algorithms for Semantic-Social Recommendation
|
||||||
|
```
|
||||||
|
|
||||||
|
scholar disambiguation
|
||||||
|
|
||||||
|
```
|
||||||
|
0.9690 Scholar search-oriented author disambiguation
|
||||||
|
0.9040 Author name disambiguation in scientific collaboration and mobility cases
|
||||||
|
0.8901 Exploring author name disambiguation on PubMed-scale
|
||||||
|
0.8852 Author Name Disambiguation in Heterogeneous Academic Networks
|
||||||
|
0.8797 KDD Cup 2013: author disambiguation
|
||||||
|
0.8796 A survey of author name disambiguation techniques: 2010–2016
|
||||||
|
0.8721 Who is Who: Name Disambiguation in Large-Scale Scientific Literature
|
||||||
|
0.8660 Use of ResearchGate and Google CSE for author name disambiguation
|
||||||
|
0.8643 Automatic Methods for Disambiguating Author Names in Bibliographic Data Repositories
|
||||||
|
0.8641 A brief survey of automatic methods for author name disambiguation
|
||||||
|
```
|
||||||
|
|
||||||
|
### 精排
|
||||||
|
|
||||||
|
#### 构造 ground truth
|
||||||
|
|
||||||
|
(1)验证集
|
||||||
|
|
||||||
|
从 AMiner 发布的 [AI 2000 人工智能全球最具影响力学者榜单](https://www.aminer.cn/ai2000) 抓取人工智能 20 个子领域的 top 100 学者
|
||||||
|
|
||||||
|
```shell
|
||||||
|
pip install scrapy>=2.3.0
|
||||||
|
cd gnnrec/kgrec/data/preprocess
|
||||||
|
scrapy runspider ai2000_crawler.py -a save_path=/home/zzy/GNN-Recommendation/data/rank/ai2000.json
|
||||||
|
```
|
||||||
|
|
||||||
|
与 oag-cs 数据集的学者匹配,并人工确认一些排名较高但未匹配上的学者,作为学者排名 ground truth 验证集
|
||||||
|
|
||||||
|
```shell
|
||||||
|
export DJANGO_SETTINGS_MODULE=academic_graph.settings.common
|
||||||
|
export SECRET_KEY=xxx
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.build_author_rank build-val
|
||||||
|
```
|
||||||
|
|
||||||
|
(2)训练集
|
||||||
|
|
||||||
|
参考 AI 2000 的计算公式,根据某个领域的论文引用数加权求和构造学者排名,作为 ground truth 训练集
|
||||||
|
|
||||||
|
计算公式:
|
||||||
|
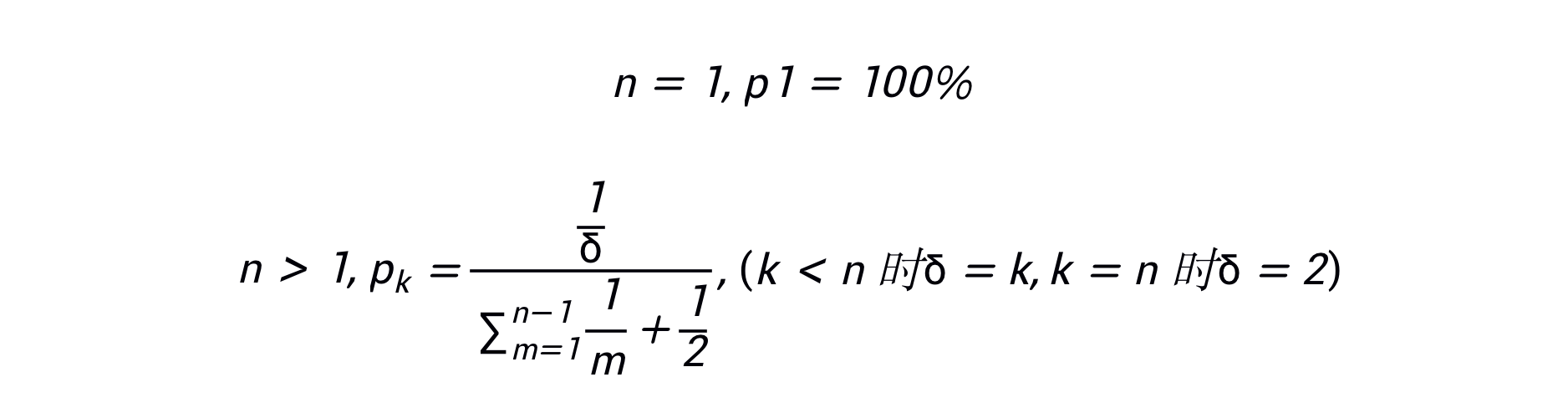
|
||||||
|
即:假设一篇论文有 n 个作者,第 k 作者的权重为 1/k,最后一个视为通讯作者,权重为 1/2,归一化之后计算论文引用数的加权求和
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.build_author_rank build-train
|
||||||
|
```
|
||||||
|
|
||||||
|
(3)评估 ground truth 训练集的质量
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.build_author_rank eval
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
nDGC@100=0.2420 Precision@100=0.1859 Recall@100=0.2016
|
||||||
|
nDGC@50=0.2308 Precision@50=0.2494 Recall@50=0.1351
|
||||||
|
nDGC@20=0.2492 Precision@20=0.3118 Recall@20=0.0678
|
||||||
|
nDGC@10=0.2743 Precision@10=0.3471 Recall@10=0.0376
|
||||||
|
nDGC@5=0.3165 Precision@5=0.3765 Recall@5=0.0203
|
||||||
|
```
|
||||||
|
|
||||||
|
(4)采样三元组
|
||||||
|
|
||||||
|
从学者排名训练集中采样三元组(t, ap, an),表示对于领域 t,学者 ap 的排名在 an 之前
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.build_author_rank sample
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 训练 GNN 模型
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.train model/word2vec/oag-cs.model model/garec_gnn.pt data/rank/author_embed.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
## 异构图表示学习
|
||||||
|
|
||||||
|
### 数据集
|
||||||
|
|
||||||
|
* [ACM](https://github.com/liun-online/HeCo/tree/main/data/acm) - ACM 学术网络数据集
|
||||||
|
* [DBLP](https://github.com/liun-online/HeCo/tree/main/data/dblp) - DBLP 学术网络数据集
|
||||||
|
* [ogbn-mag](https://ogb.stanford.edu/docs/nodeprop/#ogbn-mag) - OGB 提供的微软学术数据集
|
||||||
|
* [oag-venue](../kgrec/data/venue.py) - oag-cs 期刊分类数据集
|
||||||
|
|
||||||
|
| 数据集 | 顶点数 | 边数 | 目标顶点 | 类别数 |
|
||||||
|
| --------- | ------- | -------- | -------- | ------ |
|
||||||
|
| ACM | 11246 | 34852 | paper | 3 |
|
||||||
|
| DBLP | 26128 | 239566 | author | 4 |
|
||||||
|
| ogbn-mag | 1939743 | 21111007 | paper | 349 |
|
||||||
|
| oag-venue | 4235169 | 34520417 | paper | 360 |
|
||||||
|
|
||||||
|
### Baselines
|
||||||
|
|
||||||
|
* [R-GCN](https://arxiv.org/pdf/1703.06103)
|
||||||
|
* [HGT](https://arxiv.org/pdf/2003.01332)
|
||||||
|
* [HGConv](https://arxiv.org/pdf/2012.14722)
|
||||||
|
* [R-HGNN](https://arxiv.org/pdf/2105.11122)
|
||||||
|
* [C&S](https://arxiv.org/pdf/2010.13993)
|
||||||
|
* [HeCo](https://arxiv.org/pdf/2105.09111)
|
||||||
|
|
||||||
|
#### R-GCN (full batch)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.rgcn.train --dataset=acm --epochs=10
|
||||||
|
python -m gnnrec.hge.rgcn.train --dataset=dblp --epochs=10
|
||||||
|
python -m gnnrec.hge.rgcn.train --dataset=ogbn-mag --num-hidden=48
|
||||||
|
python -m gnnrec.hge.rgcn.train --dataset=oag-venue --num-hidden=48 --epochs=30
|
||||||
|
```
|
||||||
|
|
||||||
|
(使用 minibatch 训练准确率就是只有 20% 多,不知道为什么)
|
||||||
|
|
||||||
|
#### 预训练顶点嵌入
|
||||||
|
|
||||||
|
使用 metapath2vec(随机游走 +word2vec)预训练顶点嵌入,作为 GNN 模型的顶点输入特征
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.metapath2vec.random_walk model/word2vec/ogbn-mag_corpus.txt
|
||||||
|
python -m gnnrec.hge.metapath2vec.train_word2vec --size=128 --workers=8 model/word2vec/ogbn-mag_corpus.txt model/word2vec/ogbn-mag.model
|
||||||
|
```
|
||||||
|
|
||||||
|
#### HGT
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train_full --dataset=acm
|
||||||
|
python -m gnnrec.hge.hgt.train_full --dataset=dblp
|
||||||
|
python -m gnnrec.hge.hgt.train --dataset=ogbn-mag --node-embed-path=model/word2vec/ogbn-mag.model --epochs=40
|
||||||
|
python -m gnnrec.hge.hgt.train --dataset=oag-venue --node-embed-path=model/word2vec/oag-cs.model --epochs=40
|
||||||
|
```
|
||||||
|
|
||||||
|
#### HGConv
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgconv.train_full --dataset=acm --epochs=5
|
||||||
|
python -m gnnrec.hge.hgconv.train_full --dataset=dblp --epochs=20
|
||||||
|
python -m gnnrec.hge.hgconv.train --dataset=ogbn-mag --node-embed-path=model/word2vec/ogbn-mag.model
|
||||||
|
python -m gnnrec.hge.hgconv.train --dataset=oag-venue --node-embed-path=model/word2vec/oag-cs.model
|
||||||
|
```
|
||||||
|
|
||||||
|
#### R-HGNN
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.rhgnn.train_full --dataset=acm --num-layers=1 --epochs=15
|
||||||
|
python -m gnnrec.hge.rhgnn.train_full --dataset=dblp --epochs=20
|
||||||
|
python -m gnnrec.hge.rhgnn.train --dataset=ogbn-mag model/word2vec/ogbn-mag.model
|
||||||
|
python -m gnnrec.hge.rhgnn.train --dataset=oag-venue --epochs=50 model/word2vec/oag-cs.model
|
||||||
|
```
|
||||||
|
|
||||||
|
#### C&S
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.cs.train --dataset=acm --epochs=5
|
||||||
|
python -m gnnrec.hge.cs.train --dataset=dblp --epochs=5
|
||||||
|
python -m gnnrec.hge.cs.train --dataset=ogbn-mag --prop-graph=data/graph/pos_graph_ogbn-mag_t5.bin
|
||||||
|
python -m gnnrec.hge.cs.train --dataset=oag-venue --prop-graph=data/graph/pos_graph_oag-venue_t5.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
#### HeCo
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.heco.train --dataset=ogbn-mag model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5.bin
|
||||||
|
python -m gnnrec.hge.heco.train --dataset=oag-venue model/word2vec/oag-cs.model data/graph/pos_graph_oag-venue_t5.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
(ACM 和 DBLP 的数据来自 [https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/heco](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/heco) ,准确率和 Micro-F1 相等)
|
||||||
|
|
||||||
|
#### RHCO
|
||||||
|
|
||||||
|
基于对比学习的关系感知异构图神经网络(Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning, RHCO)
|
||||||
|
|
||||||
|
在 HeCo 的基础上改进:
|
||||||
|
|
||||||
|
* 网络结构编码器中的注意力向量改为关系的表示(类似于 R-HGNN)
|
||||||
|
* 正样本选择方式由元路径条数改为预训练的 HGT 计算的注意力权重、训练集使用真实标签
|
||||||
|
* 元路径视图编码器改为正样本图编码器,适配 mini-batch 训练
|
||||||
|
* Loss 增加分类损失,训练方式由无监督改为半监督
|
||||||
|
* 在最后增加 C&S 后处理步骤
|
||||||
|
|
||||||
|
ACM
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train_full --dataset=acm --save-path=model/hgt/hgt_acm.pt
|
||||||
|
python -m gnnrec.hge.rhco.build_pos_graph_full --dataset=acm --num-samples=5 --use-label model/hgt/hgt_acm.pt data/graph/pos_graph_acm_t5l.bin
|
||||||
|
python -m gnnrec.hge.rhco.train_full --dataset=acm data/graph/pos_graph_acm_t5l.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
DBLP
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train_full --dataset=dblp --save-path=model/hgt/hgt_dblp.pt
|
||||||
|
python -m gnnrec.hge.rhco.build_pos_graph_full --dataset=dblp --num-samples=5 --use-label model/hgt/hgt_dblp.pt data/graph/pos_graph_dblp_t5l.bin
|
||||||
|
python -m gnnrec.hge.rhco.train_full --dataset=dblp --use-data-pos data/graph/pos_graph_dblp_t5l.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
ogbn-mag(第 3 步如果中断可使用--load-path 参数继续训练)
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train --dataset=ogbn-mag --node-embed-path=model/word2vec/ogbn-mag.model --epochs=40 --save-path=model/hgt/hgt_ogbn-mag.pt
|
||||||
|
python -m gnnrec.hge.rhco.build_pos_graph --dataset=ogbn-mag --num-samples=5 --use-label model/word2vec/ogbn-mag.model model/hgt/hgt_ogbn-mag.pt data/graph/pos_graph_ogbn-mag_t5l.bin
|
||||||
|
python -m gnnrec.hge.rhco.train --dataset=ogbn-mag --num-hidden=64 --contrast-weight=0.9 model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5l.bin model/rhco_ogbn-mag_d64_a0.9_t5l.pt
|
||||||
|
python -m gnnrec.hge.rhco.smooth --dataset=ogbn-mag model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5l.bin model/rhco_ogbn-mag_d64_a0.9_t5l.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
oag-venue
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train --dataset=oag-venue --node-embed-path=model/word2vec/oag-cs.model --epochs=40 --save-path=model/hgt/hgt_oag-venue.pt
|
||||||
|
python -m gnnrec.hge.rhco.build_pos_graph --dataset=oag-venue --num-samples=5 --use-label model/word2vec/oag-cs.model model/hgt/hgt_oag-venue.pt data/graph/pos_graph_oag-venue_t5l.bin
|
||||||
|
python -m gnnrec.hge.rhco.train --dataset=oag-venue --num-hidden=64 --contrast-weight=0.9 model/word2vec/oag-cs.model data/graph/pos_graph_oag-venue_t5l.bin model/rhco_oag-venue.pt
|
||||||
|
python -m gnnrec.hge.rhco.smooth --dataset=oag-venue model/word2vec/oag-cs.model data/graph/pos_graph_oag-venue_t5l.bin model/rhco_oag-venue.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
消融实验
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.rhco.train --dataset=ogbn-mag --model=RHCO_sc model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5l.bin model/rhco_sc_ogbn-mag.pt
|
||||||
|
python -m gnnrec.hge.rhco.train --dataset=ogbn-mag --model=RHCO_pg model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5l.bin model/rhco_pg_ogbn-mag.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
### 实验结果
|
||||||
|
|
||||||
|
[顶点分类](gnnrec/hge/result/node_classification.csv)
|
||||||
|
|
||||||
|
[参数敏感性分析](gnnrec/hge/result/param_analysis.csv)
|
||||||
|
|
||||||
|
[消融实验](gnnrec/hge/result/ablation_study.csv)
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,16 @@
|
||||||
|
"""
|
||||||
|
ASGI config for academic_graph project.
|
||||||
|
|
||||||
|
It exposes the ASGI callable as a module-level variable named ``application``.
|
||||||
|
|
||||||
|
For more information on this file, see
|
||||||
|
https://docs.djangoproject.com/en/3.2/howto/deployment/asgi/
|
||||||
|
"""
|
||||||
|
|
||||||
|
import os
|
||||||
|
|
||||||
|
from django.core.asgi import get_asgi_application
|
||||||
|
|
||||||
|
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'academic_graph.settings')
|
||||||
|
|
||||||
|
application = get_asgi_application()
|
||||||
|
|
@ -0,0 +1,136 @@
|
||||||
|
"""
|
||||||
|
Django settings for academic_graph project.
|
||||||
|
|
||||||
|
Generated by 'django-admin startproject' using Django 3.2.8.
|
||||||
|
|
||||||
|
For more information on this file, see
|
||||||
|
https://docs.djangoproject.com/en/3.2/topics/settings/
|
||||||
|
|
||||||
|
For the full list of settings and their values, see
|
||||||
|
https://docs.djangoproject.com/en/3.2/ref/settings/
|
||||||
|
"""
|
||||||
|
import os
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
# Build paths inside the project like this: BASE_DIR / 'subdir'.
|
||||||
|
BASE_DIR = Path(__file__).resolve().parent.parent.parent
|
||||||
|
|
||||||
|
|
||||||
|
# Quick-start development settings - unsuitable for production
|
||||||
|
# See https://docs.djangoproject.com/en/3.2/howto/deployment/checklist/
|
||||||
|
|
||||||
|
# SECURITY WARNING: keep the secret key used in production secret!
|
||||||
|
SECRET_KEY = os.environ['SECRET_KEY']
|
||||||
|
|
||||||
|
# SECURITY WARNING: don't run with debug turned on in production!
|
||||||
|
DEBUG = False
|
||||||
|
|
||||||
|
ALLOWED_HOSTS = ['localhost', '127.0.0.1', '[::1]', '10.2.4.100']
|
||||||
|
|
||||||
|
|
||||||
|
# Application definition
|
||||||
|
|
||||||
|
INSTALLED_APPS = [
|
||||||
|
'django.contrib.admin',
|
||||||
|
'django.contrib.auth',
|
||||||
|
'django.contrib.contenttypes',
|
||||||
|
'django.contrib.sessions',
|
||||||
|
'django.contrib.messages',
|
||||||
|
'django.contrib.staticfiles',
|
||||||
|
'rank',
|
||||||
|
]
|
||||||
|
|
||||||
|
MIDDLEWARE = [
|
||||||
|
'django.middleware.security.SecurityMiddleware',
|
||||||
|
'django.contrib.sessions.middleware.SessionMiddleware',
|
||||||
|
'django.middleware.common.CommonMiddleware',
|
||||||
|
'django.middleware.csrf.CsrfViewMiddleware',
|
||||||
|
'django.contrib.auth.middleware.AuthenticationMiddleware',
|
||||||
|
'django.contrib.messages.middleware.MessageMiddleware',
|
||||||
|
'django.middleware.clickjacking.XFrameOptionsMiddleware',
|
||||||
|
]
|
||||||
|
|
||||||
|
ROOT_URLCONF = 'academic_graph.urls'
|
||||||
|
|
||||||
|
TEMPLATES = [
|
||||||
|
{
|
||||||
|
'BACKEND': 'django.template.backends.django.DjangoTemplates',
|
||||||
|
'DIRS': [],
|
||||||
|
'APP_DIRS': True,
|
||||||
|
'OPTIONS': {
|
||||||
|
'context_processors': [
|
||||||
|
'django.template.context_processors.debug',
|
||||||
|
'django.template.context_processors.request',
|
||||||
|
'django.contrib.auth.context_processors.auth',
|
||||||
|
'django.contrib.messages.context_processors.messages',
|
||||||
|
],
|
||||||
|
},
|
||||||
|
},
|
||||||
|
]
|
||||||
|
|
||||||
|
WSGI_APPLICATION = 'academic_graph.wsgi.application'
|
||||||
|
|
||||||
|
|
||||||
|
# Database
|
||||||
|
# https://docs.djangoproject.com/en/3.2/ref/settings/#databases
|
||||||
|
|
||||||
|
DATABASES = {
|
||||||
|
'default': {
|
||||||
|
'ENGINE': 'django.db.backends.mysql',
|
||||||
|
'OPTIONS': {
|
||||||
|
'read_default_file': '.mylogin.cnf',
|
||||||
|
'charset': 'utf8mb4',
|
||||||
|
},
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
# Password validation
|
||||||
|
# https://docs.djangoproject.com/en/3.2/ref/settings/#auth-password-validators
|
||||||
|
|
||||||
|
AUTH_PASSWORD_VALIDATORS = [
|
||||||
|
{
|
||||||
|
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
|
||||||
|
},
|
||||||
|
{
|
||||||
|
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
|
||||||
|
},
|
||||||
|
{
|
||||||
|
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
|
||||||
|
},
|
||||||
|
{
|
||||||
|
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
|
||||||
|
},
|
||||||
|
]
|
||||||
|
|
||||||
|
|
||||||
|
# Internationalization
|
||||||
|
# https://docs.djangoproject.com/en/3.2/topics/i18n/
|
||||||
|
|
||||||
|
LANGUAGE_CODE = 'zh-hans'
|
||||||
|
|
||||||
|
TIME_ZONE = 'Asia/Shanghai'
|
||||||
|
|
||||||
|
USE_I18N = True
|
||||||
|
|
||||||
|
USE_L10N = True
|
||||||
|
|
||||||
|
USE_TZ = True
|
||||||
|
|
||||||
|
|
||||||
|
# Static files (CSS, JavaScript, Images)
|
||||||
|
# https://docs.djangoproject.com/en/3.2/howto/static-files/
|
||||||
|
|
||||||
|
STATIC_URL = '/static/'
|
||||||
|
STATIC_ROOT = BASE_DIR / 'static'
|
||||||
|
|
||||||
|
# Default primary key field type
|
||||||
|
# https://docs.djangoproject.com/en/3.2/ref/settings/#default-auto-field
|
||||||
|
|
||||||
|
DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'
|
||||||
|
|
||||||
|
LOGIN_URL = 'rank:login'
|
||||||
|
|
||||||
|
# 自定义设置
|
||||||
|
PAGE_SIZE = 20
|
||||||
|
TESTING = True
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
from .common import * # noqa
|
||||||
|
|
||||||
|
DEBUG = True
|
||||||
|
|
||||||
|
# 自定义设置
|
||||||
|
TESTING = False
|
||||||
|
|
@ -0,0 +1,6 @@
|
||||||
|
from .common import * # noqa
|
||||||
|
|
||||||
|
DEBUG = False
|
||||||
|
|
||||||
|
# 自定义设置
|
||||||
|
TESTING = False
|
||||||
|
|
@ -0,0 +1,11 @@
|
||||||
|
from .common import * # noqa
|
||||||
|
|
||||||
|
DATABASES = {
|
||||||
|
'default': {
|
||||||
|
'ENGINE': 'django.db.backends.sqlite3',
|
||||||
|
'NAME': BASE_DIR / 'test.sqlite3',
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
# 自定义设置
|
||||||
|
TESTING = True
|
||||||
|
|
@ -0,0 +1,25 @@
|
||||||
|
"""academic_graph URL Configuration
|
||||||
|
|
||||||
|
The `urlpatterns` list routes URLs to views. For more information please see:
|
||||||
|
https://docs.djangoproject.com/en/3.2/topics/http/urls/
|
||||||
|
Examples:
|
||||||
|
Function views
|
||||||
|
1. Add an import: from my_app import views
|
||||||
|
2. Add a URL to urlpatterns: path('', views.home, name='home')
|
||||||
|
Class-based views
|
||||||
|
1. Add an import: from other_app.views import Home
|
||||||
|
2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')
|
||||||
|
Including another URLconf
|
||||||
|
1. Import the include() function: from django.urls import include, path
|
||||||
|
2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))
|
||||||
|
"""
|
||||||
|
from django.conf import settings
|
||||||
|
from django.contrib import admin
|
||||||
|
from django.urls import path, include
|
||||||
|
from django.views import static
|
||||||
|
|
||||||
|
urlpatterns = [
|
||||||
|
path('admin/', admin.site.urls),
|
||||||
|
path('static/<path:path>', static.serve, {'document_root': settings.STATIC_ROOT}, name='static'),
|
||||||
|
path('rank/', include('rank.urls')),
|
||||||
|
]
|
||||||
|
|
@ -0,0 +1,16 @@
|
||||||
|
"""
|
||||||
|
WSGI config for academic_graph project.
|
||||||
|
|
||||||
|
It exposes the WSGI callable as a module-level variable named ``application``.
|
||||||
|
|
||||||
|
For more information on this file, see
|
||||||
|
https://docs.djangoproject.com/en/3.2/howto/deployment/wsgi/
|
||||||
|
"""
|
||||||
|
|
||||||
|
import os
|
||||||
|
|
||||||
|
from django.core.wsgi import get_wsgi_application
|
||||||
|
|
||||||
|
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'academic_graph.settings')
|
||||||
|
|
||||||
|
application = get_wsgi_application()
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
# 项目根目录
|
||||||
|
BASE_DIR = Path(__file__).resolve().parent.parent
|
||||||
|
|
||||||
|
# 数据集目录
|
||||||
|
DATA_DIR = BASE_DIR / 'data'
|
||||||
|
|
||||||
|
# 模型保存目录
|
||||||
|
MODEL_DIR = BASE_DIR / 'model'
|
||||||
|
|
@ -0,0 +1,113 @@
|
||||||
|
import dgl.function as fn
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
|
||||||
|
|
||||||
|
class LabelPropagation(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, num_layers, alpha, norm):
|
||||||
|
"""标签传播模型
|
||||||
|
|
||||||
|
.. math::
|
||||||
|
Y^{(t+1)} = \\alpha SY^{(t)} + (1-\\alpha)Y, Y^{(0)} = Y
|
||||||
|
|
||||||
|
:param num_layers: int 传播层数
|
||||||
|
:param alpha: float α参数
|
||||||
|
:param norm: str 邻接矩阵归一化方式
|
||||||
|
'left': S=D^{-1}A, 'right': S=AD^{-1}, 'both': S=D^{-1/2}AD^{-1/2}
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.num_layers = num_layers
|
||||||
|
self.alpha = alpha
|
||||||
|
self.norm = norm
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def forward(self, g, labels, mask=None, post_step=None):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 无向图
|
||||||
|
:param labels: tensor(N, C) one-hot标签
|
||||||
|
:param mask: tensor(N), optional 有标签顶点mask
|
||||||
|
:param post_step: callable, optional f: tensor(N, C) -> tensor(N, C)
|
||||||
|
:return: tensor(N, C) 预测标签概率
|
||||||
|
"""
|
||||||
|
with g.local_scope():
|
||||||
|
if mask is not None:
|
||||||
|
y = torch.zeros_like(labels)
|
||||||
|
y[mask] = labels[mask]
|
||||||
|
else:
|
||||||
|
y = labels
|
||||||
|
|
||||||
|
residual = (1 - self.alpha) * y
|
||||||
|
degs = g.in_degrees().float().clamp(min=1)
|
||||||
|
norm = torch.pow(degs, -0.5 if self.norm == 'both' else -1).unsqueeze(1) # (N, 1)
|
||||||
|
for _ in range(self.num_layers):
|
||||||
|
if self.norm in ('both', 'right'):
|
||||||
|
y *= norm
|
||||||
|
g.ndata['h'] = y
|
||||||
|
g.update_all(fn.copy_u('h', 'm'), fn.sum('m', 'h'))
|
||||||
|
y = self.alpha * g.ndata.pop('h')
|
||||||
|
if self.norm in ('both', 'left'):
|
||||||
|
y *= norm
|
||||||
|
y += residual
|
||||||
|
if post_step is not None:
|
||||||
|
y = post_step(y)
|
||||||
|
return y
|
||||||
|
|
||||||
|
|
||||||
|
class CorrectAndSmooth(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, num_correct_layers, correct_alpha, correct_norm,
|
||||||
|
num_smooth_layers, smooth_alpha, smooth_norm, scale=1.0):
|
||||||
|
"""C&S模型"""
|
||||||
|
super().__init__()
|
||||||
|
self.correct_prop = LabelPropagation(num_correct_layers, correct_alpha, correct_norm)
|
||||||
|
self.smooth_prop = LabelPropagation(num_smooth_layers, smooth_alpha, smooth_norm)
|
||||||
|
self.scale = scale
|
||||||
|
|
||||||
|
def correct(self, g, labels, base_pred, mask):
|
||||||
|
"""Correct步,修正基础预测中的误差
|
||||||
|
|
||||||
|
:param g: DGLGraph 无向图
|
||||||
|
:param labels: tensor(N, C) one-hot标签
|
||||||
|
:param base_pred: tensor(N, C) 基础预测
|
||||||
|
:param mask: tensor(N) 训练集mask
|
||||||
|
:return: tensor(N, C) 修正后的预测
|
||||||
|
"""
|
||||||
|
err = torch.zeros_like(base_pred) # (N, C)
|
||||||
|
err[mask] = labels[mask] - base_pred[mask]
|
||||||
|
|
||||||
|
# FDiff-scale: 对训练集固定误差
|
||||||
|
def fix_input(y):
|
||||||
|
y[mask] = err[mask]
|
||||||
|
return y
|
||||||
|
|
||||||
|
smoothed_err = self.correct_prop(g, err, post_step=fix_input) # \hat{E}
|
||||||
|
corrected_pred = base_pred + self.scale * smoothed_err # Z^{(r)}
|
||||||
|
corrected_pred[corrected_pred.isnan()] = base_pred[corrected_pred.isnan()]
|
||||||
|
return corrected_pred
|
||||||
|
|
||||||
|
def smooth(self, g, labels, corrected_pred, mask):
|
||||||
|
"""Smooth步,平滑最终预测
|
||||||
|
|
||||||
|
:param g: DGLGraph 无向图
|
||||||
|
:param labels: tensor(N, C) one-hot标签
|
||||||
|
:param corrected_pred: tensor(N, C) 修正后的预测
|
||||||
|
:param mask: tensor(N) 训练集mask
|
||||||
|
:return: tensor(N, C) 最终预测
|
||||||
|
"""
|
||||||
|
guess = corrected_pred
|
||||||
|
guess[mask] = labels[mask]
|
||||||
|
return self.smooth_prop(g, guess)
|
||||||
|
|
||||||
|
def forward(self, g, labels, base_pred, mask):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 无向图
|
||||||
|
:param labels: tensor(N, C) one-hot标签
|
||||||
|
:param base_pred: tensor(N, C) 基础预测
|
||||||
|
:param mask: tensor(N) 训练集mask
|
||||||
|
:return: tensor(N, C) 最终预测
|
||||||
|
"""
|
||||||
|
# corrected_pred = self.correct(g, labels, base_pred, mask)
|
||||||
|
corrected_pred = base_pred
|
||||||
|
return self.smooth(g, labels, corrected_pred, mask)
|
||||||
|
|
@ -0,0 +1,101 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
|
||||||
|
from gnnrec.hge.cs.model import CorrectAndSmooth
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, calc_metrics, METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train_base_model(base_model, feats, labels, train_idx, val_idx, test_idx, evaluator, args):
|
||||||
|
print('Training base model...')
|
||||||
|
optimizer = optim.Adam(base_model.parameters(), lr=args.lr)
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
base_model.train()
|
||||||
|
logits = base_model(feats)
|
||||||
|
loss = F.cross_entropy(logits[train_idx], labels[train_idx])
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
print(('Epoch {:d} | Loss {:.4f} | ' + METRICS_STR).format(
|
||||||
|
epoch, loss.item(),
|
||||||
|
*evaluate(base_model, feats, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
))
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def evaluate(model, feats, labels, train_idx, val_idx, test_idx, evaluator):
|
||||||
|
model.eval()
|
||||||
|
logits = model(feats)
|
||||||
|
return calc_metrics(logits, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
|
||||||
|
|
||||||
|
def correct_and_smooth(base_model, g, feats, labels, train_idx, val_idx, test_idx, evaluator, args):
|
||||||
|
print('Training C&S...')
|
||||||
|
base_model.eval()
|
||||||
|
base_pred = base_model(feats).softmax(dim=1) # 注意要softmax
|
||||||
|
|
||||||
|
cs = CorrectAndSmooth(
|
||||||
|
args.num_correct_layers, args.correct_alpha, args.correct_norm,
|
||||||
|
args.num_smooth_layers, args.smooth_alpha, args.smooth_norm, args.scale
|
||||||
|
)
|
||||||
|
mask = torch.cat([train_idx, val_idx])
|
||||||
|
logits = cs(g, F.one_hot(labels).float(), base_pred, mask)
|
||||||
|
_, _, test_acc, _, _, test_f1 = calc_metrics(logits, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
print('Test Acc {:.4f} | Test Macro-F1 {:.4f}'.format(test_acc, test_f1))
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, _, feat, labels, _, train_idx, val_idx, test_idx, evaluator = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
feat = (feat - feat.mean(dim=0)) / feat.std(dim=0)
|
||||||
|
# 标签传播图
|
||||||
|
if args.dataset in ('acm', 'dblp'):
|
||||||
|
pos_v, pos_u = data.pos
|
||||||
|
pg = dgl.graph((pos_u, pos_v), device=device)
|
||||||
|
else:
|
||||||
|
pg = dgl.load_graphs(args.prop_graph)[0][-1].to(device)
|
||||||
|
|
||||||
|
if args.dataset == 'oag-venue':
|
||||||
|
labels[labels == -1] = 0
|
||||||
|
|
||||||
|
base_model = nn.Linear(feat.shape[1], data.num_classes).to(device)
|
||||||
|
train_base_model(base_model, feat, labels, train_idx, val_idx, test_idx, evaluator, args)
|
||||||
|
correct_and_smooth(base_model, pg, feat, labels, train_idx, val_idx, test_idx, evaluator, args)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练C&S模型')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['acm', 'dblp', 'ogbn-mag', 'oag-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
# 基础模型
|
||||||
|
parser.add_argument('--epochs', type=int, default=300, help='基础模型训练epoch数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.01, help='基础模型学习率')
|
||||||
|
# C&S
|
||||||
|
parser.add_argument('--prop-graph', help='标签传播图所在路径')
|
||||||
|
parser.add_argument('--num-correct-layers', type=int, default=50, help='Correct步骤传播层数')
|
||||||
|
parser.add_argument('--correct-alpha', type=float, default=0.5, help='Correct步骤α值')
|
||||||
|
parser.add_argument(
|
||||||
|
'--correct-norm', choices=['left', 'right', 'both'], default='both',
|
||||||
|
help='Correct步骤归一化方式'
|
||||||
|
)
|
||||||
|
parser.add_argument('--num-smooth-layers', type=int, default=50, help='Smooth步骤传播层数')
|
||||||
|
parser.add_argument('--smooth-alpha', type=float, default=0.5, help='Smooth步骤α值')
|
||||||
|
parser.add_argument(
|
||||||
|
'--smooth-norm', choices=['left', 'right', 'both'], default='both',
|
||||||
|
help='Smooth步骤归一化方式'
|
||||||
|
)
|
||||||
|
parser.add_argument('--scale', type=float, default=20, help='放缩系数')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
from .heco import ACMDataset, DBLPDataset
|
||||||
|
|
@ -0,0 +1,204 @@
|
||||||
|
import os
|
||||||
|
import shutil
|
||||||
|
import zipfile
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import numpy as np
|
||||||
|
import pandas as pd
|
||||||
|
import scipy.sparse as sp
|
||||||
|
import torch
|
||||||
|
from dgl.data import DGLDataset
|
||||||
|
from dgl.data.utils import download, save_graphs, save_info, load_graphs, load_info, \
|
||||||
|
generate_mask_tensor, idx2mask
|
||||||
|
|
||||||
|
|
||||||
|
class HeCoDataset(DGLDataset):
|
||||||
|
"""HeCo模型使用的数据集基类
|
||||||
|
|
||||||
|
论文链接:https://arxiv.org/pdf/2105.09111
|
||||||
|
|
||||||
|
类属性
|
||||||
|
-----
|
||||||
|
* num_classes: 类别数
|
||||||
|
* metapaths: 使用的元路径
|
||||||
|
* predict_ntype: 目标顶点类型
|
||||||
|
* pos: (tensor(E_pos), tensor(E_pos)) 目标顶点正样本对,pos[1][i]是pos[0][i]的正样本
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, name, ntypes):
|
||||||
|
url = 'https://api.github.com/repos/liun-online/HeCo/zipball/main'
|
||||||
|
self._ntypes = {ntype[0]: ntype for ntype in ntypes}
|
||||||
|
super().__init__(name + '-heco', url)
|
||||||
|
|
||||||
|
def download(self):
|
||||||
|
file_path = os.path.join(self.raw_dir, 'HeCo-main.zip')
|
||||||
|
if not os.path.exists(file_path):
|
||||||
|
download(self.url, path=file_path)
|
||||||
|
with zipfile.ZipFile(file_path, 'r') as f:
|
||||||
|
f.extractall(self.raw_dir)
|
||||||
|
shutil.copytree(
|
||||||
|
os.path.join(self.raw_dir, 'HeCo-main', 'data', self.name.split('-')[0]),
|
||||||
|
os.path.join(self.raw_path)
|
||||||
|
)
|
||||||
|
|
||||||
|
def save(self):
|
||||||
|
save_graphs(os.path.join(self.save_path, self.name + '_dgl_graph.bin'), [self.g])
|
||||||
|
save_info(os.path.join(self.raw_path, self.name + '_pos.pkl'), {'pos_i': self.pos_i, 'pos_j': self.pos_j})
|
||||||
|
|
||||||
|
def load(self):
|
||||||
|
graphs, _ = load_graphs(os.path.join(self.save_path, self.name + '_dgl_graph.bin'))
|
||||||
|
self.g = graphs[0]
|
||||||
|
ntype = self.predict_ntype
|
||||||
|
self._num_classes = self.g.nodes[ntype].data['label'].max().item() + 1
|
||||||
|
for k in ('train_mask', 'val_mask', 'test_mask'):
|
||||||
|
self.g.nodes[ntype].data[k] = self.g.nodes[ntype].data[k].bool()
|
||||||
|
info = load_info(os.path.join(self.raw_path, self.name + '_pos.pkl'))
|
||||||
|
self.pos_i, self.pos_j = info['pos_i'], info['pos_j']
|
||||||
|
|
||||||
|
def process(self):
|
||||||
|
self.g = dgl.heterograph(self._read_edges())
|
||||||
|
|
||||||
|
feats = self._read_feats()
|
||||||
|
for ntype, feat in feats.items():
|
||||||
|
self.g.nodes[ntype].data['feat'] = feat
|
||||||
|
|
||||||
|
labels = torch.from_numpy(np.load(os.path.join(self.raw_path, 'labels.npy'))).long()
|
||||||
|
self._num_classes = labels.max().item() + 1
|
||||||
|
self.g.nodes[self.predict_ntype].data['label'] = labels
|
||||||
|
|
||||||
|
n = self.g.num_nodes(self.predict_ntype)
|
||||||
|
for split in ('train', 'val', 'test'):
|
||||||
|
idx = np.load(os.path.join(self.raw_path, f'{split}_60.npy'))
|
||||||
|
mask = generate_mask_tensor(idx2mask(idx, n))
|
||||||
|
self.g.nodes[self.predict_ntype].data[f'{split}_mask'] = mask
|
||||||
|
|
||||||
|
pos_i, pos_j = sp.load_npz(os.path.join(self.raw_path, 'pos.npz')).nonzero()
|
||||||
|
self.pos_i, self.pos_j = torch.from_numpy(pos_i).long(), torch.from_numpy(pos_j).long()
|
||||||
|
|
||||||
|
def _read_edges(self):
|
||||||
|
edges = {}
|
||||||
|
for file in os.listdir(self.raw_path):
|
||||||
|
name, ext = os.path.splitext(file)
|
||||||
|
if ext == '.txt':
|
||||||
|
u, v = name
|
||||||
|
e = pd.read_csv(os.path.join(self.raw_path, f'{u}{v}.txt'), sep='\t', names=[u, v])
|
||||||
|
src = e[u].to_list()
|
||||||
|
dst = e[v].to_list()
|
||||||
|
edges[(self._ntypes[u], f'{u}{v}', self._ntypes[v])] = (src, dst)
|
||||||
|
edges[(self._ntypes[v], f'{v}{u}', self._ntypes[u])] = (dst, src)
|
||||||
|
return edges
|
||||||
|
|
||||||
|
def _read_feats(self):
|
||||||
|
feats = {}
|
||||||
|
for u in self._ntypes:
|
||||||
|
file = os.path.join(self.raw_path, f'{u}_feat.npz')
|
||||||
|
if os.path.exists(file):
|
||||||
|
feats[self._ntypes[u]] = torch.from_numpy(sp.load_npz(file).toarray()).float()
|
||||||
|
return feats
|
||||||
|
|
||||||
|
def has_cache(self):
|
||||||
|
return os.path.exists(os.path.join(self.save_path, self.name + '_dgl_graph.bin'))
|
||||||
|
|
||||||
|
def __getitem__(self, idx):
|
||||||
|
if idx != 0:
|
||||||
|
raise IndexError('This dataset has only one graph')
|
||||||
|
return self.g
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return 1
|
||||||
|
|
||||||
|
@property
|
||||||
|
def num_classes(self):
|
||||||
|
return self._num_classes
|
||||||
|
|
||||||
|
@property
|
||||||
|
def metapaths(self):
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
@property
|
||||||
|
def predict_ntype(self):
|
||||||
|
raise NotImplementedError
|
||||||
|
|
||||||
|
@property
|
||||||
|
def pos(self):
|
||||||
|
return self.pos_i, self.pos_j
|
||||||
|
|
||||||
|
|
||||||
|
class ACMDataset(HeCoDataset):
|
||||||
|
"""ACM数据集
|
||||||
|
|
||||||
|
统计数据
|
||||||
|
-----
|
||||||
|
* 顶点:4019 paper, 7167 author, 60 subject
|
||||||
|
* 边:13407 paper-author, 4019 paper-subject
|
||||||
|
* 目标顶点类型:paper
|
||||||
|
* 类别数:3
|
||||||
|
* 顶点划分:180 train, 1000 valid, 1000 test
|
||||||
|
|
||||||
|
paper顶点特征
|
||||||
|
-----
|
||||||
|
* feat: tensor(N_paper, 1902)
|
||||||
|
* label: tensor(N_paper) 0~2
|
||||||
|
* train_mask, val_mask, test_mask: tensor(N_paper)
|
||||||
|
|
||||||
|
author顶点特征
|
||||||
|
-----
|
||||||
|
* feat: tensor(7167, 1902)
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__('acm', ['paper', 'author', 'subject'])
|
||||||
|
|
||||||
|
@property
|
||||||
|
def metapaths(self):
|
||||||
|
return [['pa', 'ap'], ['ps', 'sp']]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def predict_ntype(self):
|
||||||
|
return 'paper'
|
||||||
|
|
||||||
|
|
||||||
|
class DBLPDataset(HeCoDataset):
|
||||||
|
"""DBLP数据集
|
||||||
|
|
||||||
|
统计数据
|
||||||
|
-----
|
||||||
|
* 顶点:4057 author, 14328 paper, 20 conference, 7723 term
|
||||||
|
* 边:19645 paper-author, 14328 paper-conference, 85810 paper-term
|
||||||
|
* 目标顶点类型:author
|
||||||
|
* 类别数:4
|
||||||
|
* 顶点划分:240 train, 1000 valid, 1000 test
|
||||||
|
|
||||||
|
author顶点特征
|
||||||
|
-----
|
||||||
|
* feat: tensor(N_author, 334)
|
||||||
|
* label: tensor(N_author) 0~3
|
||||||
|
* train_mask, val_mask, test_mask: tensor(N_author)
|
||||||
|
|
||||||
|
paper顶点特征
|
||||||
|
-----
|
||||||
|
* feat: tensor(14328, 4231)
|
||||||
|
|
||||||
|
term顶点特征
|
||||||
|
-----
|
||||||
|
* feat: tensor(7723, 50)
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self):
|
||||||
|
super().__init__('dblp', ['author', 'paper', 'conference', 'term'])
|
||||||
|
|
||||||
|
def _read_feats(self):
|
||||||
|
feats = {}
|
||||||
|
for u in 'ap':
|
||||||
|
file = os.path.join(self.raw_path, f'{u}_feat.npz')
|
||||||
|
feats[self._ntypes[u]] = torch.from_numpy(sp.load_npz(file).toarray()).float()
|
||||||
|
feats['term'] = torch.from_numpy(np.load(os.path.join(self.raw_path, 't_feat.npz'))).float()
|
||||||
|
return feats
|
||||||
|
|
||||||
|
@property
|
||||||
|
def metapaths(self):
|
||||||
|
return [['ap', 'pa'], ['ap', 'pc', 'cp', 'pa'], ['ap', 'pt', 'tp', 'pa']]
|
||||||
|
|
||||||
|
@property
|
||||||
|
def predict_ntype(self):
|
||||||
|
return 'author'
|
||||||
|
|
@ -0,0 +1,269 @@
|
||||||
|
import dgl.function as fn
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from dgl.nn import GraphConv
|
||||||
|
from dgl.ops import edge_softmax
|
||||||
|
|
||||||
|
|
||||||
|
class HeCoGATConv(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, hidden_dim, attn_drop=0.0, negative_slope=0.01, activation=None):
|
||||||
|
"""HeCo作者代码中使用的GAT
|
||||||
|
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param attn_drop: float 注意力dropout
|
||||||
|
:param negative_slope: float, optional LeakyReLU负斜率,默认为0.01
|
||||||
|
:param activation: callable, optional 激活函数,默认为None
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.attn_l = nn.Parameter(torch.FloatTensor(1, hidden_dim))
|
||||||
|
self.attn_r = nn.Parameter(torch.FloatTensor(1, hidden_dim))
|
||||||
|
self.attn_drop = nn.Dropout(attn_drop)
|
||||||
|
self.leaky_relu = nn.LeakyReLU(negative_slope)
|
||||||
|
self.activation = activation
|
||||||
|
self.reset_parameters()
|
||||||
|
|
||||||
|
def reset_parameters(self):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
nn.init.xavier_normal_(self.attn_l, gain)
|
||||||
|
nn.init.xavier_normal_(self.attn_r, gain)
|
||||||
|
|
||||||
|
def forward(self, g, feat_src, feat_dst):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 邻居-目标顶点二分图
|
||||||
|
:param feat_src: tensor(N_src, d) 邻居顶点输入特征
|
||||||
|
:param feat_dst: tensor(N_dst, d) 目标顶点输入特征
|
||||||
|
:return: tensor(N_dst, d) 目标顶点输出特征
|
||||||
|
"""
|
||||||
|
with g.local_scope():
|
||||||
|
# HeCo作者代码中使用attn_drop的方式与原始GAT不同,这样是不对的,却能顶点聚类提升性能……
|
||||||
|
attn_l = self.attn_drop(self.attn_l)
|
||||||
|
attn_r = self.attn_drop(self.attn_r)
|
||||||
|
el = (feat_src * attn_l).sum(dim=-1).unsqueeze(dim=-1) # (N_src, 1)
|
||||||
|
er = (feat_dst * attn_r).sum(dim=-1).unsqueeze(dim=-1) # (N_dst, 1)
|
||||||
|
g.srcdata.update({'ft': feat_src, 'el': el})
|
||||||
|
g.dstdata['er'] = er
|
||||||
|
g.apply_edges(fn.u_add_v('el', 'er', 'e'))
|
||||||
|
e = self.leaky_relu(g.edata.pop('e'))
|
||||||
|
g.edata['a'] = edge_softmax(g, e) # (E, 1)
|
||||||
|
|
||||||
|
# 消息传递
|
||||||
|
g.update_all(fn.u_mul_e('ft', 'a', 'm'), fn.sum('m', 'ft'))
|
||||||
|
ret = g.dstdata['ft']
|
||||||
|
if self.activation:
|
||||||
|
ret = self.activation(ret)
|
||||||
|
return ret
|
||||||
|
|
||||||
|
|
||||||
|
class Attention(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, hidden_dim, attn_drop):
|
||||||
|
"""语义层次的注意力
|
||||||
|
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param attn_drop: float 注意力dropout
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.fc = nn.Linear(hidden_dim, hidden_dim)
|
||||||
|
self.attn = nn.Parameter(torch.FloatTensor(1, hidden_dim))
|
||||||
|
self.attn_drop = nn.Dropout(attn_drop)
|
||||||
|
self.reset_parameters()
|
||||||
|
|
||||||
|
def reset_parameters(self):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
nn.init.xavier_normal_(self.fc.weight, gain)
|
||||||
|
nn.init.xavier_normal_(self.attn, gain)
|
||||||
|
|
||||||
|
def forward(self, h):
|
||||||
|
"""
|
||||||
|
:param h: tensor(N, M, d) 顶点基于不同元路径/类型的嵌入,N为顶点数,M为元路径/类型数
|
||||||
|
:return: tensor(N, d) 顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
attn = self.attn_drop(self.attn)
|
||||||
|
# (N, M, d) -> (M, d) -> (M, 1)
|
||||||
|
w = torch.tanh(self.fc(h)).mean(dim=0).matmul(attn.t())
|
||||||
|
beta = torch.softmax(w, dim=0) # (M, 1)
|
||||||
|
beta = beta.expand((h.shape[0],) + beta.shape) # (N, M, 1)
|
||||||
|
z = (beta * h).sum(dim=1) # (N, d)
|
||||||
|
return z
|
||||||
|
|
||||||
|
|
||||||
|
class NetworkSchemaEncoder(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, hidden_dim, attn_drop, relations):
|
||||||
|
"""网络结构视图编码器
|
||||||
|
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param attn_drop: float 注意力dropout
|
||||||
|
:param relations: List[(str, str, str)] 目标顶点关联的关系列表,长度为邻居类型数S
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.relations = relations
|
||||||
|
self.dtype = relations[0][2]
|
||||||
|
self.gats = nn.ModuleDict({
|
||||||
|
r[0]: HeCoGATConv(hidden_dim, attn_drop, activation=F.elu)
|
||||||
|
for r in relations
|
||||||
|
})
|
||||||
|
self.attn = Attention(hidden_dim, attn_drop)
|
||||||
|
|
||||||
|
def forward(self, g, feats):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param feats: Dict[str, tensor(N_i, d)] 顶点类型到输入特征的映射
|
||||||
|
:return: tensor(N_dst, d) 目标顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
feat_dst = feats[self.dtype][:g.num_dst_nodes(self.dtype)]
|
||||||
|
h = []
|
||||||
|
for stype, etype, dtype in self.relations:
|
||||||
|
h.append(self.gats[stype](g[stype, etype, dtype], feats[stype], feat_dst))
|
||||||
|
h = torch.stack(h, dim=1) # (N_dst, S, d)
|
||||||
|
z_sc = self.attn(h) # (N_dst, d)
|
||||||
|
return z_sc
|
||||||
|
|
||||||
|
|
||||||
|
class PositiveGraphEncoder(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, num_metapaths, in_dim, hidden_dim, attn_drop):
|
||||||
|
"""正样本视图编码器
|
||||||
|
|
||||||
|
:param num_metapaths: int 元路径数量M
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param attn_drop: float 注意力dropout
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.gcns = nn.ModuleList([
|
||||||
|
GraphConv(in_dim, hidden_dim, norm='right', activation=nn.PReLU())
|
||||||
|
for _ in range(num_metapaths)
|
||||||
|
])
|
||||||
|
self.attn = Attention(hidden_dim, attn_drop)
|
||||||
|
|
||||||
|
def forward(self, mgs, feats):
|
||||||
|
"""
|
||||||
|
:param mgs: List[DGLGraph] 正样本图
|
||||||
|
:param feats: List[tensor(N, d)] 输入顶点特征
|
||||||
|
:return: tensor(N, d) 输出顶点特征
|
||||||
|
"""
|
||||||
|
h = [gcn(mg, feat) for gcn, mg, feat in zip(self.gcns, mgs, feats)]
|
||||||
|
h = torch.stack(h, dim=1) # (N, M, d)
|
||||||
|
z_pg = self.attn(h) # (N, d)
|
||||||
|
return z_pg
|
||||||
|
|
||||||
|
|
||||||
|
class Contrast(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, hidden_dim, tau, lambda_):
|
||||||
|
"""对比损失模块
|
||||||
|
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param tau: float 温度参数
|
||||||
|
:param lambda_: float 0~1之间,网络结构视图损失的系数(元路径视图损失的系数为1-λ)
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.proj = nn.Sequential(
|
||||||
|
nn.Linear(hidden_dim, hidden_dim),
|
||||||
|
nn.ELU(),
|
||||||
|
nn.Linear(hidden_dim, hidden_dim)
|
||||||
|
)
|
||||||
|
self.tau = tau
|
||||||
|
self.lambda_ = lambda_
|
||||||
|
self.reset_parameters()
|
||||||
|
|
||||||
|
def reset_parameters(self):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
for model in self.proj:
|
||||||
|
if isinstance(model, nn.Linear):
|
||||||
|
nn.init.xavier_normal_(model.weight, gain)
|
||||||
|
|
||||||
|
def sim(self, x, y):
|
||||||
|
"""计算相似度矩阵
|
||||||
|
|
||||||
|
:param x: tensor(N, d)
|
||||||
|
:param y: tensor(N, d)
|
||||||
|
:return: tensor(N, N) S[i, j] = exp(cos(x[i], y[j]))
|
||||||
|
"""
|
||||||
|
x_norm = torch.norm(x, dim=1, keepdim=True)
|
||||||
|
y_norm = torch.norm(y, dim=1, keepdim=True)
|
||||||
|
numerator = torch.mm(x, y.t())
|
||||||
|
denominator = torch.mm(x_norm, y_norm.t())
|
||||||
|
return torch.exp(numerator / denominator / self.tau)
|
||||||
|
|
||||||
|
def forward(self, z_sc, z_mp, pos):
|
||||||
|
"""
|
||||||
|
:param z_sc: tensor(N, d) 目标顶点在网络结构视图下的嵌入
|
||||||
|
:param z_mp: tensor(N, d) 目标顶点在元路径视图下的嵌入
|
||||||
|
:param pos: tensor(B, N) 0-1张量,每个目标顶点的正样本
|
||||||
|
(B是batch大小,真正的目标顶点;N是B个目标顶点加上其正样本后的顶点数)
|
||||||
|
:return: float 对比损失
|
||||||
|
"""
|
||||||
|
z_sc_proj = self.proj(z_sc)
|
||||||
|
z_mp_proj = self.proj(z_mp)
|
||||||
|
sim_sc2mp = self.sim(z_sc_proj, z_mp_proj)
|
||||||
|
sim_mp2sc = sim_sc2mp.t()
|
||||||
|
|
||||||
|
batch = pos.shape[0]
|
||||||
|
sim_sc2mp = sim_sc2mp / (sim_sc2mp.sum(dim=1, keepdim=True) + 1e-8) # 不能改成/=
|
||||||
|
loss_sc = -torch.log(torch.sum(sim_sc2mp[:batch] * pos, dim=1)).mean()
|
||||||
|
|
||||||
|
sim_mp2sc = sim_mp2sc / (sim_mp2sc.sum(dim=1, keepdim=True) + 1e-8)
|
||||||
|
loss_mp = -torch.log(torch.sum(sim_mp2sc[:batch] * pos, dim=1)).mean()
|
||||||
|
return self.lambda_ * loss_sc + (1 - self.lambda_) * loss_mp
|
||||||
|
|
||||||
|
|
||||||
|
class HeCo(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_dims, hidden_dim, feat_drop, attn_drop, relations, tau, lambda_):
|
||||||
|
"""HeCo模型
|
||||||
|
|
||||||
|
:param in_dims: Dict[str, int] 顶点类型到输入特征维数的映射
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param feat_drop: float 输入特征dropout
|
||||||
|
:param attn_drop: float 注意力dropout
|
||||||
|
:param relations: List[(str, str, str)] 目标顶点关联的关系列表,长度为邻居类型数S
|
||||||
|
:param tau: float 温度参数
|
||||||
|
:param lambda_: float 0~1之间,网络结构视图损失的系数(元路径视图损失的系数为1-λ)
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.dtype = relations[0][2]
|
||||||
|
self.fcs = nn.ModuleDict({
|
||||||
|
ntype: nn.Linear(in_dim, hidden_dim) for ntype, in_dim in in_dims.items()
|
||||||
|
})
|
||||||
|
self.feat_drop = nn.Dropout(feat_drop)
|
||||||
|
self.sc_encoder = NetworkSchemaEncoder(hidden_dim, attn_drop, relations)
|
||||||
|
self.mp_encoder = PositiveGraphEncoder(len(relations), hidden_dim, hidden_dim, attn_drop)
|
||||||
|
self.contrast = Contrast(hidden_dim, tau, lambda_)
|
||||||
|
self.reset_parameters()
|
||||||
|
|
||||||
|
def reset_parameters(self):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
for ntype in self.fcs:
|
||||||
|
nn.init.xavier_normal_(self.fcs[ntype].weight, gain)
|
||||||
|
|
||||||
|
def forward(self, g, feats, mgs, mg_feats, pos):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in)] 顶点类型到输入特征的映射
|
||||||
|
:param mgs: List[DGLBlock] 正样本图,len(mgs)=元路径数量=目标顶点邻居类型数S≠模型层数
|
||||||
|
:param mg_feats: List[tensor(N_pos_src, d_in)] 正样本图源顶点的输入特征
|
||||||
|
:param pos: tensor(B, N) 布尔张量,每个顶点的正样本
|
||||||
|
(B是batch大小,真正的目标顶点;N是B个目标顶点加上其正样本后的顶点数)
|
||||||
|
:return: float, tensor(B, d_hid) 对比损失,元路径编码器输出的目标顶点特征
|
||||||
|
"""
|
||||||
|
h = {ntype: F.elu(self.feat_drop(self.fcs[ntype](feat))) for ntype, feat in feats.items()}
|
||||||
|
mg_h = [F.elu(self.feat_drop(self.fcs[self.dtype](mg_feat))) for mg_feat in mg_feats]
|
||||||
|
z_sc = self.sc_encoder(g, h) # (N, d_hid)
|
||||||
|
z_mp = self.mp_encoder(mgs, mg_h) # (N, d_hid)
|
||||||
|
loss = self.contrast(z_sc, z_mp, pos)
|
||||||
|
return loss, z_mp[:pos.shape[0]]
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def get_embeds(self, mgs, feats):
|
||||||
|
"""计算目标顶点的最终嵌入(z_mp)
|
||||||
|
|
||||||
|
:param mgs: List[DGLBlock] 正样本图
|
||||||
|
:param feats: List[tensor(N_pos_src, d_in)] 正样本图源顶点的输入特征
|
||||||
|
:return: tensor(N_tgt, d_hid) 目标顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
h = [F.elu(self.fcs[self.dtype](feat)) for feat in feats]
|
||||||
|
z_mp = self.mp_encoder(mgs, h)
|
||||||
|
return z_mp
|
||||||
|
|
@ -0,0 +1,28 @@
|
||||||
|
import torch
|
||||||
|
from dgl.dataloading import MultiLayerNeighborSampler
|
||||||
|
|
||||||
|
|
||||||
|
class PositiveSampler(MultiLayerNeighborSampler):
|
||||||
|
|
||||||
|
def __init__(self, fanouts, pos):
|
||||||
|
"""用于HeCo模型的邻居采样器
|
||||||
|
|
||||||
|
对于每个batch的目标顶点,将其正样本添加到目标顶点并生成block
|
||||||
|
|
||||||
|
:param fanouts: 每层的邻居采样数(见MultiLayerNeighborSampler)
|
||||||
|
:param pos: tensor(N, T_pos) 每个顶点的正样本id,N是目标顶点数
|
||||||
|
"""
|
||||||
|
super().__init__(fanouts)
|
||||||
|
self.pos = pos
|
||||||
|
|
||||||
|
def sample_blocks(self, g, seed_nodes, exclude_eids=None):
|
||||||
|
# 如果g是异构图则seed_nodes是字典,应当只有目标顶点类型
|
||||||
|
if not g.is_homogeneous:
|
||||||
|
assert len(seed_nodes) == 1, 'PositiveSampler: 异构图只能指定目标顶点这一种类型'
|
||||||
|
ntype, seed_nodes = next(iter(seed_nodes.items()))
|
||||||
|
pos_samples = self.pos[seed_nodes].flatten() # (B, T_pos) -> (B*T_pos,)
|
||||||
|
added = list(set(pos_samples.tolist()) - set(seed_nodes.tolist()))
|
||||||
|
seed_nodes = torch.cat([seed_nodes, torch.tensor(added, device=seed_nodes.device)])
|
||||||
|
if not g.is_homogeneous:
|
||||||
|
seed_nodes = {ntype: seed_nodes}
|
||||||
|
return super().sample_blocks(g, seed_nodes, exclude_eids)
|
||||||
|
|
@ -0,0 +1,117 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
from dgl.dataloading import NodeDataLoader
|
||||||
|
from torch.utils.data import DataLoader
|
||||||
|
from tqdm import tqdm, trange
|
||||||
|
|
||||||
|
from gnnrec.hge.heco.model import HeCo
|
||||||
|
from gnnrec.hge.heco.sampler import PositiveSampler
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, accuracy, \
|
||||||
|
calc_metrics, METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, evaluator = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, 'pretrained', args.node_embed_path)
|
||||||
|
features = g.nodes[predict_ntype].data['feat']
|
||||||
|
relations = [r for r in g.canonical_etypes if r[2] == predict_ntype]
|
||||||
|
|
||||||
|
(*mgs, pos_g), _ = dgl.load_graphs(args.pos_graph_path)
|
||||||
|
mgs = [mg.to(device) for mg in mgs]
|
||||||
|
pos_g = pos_g.to(device)
|
||||||
|
pos = pos_g.in_edges(pos_g.nodes())[0].view(pos_g.num_nodes(), -1) # (N, T_pos) 每个目标顶点的正样本id
|
||||||
|
|
||||||
|
id_loader = DataLoader(train_idx, batch_size=args.batch_size)
|
||||||
|
sampler = PositiveSampler([None], pos)
|
||||||
|
loader = NodeDataLoader(g, {predict_ntype: train_idx}, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
mg_loaders = [
|
||||||
|
NodeDataLoader(mg, train_idx, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
for mg in mgs
|
||||||
|
]
|
||||||
|
pos_loader = NodeDataLoader(pos_g, train_idx, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
|
||||||
|
model = HeCo(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, args.feat_drop, args.attn_drop, relations, args.tau, args.lambda_
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr)
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
losses = []
|
||||||
|
for (batch, (_, _, blocks), *mg_blocks, (_, _, pos_blocks)) in tqdm(zip(id_loader, loader, *mg_loaders, pos_loader)):
|
||||||
|
block = blocks[0]
|
||||||
|
mg_feats = [features[i] for i, _, _ in mg_blocks]
|
||||||
|
mg_blocks = [b[0] for _, _, b in mg_blocks]
|
||||||
|
pos_block = pos_blocks[0]
|
||||||
|
batch_pos = torch.zeros(pos_block.num_dst_nodes(), batch.shape[0], dtype=torch.int, device=device)
|
||||||
|
batch_pos[pos_block.in_edges(torch.arange(batch.shape[0], device=device))] = 1
|
||||||
|
loss, _ = model(block, block.srcdata['feat'], mg_blocks, mg_feats, batch_pos.t())
|
||||||
|
losses.append(loss.item())
|
||||||
|
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print('Epoch {:d} | Loss {:.4f}'.format(epoch, sum(losses) / len(losses)))
|
||||||
|
if epoch % args.eval_every == 0 or epoch == args.epochs - 1:
|
||||||
|
print(METRICS_STR.format(*evaluate(
|
||||||
|
model, mgs, features, device, labels, data.num_classes,
|
||||||
|
train_idx, val_idx, test_idx, evaluator
|
||||||
|
)))
|
||||||
|
|
||||||
|
|
||||||
|
def evaluate(model, mgs, feat, device, labels, num_classes, train_idx, val_idx, test_idx, evaluator):
|
||||||
|
model.eval()
|
||||||
|
embeds = model.get_embeds(mgs, [feat] * len(mgs))
|
||||||
|
|
||||||
|
clf = nn.Linear(embeds.shape[1], num_classes).to(device)
|
||||||
|
optimizer = optim.Adam(clf.parameters(), lr=0.05)
|
||||||
|
best_acc, best_logits = 0, None
|
||||||
|
for epoch in trange(200):
|
||||||
|
clf.train()
|
||||||
|
logits = clf(embeds)
|
||||||
|
loss = F.cross_entropy(logits[train_idx], labels[train_idx])
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
|
||||||
|
with torch.no_grad():
|
||||||
|
clf.eval()
|
||||||
|
logits = clf(embeds)
|
||||||
|
predict = logits.argmax(dim=1)
|
||||||
|
if accuracy(predict[val_idx], labels[val_idx]) > best_acc:
|
||||||
|
best_logits = logits
|
||||||
|
return calc_metrics(best_logits, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练HeCo模型')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['ogbn-mag', 'oag-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=64, help='隐藏层维数')
|
||||||
|
parser.add_argument('--feat-drop', type=float, default=0.3, help='特征dropout')
|
||||||
|
parser.add_argument('--attn-drop', type=float, default=0.5, help='注意力dropout')
|
||||||
|
parser.add_argument('--tau', type=float, default=0.8, help='温度参数')
|
||||||
|
parser.add_argument('--lambda', type=float, default=0.5, dest='lambda_', help='对比损失的平衡系数')
|
||||||
|
parser.add_argument('--epochs', type=int, default=200, help='训练epoch数')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=1024, help='批大小')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.0008, help='学习率')
|
||||||
|
parser.add_argument('--eval-every', type=int, default=10, help='每多少个epoch计算一次准确率')
|
||||||
|
parser.add_argument('node_embed_path', help='预训练顶点嵌入路径')
|
||||||
|
parser.add_argument('pos_graph_path', help='正样本图路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,291 @@
|
||||||
|
import dgl.function as fn
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from dgl.dataloading import MultiLayerFullNeighborSampler, NodeDataLoader
|
||||||
|
from dgl.ops import edge_softmax
|
||||||
|
from dgl.utils import expand_as_pair
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
|
||||||
|
class MicroConv(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, out_dim, num_heads, fc_src, fc_dst, attn_src,
|
||||||
|
feat_drop=0.0, negative_slope=0.2, activation=None):
|
||||||
|
"""微观层次卷积
|
||||||
|
|
||||||
|
针对一种关系(边类型)R=<stype, etype, dtype>,聚集关系R下的邻居信息,得到关系R关于dtype类型顶点的表示
|
||||||
|
(特征转换矩阵和注意力向量是与顶点类型相关的,除此之外与GAT完全相同)
|
||||||
|
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param fc_src: nn.Linear(d_in, K*d_out) 源顶点特征转换模块
|
||||||
|
:param fc_dst: nn.Linear(d_in, K*d_out) 目标顶点特征转换模块
|
||||||
|
:param attn_src: nn.Parameter(K, 2d_out) 源顶点类型对应的注意力向量
|
||||||
|
:param feat_drop: float, optional 输入特征Dropout概率,默认为0
|
||||||
|
:param negative_slope: float, optional LeakyReLU负斜率,默认为0.2
|
||||||
|
:param activation: callable, optional 用于输出特征的激活函数,默认为None
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.out_dim = out_dim
|
||||||
|
self.num_heads = num_heads
|
||||||
|
self.fc_src = fc_src
|
||||||
|
self.fc_dst = fc_dst
|
||||||
|
self.attn_src = attn_src
|
||||||
|
self.feat_drop = nn.Dropout(feat_drop)
|
||||||
|
self.leaky_relu = nn.LeakyReLU(negative_slope)
|
||||||
|
self.activation = activation
|
||||||
|
|
||||||
|
def forward(self, g, feat):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 二分图(只包含一种关系)
|
||||||
|
:param feat: tensor(N_src, d_in) or (tensor(N_src, d_in), tensor(N_dst, d_in)) 输入特征
|
||||||
|
:return: tensor(N_dst, K*d_out) 该关系关于目标顶点的表示
|
||||||
|
"""
|
||||||
|
with g.local_scope():
|
||||||
|
feat_src, feat_dst = expand_as_pair(feat, g)
|
||||||
|
feat_src = self.fc_src(self.feat_drop(feat_src)).view(-1, self.num_heads, self.out_dim)
|
||||||
|
feat_dst = self.fc_dst(self.feat_drop(feat_dst)).view(-1, self.num_heads, self.out_dim)
|
||||||
|
|
||||||
|
# a^T (z_u || z_v) = (a_l^T || a_r^T) (z_u || z_v) = a_l^T z_u + a_r^T z_v = el + er
|
||||||
|
el = (feat_src * self.attn_src[:, :self.out_dim]).sum(dim=-1, keepdim=True) # (N_src, K, 1)
|
||||||
|
er = (feat_dst * self.attn_src[:, self.out_dim:]).sum(dim=-1, keepdim=True) # (N_dst, K, 1)
|
||||||
|
g.srcdata.update({'ft': feat_src, 'el': el})
|
||||||
|
g.dstdata['er'] = er
|
||||||
|
g.apply_edges(fn.u_add_v('el', 'er', 'e'))
|
||||||
|
e = self.leaky_relu(g.edata.pop('e'))
|
||||||
|
g.edata['a'] = edge_softmax(g, e) # (E, K, 1)
|
||||||
|
|
||||||
|
# 消息传递
|
||||||
|
g.update_all(fn.u_mul_e('ft', 'a', 'm'), fn.sum('m', 'ft'))
|
||||||
|
ret = g.dstdata['ft'].view(-1, self.num_heads * self.out_dim)
|
||||||
|
if self.activation:
|
||||||
|
ret = self.activation(ret)
|
||||||
|
return ret
|
||||||
|
|
||||||
|
|
||||||
|
class MacroConv(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, out_dim, num_heads, fc_node, fc_rel, attn, dropout=0.0, negative_slope=0.2):
|
||||||
|
"""宏观层次卷积
|
||||||
|
|
||||||
|
针对所有关系(边类型),将每种类型的顶点关联的所有关系关于该类型顶点的表示组合起来
|
||||||
|
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param fc_node: Dict[str, nn.Linear(d_in, K*d_out)] 顶点类型到顶点特征转换模块的映射
|
||||||
|
:param fc_rel: Dict[str, nn.Linear(K*d_out, K*d_out)] 关系到关系表示转换模块的映射
|
||||||
|
:param attn: nn.Parameter(K, 2d_out)
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
:param negative_slope: float, optional LeakyReLU负斜率,默认为0.2
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.out_dim = out_dim
|
||||||
|
self.num_heads = num_heads
|
||||||
|
self.fc_node = fc_node
|
||||||
|
self.fc_rel = fc_rel
|
||||||
|
self.attn = attn
|
||||||
|
self.dropout = nn.Dropout(dropout)
|
||||||
|
self.leaky_relu = nn.LeakyReLU(negative_slope)
|
||||||
|
|
||||||
|
def forward(self, node_feats, rel_feats):
|
||||||
|
"""
|
||||||
|
:param node_feats: Dict[str, tensor(N_i, d_in) 顶点类型到输入顶点特征的映射
|
||||||
|
:param rel_feats: Dict[(str, str, str), tensor(N_i, K*d_out)]
|
||||||
|
关系(stype, etype, dtype)到关系关于其终点类型的表示的映射
|
||||||
|
:return: Dict[str, tensor(N_i, K*d_out)] 顶点类型到最终顶点嵌入的映射
|
||||||
|
"""
|
||||||
|
node_feats = {
|
||||||
|
ntype: self.fc_node[ntype](feat).view(-1, self.num_heads, self.out_dim)
|
||||||
|
for ntype, feat in node_feats.items()
|
||||||
|
}
|
||||||
|
rel_feats = {
|
||||||
|
r: self.fc_rel[r[1]](feat).view(-1, self.num_heads, self.out_dim)
|
||||||
|
for r, feat in rel_feats.items()
|
||||||
|
}
|
||||||
|
out_feats = {}
|
||||||
|
for ntype, node_feat in node_feats.items():
|
||||||
|
rel_node_feats = [feat for rel, feat in rel_feats.items() if rel[2] == ntype]
|
||||||
|
if not rel_node_feats:
|
||||||
|
continue
|
||||||
|
elif len(rel_node_feats) == 1:
|
||||||
|
out_feats[ntype] = rel_node_feats[0].view(-1, self.num_heads * self.out_dim)
|
||||||
|
else:
|
||||||
|
rel_node_feats = torch.stack(rel_node_feats, dim=0) # (R, N_i, K, d_out)
|
||||||
|
cat_feats = torch.cat(
|
||||||
|
(node_feat.repeat(rel_node_feats.shape[0], 1, 1, 1), rel_node_feats), dim=-1
|
||||||
|
) # (R, N_i, K, 2d_out)
|
||||||
|
attn_scores = self.leaky_relu((self.attn * cat_feats).sum(dim=-1, keepdim=True))
|
||||||
|
attn_scores = F.softmax(attn_scores, dim=0) # (R, N_i, K, 1)
|
||||||
|
out_feat = (attn_scores * rel_node_feats).sum(dim=0) # (N_i, K, d_out)
|
||||||
|
out_feats[ntype] = self.dropout(out_feat.reshape(-1, self.num_heads * self.out_dim))
|
||||||
|
return out_feats
|
||||||
|
|
||||||
|
|
||||||
|
class HGConvLayer(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_dim, out_dim, num_heads, ntypes, etypes, dropout=0.0, residual=True):
|
||||||
|
"""HGConv层
|
||||||
|
|
||||||
|
:param in_dim: int 输入特征维数
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param ntypes: List[str] 顶点类型列表
|
||||||
|
:param etypes: List[(str, str, str)] 规范边类型列表
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
:param residual: bool, optional 是否使用残差连接,默认True
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
# 微观层次卷积的参数
|
||||||
|
micro_fc = {ntype: nn.Linear(in_dim, num_heads * out_dim, bias=False) for ntype in ntypes}
|
||||||
|
micro_attn = {
|
||||||
|
ntype: nn.Parameter(torch.FloatTensor(size=(num_heads, 2 * out_dim)))
|
||||||
|
for ntype in ntypes
|
||||||
|
}
|
||||||
|
|
||||||
|
# 宏观层次卷积的参数
|
||||||
|
macro_fc_node = nn.ModuleDict({
|
||||||
|
ntype: nn.Linear(in_dim, num_heads * out_dim, bias=False) for ntype in ntypes
|
||||||
|
})
|
||||||
|
macro_fc_rel = nn.ModuleDict({
|
||||||
|
r[1]: nn.Linear(num_heads * out_dim, num_heads * out_dim, bias=False)
|
||||||
|
for r in etypes
|
||||||
|
})
|
||||||
|
macro_attn = nn.Parameter(torch.FloatTensor(size=(num_heads, 2 * out_dim)))
|
||||||
|
|
||||||
|
self.micro_conv = nn.ModuleDict({
|
||||||
|
etype: MicroConv(
|
||||||
|
out_dim, num_heads, micro_fc[stype],
|
||||||
|
micro_fc[dtype], micro_attn[stype], dropout, activation=F.relu
|
||||||
|
) for stype, etype, dtype in etypes
|
||||||
|
})
|
||||||
|
self.macro_conv = MacroConv(
|
||||||
|
out_dim, num_heads, macro_fc_node, macro_fc_rel, macro_attn, dropout
|
||||||
|
)
|
||||||
|
|
||||||
|
self.residual = residual
|
||||||
|
if residual:
|
||||||
|
self.res_fc = nn.ModuleDict({
|
||||||
|
ntype: nn.Linear(in_dim, num_heads * out_dim) for ntype in ntypes
|
||||||
|
})
|
||||||
|
self.res_weight = nn.ParameterDict({
|
||||||
|
ntype: nn.Parameter(torch.rand(1)) for ntype in ntypes
|
||||||
|
})
|
||||||
|
self.reset_parameters(micro_fc, micro_attn, macro_fc_node, macro_fc_rel, macro_attn)
|
||||||
|
|
||||||
|
def reset_parameters(self, micro_fc, micro_attn, macro_fc_node, macro_fc_rel, macro_attn):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
for ntype in micro_fc:
|
||||||
|
nn.init.xavier_normal_(micro_fc[ntype].weight, gain=gain)
|
||||||
|
nn.init.xavier_normal_(micro_attn[ntype], gain=gain)
|
||||||
|
nn.init.xavier_normal_(macro_fc_node[ntype].weight, gain=gain)
|
||||||
|
if self.residual:
|
||||||
|
nn.init.xavier_normal_(self.res_fc[ntype].weight, gain=gain)
|
||||||
|
for etype in macro_fc_rel:
|
||||||
|
nn.init.xavier_normal_(macro_fc_rel[etype].weight, gain=gain)
|
||||||
|
nn.init.xavier_normal_(macro_attn, gain=gain)
|
||||||
|
|
||||||
|
def forward(self, g, feats):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in)] 顶点类型到输入顶点特征的映射
|
||||||
|
:return: Dict[str, tensor(N_i, K*d_out)] 顶点类型到最终顶点嵌入的映射
|
||||||
|
"""
|
||||||
|
if g.is_block:
|
||||||
|
feats_dst = {ntype: feats[ntype][:g.num_dst_nodes(ntype)] for ntype in feats}
|
||||||
|
else:
|
||||||
|
feats_dst = feats
|
||||||
|
rel_feats = {
|
||||||
|
(stype, etype, dtype): self.micro_conv[etype](
|
||||||
|
g[stype, etype, dtype], (feats[stype], feats_dst[dtype])
|
||||||
|
)
|
||||||
|
for stype, etype, dtype in g.canonical_etypes
|
||||||
|
if g.num_edges((stype, etype, dtype)) > 0
|
||||||
|
} # {rel: tensor(N_i, K*d_out)}
|
||||||
|
out_feats = self.macro_conv(feats_dst, rel_feats) # {ntype: tensor(N_i, K*d_out)}
|
||||||
|
if self.residual:
|
||||||
|
for ntype in out_feats:
|
||||||
|
alpha = torch.sigmoid(self.res_weight[ntype])
|
||||||
|
inherit_feat = self.res_fc[ntype](feats_dst[ntype])
|
||||||
|
out_feats[ntype] = alpha * out_feats[ntype] + (1 - alpha) * inherit_feat
|
||||||
|
return out_feats
|
||||||
|
|
||||||
|
|
||||||
|
class HGConv(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, in_dims, hidden_dim, out_dim, num_heads, ntypes, etypes, predict_ntype,
|
||||||
|
num_layers, dropout=0.0, residual=True):
|
||||||
|
"""HGConv模型
|
||||||
|
|
||||||
|
:param in_dims: Dict[str, int] 顶点类型到输入特征维数的映射
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param ntypes: List[str] 顶点类型列表
|
||||||
|
:param etypes: List[(str, str, str)] 规范边类型列表
|
||||||
|
:param predict_ntype: str 待预测顶点类型
|
||||||
|
:param num_layers: int 层数
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
:param residual: bool, optional 是否使用残差连接,默认True
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.d = num_heads * hidden_dim
|
||||||
|
self.predict_ntype = predict_ntype
|
||||||
|
# 对齐输入特征维数
|
||||||
|
self.fc_in = nn.ModuleDict({
|
||||||
|
ntype: nn.Linear(in_dim, num_heads * hidden_dim) for ntype, in_dim in in_dims.items()
|
||||||
|
})
|
||||||
|
self.layers = nn.ModuleList([
|
||||||
|
HGConvLayer(
|
||||||
|
num_heads * hidden_dim, hidden_dim, num_heads, ntypes, etypes, dropout, residual
|
||||||
|
) for _ in range(num_layers)
|
||||||
|
])
|
||||||
|
self.classifier = nn.Linear(num_heads * hidden_dim, out_dim)
|
||||||
|
|
||||||
|
def forward(self, blocks, feats):
|
||||||
|
"""
|
||||||
|
:param blocks: List[DGLBlock]
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in_i)] 顶点类型到输入顶点特征的映射
|
||||||
|
:return: tensor(N_i, d_out) 待预测顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
feats = {ntype: self.fc_in[ntype](feat) for ntype, feat in feats.items()}
|
||||||
|
for i in range(len(self.layers)):
|
||||||
|
feats = self.layers[i](blocks[i], feats) # {ntype: tensor(N_i, K*d_hid)}
|
||||||
|
return self.classifier(feats[self.predict_ntype])
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def inference(self, g, feats, device, batch_size):
|
||||||
|
"""离线推断所有顶点的最终嵌入(不使用邻居采样)
|
||||||
|
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in_i)] 顶点类型到输入顶点特征的映射
|
||||||
|
:param device: torch.device
|
||||||
|
:param batch_size: int 批大小
|
||||||
|
:return: tensor(N_i, d_out) 待预测顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
g.ndata['emb'] = {ntype: self.fc_in[ntype](feat) for ntype, feat in feats.items()}
|
||||||
|
for layer in self.layers:
|
||||||
|
embeds = {
|
||||||
|
ntype: torch.zeros(g.num_nodes(ntype), self.d, device=device)
|
||||||
|
for ntype in g.ntypes
|
||||||
|
}
|
||||||
|
sampler = MultiLayerFullNeighborSampler(1)
|
||||||
|
loader = NodeDataLoader(
|
||||||
|
g, {ntype: g.nodes(ntype) for ntype in g.ntypes}, sampler, device=device,
|
||||||
|
batch_size=batch_size, shuffle=True
|
||||||
|
)
|
||||||
|
for input_nodes, output_nodes, blocks in tqdm(loader):
|
||||||
|
block = blocks[0]
|
||||||
|
h = layer(block, block.srcdata['emb'])
|
||||||
|
for ntype in h:
|
||||||
|
embeds[ntype][output_nodes[ntype]] = h[ntype]
|
||||||
|
g.ndata['emb'] = embeds
|
||||||
|
return self.classifier(g.nodes[self.predict_ntype].data['emb'])
|
||||||
|
|
||||||
|
|
||||||
|
class HGConvFull(HGConv):
|
||||||
|
|
||||||
|
def forward(self, g, feats):
|
||||||
|
return super().forward([g] * len(self.layers), feats)
|
||||||
|
|
@ -0,0 +1,83 @@
|
||||||
|
import argparse
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
from dgl.dataloading import MultiLayerNeighborSampler, NodeDataLoader
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from gnnrec.hge.hgconv.model import HGConv
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, evaluate, \
|
||||||
|
calc_metrics, METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, evaluator = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, args.node_feat, args.node_embed_path)
|
||||||
|
|
||||||
|
sampler = MultiLayerNeighborSampler([args.neighbor_size] * args.num_layers)
|
||||||
|
train_loader = NodeDataLoader(g, {predict_ntype: train_idx}, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
loader = NodeDataLoader(g, {predict_ntype: g.nodes(predict_ntype)}, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
|
||||||
|
model = HGConv(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_heads, g.ntypes, g.canonical_etypes,
|
||||||
|
predict_ntype, args.num_layers, args.dropout, args.residual
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
|
||||||
|
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
losses = []
|
||||||
|
for input_nodes, output_nodes, blocks in tqdm(train_loader):
|
||||||
|
batch_logits = model(blocks, blocks[0].srcdata['feat'])
|
||||||
|
batch_labels = labels[output_nodes[predict_ntype]]
|
||||||
|
loss = F.cross_entropy(batch_logits, batch_labels)
|
||||||
|
losses.append(loss.item())
|
||||||
|
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print('Epoch {:d} | Loss {:.4f}'.format(epoch, sum(losses) / len(losses)))
|
||||||
|
if epoch % args.eval_every == 0 or epoch == args.epochs - 1:
|
||||||
|
print(METRICS_STR.format(*evaluate(
|
||||||
|
model, loader, g, labels, data.num_classes, predict_ntype,
|
||||||
|
train_idx, val_idx, test_idx, evaluator
|
||||||
|
)))
|
||||||
|
embeds = model.inference(g, g.ndata['feat'], device, args.batch_size)
|
||||||
|
print(METRICS_STR.format(*calc_metrics(embeds, labels, train_idx, val_idx, test_idx, evaluator)))
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练HGConv模型')
|
||||||
|
parser.add_argument('--seed', type=int, default=8, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['ogbn-mag', 'oag-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
parser.add_argument(
|
||||||
|
'--node-feat', choices=['average', 'pretrained'], default='pretrained',
|
||||||
|
help='如何获取无特征顶点的输入特征'
|
||||||
|
)
|
||||||
|
parser.add_argument('--node-embed-path', help='预训练顶点嵌入路径')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=32, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--no-residual', action='store_false', help='不使用残差连接', dest='residual')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--epochs', type=int, default=100, help='训练epoch数')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=4096, help='批大小')
|
||||||
|
parser.add_argument('--neighbor-size', type=int, default=10, help='邻居采样数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
|
||||||
|
parser.add_argument('--weight-decay', type=float, default=0.0, help='权重衰减')
|
||||||
|
parser.add_argument('--eval-every', type=int, default=10, help='每多少个epoch计算一次准确率')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,59 @@
|
||||||
|
import argparse
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
|
||||||
|
from gnnrec.hge.hgconv.model import HGConvFull
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, evaluate_full, \
|
||||||
|
METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, _ = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, 'one-hot')
|
||||||
|
|
||||||
|
model = HGConvFull(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_heads, g.ntypes, g.canonical_etypes,
|
||||||
|
predict_ntype, args.num_layers, args.dropout, args.residual
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
|
||||||
|
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
logits = model(g, g.ndata['feat'])
|
||||||
|
loss = F.cross_entropy(logits[train_idx], labels[train_idx])
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print(('Epoch {:d} | Loss {:.4f} | ' + METRICS_STR).format(
|
||||||
|
epoch, loss.item(), *evaluate_full(model, g, labels, train_idx, val_idx, test_idx)
|
||||||
|
))
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练HGConv模型(full-batch)')
|
||||||
|
parser.add_argument('--seed', type=int, default=8, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['acm', 'dblp'], default='acm', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=32, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--no-residual', action='store_false', help='不使用残差连接', dest='residual')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--epochs', type=int, default=10, help='训练epoch数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
|
||||||
|
parser.add_argument('--weight-decay', type=float, default=0.0, help='权重衰减')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,180 @@
|
||||||
|
import math
|
||||||
|
|
||||||
|
import dgl.function as fn
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from dgl.nn import HeteroGraphConv
|
||||||
|
from dgl.ops import edge_softmax
|
||||||
|
from dgl.utils import expand_as_pair
|
||||||
|
|
||||||
|
|
||||||
|
class HGTAttention(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, out_dim, num_heads, k_linear, q_linear, v_linear, w_att, w_msg, mu):
|
||||||
|
"""HGT注意力模块
|
||||||
|
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param k_linear: nn.Linear(d_in, d_out)
|
||||||
|
:param q_linear: nn.Linear(d_in, d_out)
|
||||||
|
:param v_linear: nn.Linear(d_in, d_out)
|
||||||
|
:param w_att: tensor(K, d_out/K, d_out/K)
|
||||||
|
:param w_msg: tensor(K, d_out/K, d_out/K)
|
||||||
|
:param mu: tensor(1)
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.out_dim = out_dim
|
||||||
|
self.num_heads = num_heads
|
||||||
|
self.d_k = out_dim // num_heads
|
||||||
|
self.k_linear = k_linear
|
||||||
|
self.q_linear = q_linear
|
||||||
|
self.v_linear = v_linear
|
||||||
|
self.w_att = w_att
|
||||||
|
self.w_msg = w_msg
|
||||||
|
self.mu = mu
|
||||||
|
|
||||||
|
def forward(self, g, feat):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 二分图(只包含一种关系)
|
||||||
|
:param feat: tensor(N_src, d_in) or (tensor(N_src, d_in), tensor(N_dst, d_in)) 输入特征
|
||||||
|
:return: tensor(N_dst, d_out) 目标顶点该关于关系的表示
|
||||||
|
"""
|
||||||
|
with g.local_scope():
|
||||||
|
feat_src, feat_dst = expand_as_pair(feat, g)
|
||||||
|
# (N_src, d_in) -> (N_src, d_out) -> (N_src, K, d_out/K)
|
||||||
|
k = self.k_linear(feat_src).view(-1, self.num_heads, self.d_k)
|
||||||
|
v = self.v_linear(feat_src).view(-1, self.num_heads, self.d_k)
|
||||||
|
q = self.q_linear(feat_dst).view(-1, self.num_heads, self.d_k)
|
||||||
|
|
||||||
|
# k[:, h] @= w_att[h] => k[n, h, j] = ∑(i) k[n, h, i] * w_att[h, i, j]
|
||||||
|
k = torch.einsum('nhi,hij->nhj', k, self.w_att)
|
||||||
|
v = torch.einsum('nhi,hij->nhj', v, self.w_msg)
|
||||||
|
|
||||||
|
g.srcdata.update({'k': k, 'v': v})
|
||||||
|
g.dstdata['q'] = q
|
||||||
|
g.apply_edges(fn.v_dot_u('q', 'k', 't')) # g.edata['t']: (E, K, 1)
|
||||||
|
attn = g.edata.pop('t').squeeze(dim=-1) * self.mu / math.sqrt(self.d_k)
|
||||||
|
attn = edge_softmax(g, attn) # (E, K)
|
||||||
|
self.attn = attn.detach()
|
||||||
|
g.edata['t'] = attn.unsqueeze(dim=-1) # (E, K, 1)
|
||||||
|
|
||||||
|
g.update_all(fn.u_mul_e('v', 't', 'm'), fn.sum('m', 'h'))
|
||||||
|
out = g.dstdata['h'].view(-1, self.out_dim) # (N_dst, d_out)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class HGTLayer(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_dim, out_dim, num_heads, ntypes, etypes, dropout=0.2, use_norm=True):
|
||||||
|
"""HGT层
|
||||||
|
|
||||||
|
:param in_dim: int 输入特征维数
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param ntypes: List[str] 顶点类型列表
|
||||||
|
:param etypes: List[(str, str, str)] 规范边类型列表
|
||||||
|
:param dropout: dropout: float, optional Dropout概率,默认为0.2
|
||||||
|
:param use_norm: bool, optional 是否使用层归一化,默认为True
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
d_k = out_dim // num_heads
|
||||||
|
k_linear = {ntype: nn.Linear(in_dim, out_dim) for ntype in ntypes}
|
||||||
|
q_linear = {ntype: nn.Linear(in_dim, out_dim) for ntype in ntypes}
|
||||||
|
v_linear = {ntype: nn.Linear(in_dim, out_dim) for ntype in ntypes}
|
||||||
|
w_att = {r[1]: nn.Parameter(torch.Tensor(num_heads, d_k, d_k)) for r in etypes}
|
||||||
|
w_msg = {r[1]: nn.Parameter(torch.Tensor(num_heads, d_k, d_k)) for r in etypes}
|
||||||
|
mu = {r[1]: nn.Parameter(torch.ones(num_heads)) for r in etypes}
|
||||||
|
self.reset_parameters(w_att, w_msg)
|
||||||
|
self.conv = HeteroGraphConv({
|
||||||
|
etype: HGTAttention(
|
||||||
|
out_dim, num_heads, k_linear[stype], q_linear[dtype], v_linear[stype],
|
||||||
|
w_att[etype], w_msg[etype], mu[etype]
|
||||||
|
) for stype, etype, dtype in etypes
|
||||||
|
}, 'mean')
|
||||||
|
|
||||||
|
self.a_linear = nn.ModuleDict({ntype: nn.Linear(out_dim, out_dim) for ntype in ntypes})
|
||||||
|
self.skip = nn.ParameterDict({ntype: nn.Parameter(torch.ones(1)) for ntype in ntypes})
|
||||||
|
self.drop = nn.Dropout(dropout)
|
||||||
|
|
||||||
|
self.use_norm = use_norm
|
||||||
|
if use_norm:
|
||||||
|
self.norms = nn.ModuleDict({ntype: nn.LayerNorm(out_dim) for ntype in ntypes})
|
||||||
|
|
||||||
|
def reset_parameters(self, w_att, w_msg):
|
||||||
|
for etype in w_att:
|
||||||
|
nn.init.xavier_uniform_(w_att[etype])
|
||||||
|
nn.init.xavier_uniform_(w_msg[etype])
|
||||||
|
|
||||||
|
def forward(self, g, feats):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in)] 顶点类型到输入顶点特征的映射
|
||||||
|
:return: Dict[str, tensor(N_i, d_out)] 顶点类型到输出特征的映射
|
||||||
|
"""
|
||||||
|
if g.is_block:
|
||||||
|
feats_dst = {ntype: feats[ntype][:g.num_dst_nodes(ntype)] for ntype in feats}
|
||||||
|
else:
|
||||||
|
feats_dst = feats
|
||||||
|
with g.local_scope():
|
||||||
|
# 第1步:异构互注意力+异构消息传递+目标相关的聚集
|
||||||
|
hs = self.conv(g, feats) # {ntype: tensor(N_i, d_out)}
|
||||||
|
|
||||||
|
# 第2步:残差连接
|
||||||
|
out_feats = {}
|
||||||
|
for ntype in g.dsttypes:
|
||||||
|
if g.num_dst_nodes(ntype) == 0:
|
||||||
|
continue
|
||||||
|
alpha = torch.sigmoid(self.skip[ntype])
|
||||||
|
trans_out = self.drop(self.a_linear[ntype](hs[ntype]))
|
||||||
|
out = alpha * trans_out + (1 - alpha) * feats_dst[ntype]
|
||||||
|
out_feats[ntype] = self.norms[ntype](out) if self.use_norm else out
|
||||||
|
return out_feats
|
||||||
|
|
||||||
|
|
||||||
|
class HGT(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, in_dims, hidden_dim, out_dim, num_heads, ntypes, etypes,
|
||||||
|
predict_ntype, num_layers, dropout=0.2, use_norm=True):
|
||||||
|
"""HGT模型
|
||||||
|
|
||||||
|
:param in_dims: Dict[str, int] 顶点类型到输入特征维数的映射
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param ntypes: List[str] 顶点类型列表
|
||||||
|
:param etypes: List[(str, str, str)] 规范边类型列表
|
||||||
|
:param predict_ntype: str 待预测顶点类型
|
||||||
|
:param num_layers: int 层数
|
||||||
|
:param dropout: dropout: float, optional Dropout概率,默认为0.2
|
||||||
|
:param use_norm: bool, optional 是否使用层归一化,默认为True
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.predict_ntype = predict_ntype
|
||||||
|
self.adapt_fcs = nn.ModuleDict({
|
||||||
|
ntype: nn.Linear(in_dim, hidden_dim) for ntype, in_dim in in_dims.items()
|
||||||
|
})
|
||||||
|
self.layers = nn.ModuleList([
|
||||||
|
HGTLayer(hidden_dim, hidden_dim, num_heads, ntypes, etypes, dropout, use_norm)
|
||||||
|
for _ in range(num_layers)
|
||||||
|
])
|
||||||
|
self.predict = nn.Linear(hidden_dim, out_dim)
|
||||||
|
|
||||||
|
def forward(self, blocks, feats):
|
||||||
|
"""
|
||||||
|
:param blocks: List[DGLBlock]
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in)] 顶点类型到输入顶点特征的映射
|
||||||
|
:return: tensor(N_i, d_out) 待预测顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
hs = {ntype: F.gelu(self.adapt_fcs[ntype](feats[ntype])) for ntype in feats}
|
||||||
|
for i in range(len(self.layers)):
|
||||||
|
hs = self.layers[i](blocks[i], hs) # {ntype: tensor(N_i, d_hid)}
|
||||||
|
out = self.predict(hs[self.predict_ntype]) # tensor(N_i, d_out)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class HGTFull(HGT):
|
||||||
|
|
||||||
|
def forward(self, g, feats):
|
||||||
|
return super().forward([g] * len(self.layers), feats)
|
||||||
|
|
@ -0,0 +1,88 @@
|
||||||
|
import argparse
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
from dgl.dataloading import MultiLayerNeighborSampler, NodeDataLoader
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from gnnrec.hge.hgt.model import HGT
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, evaluate, \
|
||||||
|
METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, evaluator = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, args.node_feat, args.node_embed_path)
|
||||||
|
|
||||||
|
sampler = MultiLayerNeighborSampler([args.neighbor_size] * args.num_layers)
|
||||||
|
train_loader = NodeDataLoader(g, {predict_ntype: train_idx}, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
loader = NodeDataLoader(g, {predict_ntype: g.nodes(predict_ntype)}, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
|
||||||
|
model = HGT(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_heads, g.ntypes, g.canonical_etypes,
|
||||||
|
predict_ntype, args.num_layers, args.dropout
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.AdamW(model.parameters(), eps=1e-6)
|
||||||
|
scheduler = optim.lr_scheduler.OneCycleLR(
|
||||||
|
optimizer, args.max_lr, epochs=args.epochs, steps_per_epoch=len(train_loader),
|
||||||
|
pct_start=0.05, anneal_strategy='linear', final_div_factor=10.0
|
||||||
|
)
|
||||||
|
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
losses = []
|
||||||
|
for input_nodes, output_nodes, blocks in tqdm(train_loader):
|
||||||
|
batch_logits = model(blocks, blocks[0].srcdata['feat'])
|
||||||
|
batch_labels = labels[output_nodes[predict_ntype]]
|
||||||
|
loss = F.cross_entropy(batch_logits, batch_labels)
|
||||||
|
losses.append(loss.item())
|
||||||
|
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print('Epoch {:d} | Loss {:.4f}'.format(epoch, sum(losses) / len(losses)))
|
||||||
|
if epoch % args.eval_every == 0 or epoch == args.epochs - 1:
|
||||||
|
print(METRICS_STR.format(*evaluate(
|
||||||
|
model, loader, g, labels, data.num_classes, predict_ntype,
|
||||||
|
train_idx, val_idx, test_idx, evaluator
|
||||||
|
)))
|
||||||
|
if args.save_path:
|
||||||
|
torch.save(model.cpu().state_dict(), args.save_path)
|
||||||
|
print('模型已保存到', args.save_path)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练HGT模型')
|
||||||
|
parser.add_argument('--seed', type=int, default=1, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['ogbn-mag', 'oag-cs-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
parser.add_argument(
|
||||||
|
'--node-feat', choices=['average', 'pretrained'], default='pretrained',
|
||||||
|
help='如何获取无特征顶点的输入特征'
|
||||||
|
)
|
||||||
|
parser.add_argument('--node-embed-path', help='预训练顶点嵌入路径')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=512, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--epochs', type=int, default=100, help='训练epoch数')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=2048, help='批大小')
|
||||||
|
parser.add_argument('--neighbor-size', type=int, default=10, help='邻居采样数')
|
||||||
|
parser.add_argument('--max-lr', type=float, default=5e-4, help='学习率上界')
|
||||||
|
parser.add_argument('--eval-every', type=int, default=10, help='每多少个epoch计算一次准确率')
|
||||||
|
parser.add_argument('--save-path', help='模型保存路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,66 @@
|
||||||
|
import argparse
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
|
||||||
|
from gnnrec.hge.hgt.model import HGTFull
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, evaluate_full, \
|
||||||
|
METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, _ = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, 'one-hot')
|
||||||
|
|
||||||
|
model = HGTFull(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_heads, g.ntypes, g.canonical_etypes,
|
||||||
|
predict_ntype, args.num_layers, args.dropout
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.AdamW(model.parameters(), eps=1e-6)
|
||||||
|
scheduler = optim.lr_scheduler.OneCycleLR(
|
||||||
|
optimizer, args.max_lr, epochs=args.epochs, steps_per_epoch=1,
|
||||||
|
pct_start=0.05, anneal_strategy='linear', final_div_factor=10.0
|
||||||
|
)
|
||||||
|
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
logits = model(g, g.ndata['feat'])
|
||||||
|
loss = F.cross_entropy(logits[train_idx], labels[train_idx])
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print(('Epoch {:d} | Loss {:.4f} | ' + METRICS_STR).format(
|
||||||
|
epoch, loss.item(), *evaluate_full(model, g, labels, train_idx, val_idx, test_idx)
|
||||||
|
))
|
||||||
|
if args.save_path:
|
||||||
|
torch.save(model.cpu().state_dict(), args.save_path)
|
||||||
|
print('模型已保存到', args.save_path)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练HGT模型(full-batch)')
|
||||||
|
parser.add_argument('--seed', type=int, default=1, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['acm', 'dblp'], default='acm', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=512, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--epochs', type=int, default=10, help='训练epoch数')
|
||||||
|
parser.add_argument('--max-lr', type=float, default=5e-4, help='学习率上界')
|
||||||
|
parser.add_argument('--save-path', help='模型保存路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,56 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
from ogb.nodeproppred import DglNodePropPredDataset
|
||||||
|
from torch.utils.data import DataLoader
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR
|
||||||
|
from gnnrec.hge.utils import add_reverse_edges
|
||||||
|
|
||||||
|
|
||||||
|
def random_walk(g, metapaths, num_walks, walk_length, output_file):
|
||||||
|
"""在异构图上按指定的元路径随机游走,将轨迹保存到指定文件
|
||||||
|
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param metapaths: Dict[str, List[str]] 起点类型到元路径的映射,元路径表示为边类型列表,起点和终点类型应该相同
|
||||||
|
:param num_walks: int 每个顶点的游走次数
|
||||||
|
:param walk_length: int 元路径重复次数
|
||||||
|
:param output_file: str 输出文件名
|
||||||
|
:return:
|
||||||
|
"""
|
||||||
|
with open(output_file, 'w') as f:
|
||||||
|
for ntype, metapath in metapaths.items():
|
||||||
|
print(ntype)
|
||||||
|
loader = DataLoader(torch.arange(g.num_nodes(ntype)), batch_size=200)
|
||||||
|
for b in tqdm(loader):
|
||||||
|
nodes = torch.repeat_interleave(b, num_walks)
|
||||||
|
traces, types = dgl.sampling.random_walk(g, nodes, metapath=metapath * walk_length)
|
||||||
|
f.writelines([trace2name(g, trace, types) + '\n' for trace in traces])
|
||||||
|
|
||||||
|
|
||||||
|
def trace2name(g, trace, types):
|
||||||
|
return ' '.join(g.ntypes[t] + '_' + str(int(n)) for n, t in zip(trace, types) if int(n) >= 0)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='ogbn-mag数据集 metapath2vec基于元路径的随机游走')
|
||||||
|
parser.add_argument('--num-walks', type=int, default=5, help='每个顶点游走次数')
|
||||||
|
parser.add_argument('--walk-length', type=int, default=16, help='元路径重复次数')
|
||||||
|
parser.add_argument('output_file', help='输出文件名')
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
data = DglNodePropPredDataset('ogbn-mag', DATA_DIR)
|
||||||
|
g = add_reverse_edges(data[0][0])
|
||||||
|
metapaths = {
|
||||||
|
'author': ['writes', 'has_topic', 'has_topic_rev', 'writes_rev'], # APFPA
|
||||||
|
'paper': ['writes_rev', 'writes', 'has_topic', 'has_topic_rev'], # PAPFP
|
||||||
|
'field_of_study': ['has_topic_rev', 'writes_rev', 'writes', 'has_topic'], # FPAPF
|
||||||
|
'institution': ['affiliated_with_rev', 'writes', 'writes_rev', 'affiliated_with'] # IAPAI
|
||||||
|
}
|
||||||
|
random_walk(g, metapaths, args.num_walks, args.walk_length, args.output_file)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,27 @@
|
||||||
|
import argparse
|
||||||
|
import logging
|
||||||
|
|
||||||
|
from gensim.models import Word2Vec
|
||||||
|
|
||||||
|
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='metapath2vec训练word2vec')
|
||||||
|
parser.add_argument('--size', type=int, default=128, help='词向量维数')
|
||||||
|
parser.add_argument('--workers', type=int, default=3, help='工作线程数')
|
||||||
|
parser.add_argument('--iter', type=int, default=10, help='迭代次数')
|
||||||
|
parser.add_argument('corpus_file', help='语料库文件路径')
|
||||||
|
parser.add_argument('save_path', help='保存word2vec模型文件名')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
|
||||||
|
model = Word2Vec(
|
||||||
|
corpus_file=args.corpus_file, size=args.size, min_count=1,
|
||||||
|
workers=args.workers, sg=1, iter=args.iter
|
||||||
|
)
|
||||||
|
model.save(args.save_path)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,129 @@
|
||||||
|
# 异构图表示学习
|
||||||
|
## 数据集
|
||||||
|
* [ACM](https://github.com/liun-online/HeCo/tree/main/data/acm) - ACM学术网络数据集
|
||||||
|
* [DBLP](https://github.com/liun-online/HeCo/tree/main/data/dblp) - DBLP学术网络数据集
|
||||||
|
* [ogbn-mag](https://ogb.stanford.edu/docs/nodeprop/#ogbn-mag) - OGB提供的微软学术数据集
|
||||||
|
* [oag-venue](../kgrec/data/venue.py) - oag-cs期刊分类数据集
|
||||||
|
|
||||||
|
| 数据集 | 顶点数 | 边数 | 目标顶点 | 类别数 |
|
||||||
|
| --- | --- | --- | --- | --- |
|
||||||
|
| ACM | 11246 | 34852 | paper | 3 |
|
||||||
|
| DBLP | 26128 | 239566 | author | 4 |
|
||||||
|
| ogbn-mag | 1939743 | 21111007 | paper | 349 |
|
||||||
|
| oag-venue | 4235169 | 34520417 | paper | 360 |
|
||||||
|
|
||||||
|
## Baselines
|
||||||
|
* [R-GCN](https://arxiv.org/pdf/1703.06103)
|
||||||
|
* [HGT](https://arxiv.org/pdf/2003.01332)
|
||||||
|
* [HGConv](https://arxiv.org/pdf/2012.14722)
|
||||||
|
* [R-HGNN](https://arxiv.org/pdf/2105.11122)
|
||||||
|
* [C&S](https://arxiv.org/pdf/2010.13993)
|
||||||
|
* [HeCo](https://arxiv.org/pdf/2105.09111)
|
||||||
|
|
||||||
|
### R-GCN (full batch)
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.rgcn.train --dataset=acm --epochs=10
|
||||||
|
python -m gnnrec.hge.rgcn.train --dataset=dblp --epochs=10
|
||||||
|
python -m gnnrec.hge.rgcn.train --dataset=ogbn-mag --num-hidden=48
|
||||||
|
python -m gnnrec.hge.rgcn.train --dataset=oag-venue --num-hidden=48 --epochs=30
|
||||||
|
```
|
||||||
|
(使用minibatch训练准确率就是只有20%多,不知道为什么)
|
||||||
|
|
||||||
|
### 预训练顶点嵌入
|
||||||
|
使用metapath2vec(随机游走+word2vec)预训练顶点嵌入,作为GNN模型的顶点输入特征
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.metapath2vec.random_walk model/word2vec/ogbn-mag_corpus.txt
|
||||||
|
python -m gnnrec.hge.metapath2vec.train_word2vec --size=128 --workers=8 model/word2vec/ogbn-mag_corpus.txt model/word2vec/ogbn-mag.model
|
||||||
|
```
|
||||||
|
|
||||||
|
### HGT
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train_full --dataset=acm
|
||||||
|
python -m gnnrec.hge.hgt.train_full --dataset=dblp
|
||||||
|
python -m gnnrec.hge.hgt.train --dataset=ogbn-mag --node-embed-path=model/word2vec/ogbn-mag.model --epochs=40
|
||||||
|
python -m gnnrec.hge.hgt.train --dataset=oag-venue --node-embed-path=model/word2vec/oag-cs.model --epochs=40
|
||||||
|
```
|
||||||
|
|
||||||
|
### HGConv
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgconv.train_full --dataset=acm --epochs=5
|
||||||
|
python -m gnnrec.hge.hgconv.train_full --dataset=dblp --epochs=20
|
||||||
|
python -m gnnrec.hge.hgconv.train --dataset=ogbn-mag --node-embed-path=model/word2vec/ogbn-mag.model
|
||||||
|
python -m gnnrec.hge.hgconv.train --dataset=oag-venue --node-embed-path=model/word2vec/oag-cs.model
|
||||||
|
```
|
||||||
|
|
||||||
|
### R-HGNN
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.rhgnn.train_full --dataset=acm --num-layers=1 --epochs=15
|
||||||
|
python -m gnnrec.hge.rhgnn.train_full --dataset=dblp --epochs=20
|
||||||
|
python -m gnnrec.hge.rhgnn.train --dataset=ogbn-mag model/word2vec/ogbn-mag.model
|
||||||
|
python -m gnnrec.hge.rhgnn.train --dataset=oag-venue --epochs=50 model/word2vec/oag-cs.model
|
||||||
|
```
|
||||||
|
|
||||||
|
### C&S
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.cs.train --dataset=acm --epochs=5
|
||||||
|
python -m gnnrec.hge.cs.train --dataset=dblp --epochs=5
|
||||||
|
python -m gnnrec.hge.cs.train --dataset=ogbn-mag --prop-graph=data/graph/pos_graph_ogbn-mag_t5.bin
|
||||||
|
python -m gnnrec.hge.cs.train --dataset=oag-venue --prop-graph=data/graph/pos_graph_oag-venue_t5.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
### HeCo
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.heco.train --dataset=ogbn-mag model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5.bin
|
||||||
|
python -m gnnrec.hge.heco.train --dataset=oag-venue model/word2vec/oag-cs.model data/graph/pos_graph_oag-venue_t5.bin
|
||||||
|
```
|
||||||
|
(ACM和DBLP的数据来自 https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/heco ,准确率和Micro-F1相等)
|
||||||
|
|
||||||
|
## RHCO
|
||||||
|
基于对比学习的关系感知异构图神经网络(Relation-aware Heterogeneous Graph Neural Network with Contrastive Learning, RHCO)
|
||||||
|
|
||||||
|
在HeCo的基础上改进:
|
||||||
|
* 网络结构编码器中的注意力向量改为关系的表示(类似于R-HGNN)
|
||||||
|
* 正样本选择方式由元路径条数改为预训练的HGT计算的注意力权重、训练集使用真实标签
|
||||||
|
* 元路径视图编码器改为正样本图编码器,适配mini-batch训练
|
||||||
|
* Loss增加分类损失,训练方式由无监督改为半监督
|
||||||
|
* 在最后增加C&S后处理步骤
|
||||||
|
|
||||||
|
ACM
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train_full --dataset=acm --save-path=model/hgt/hgt_acm.pt
|
||||||
|
python -m gnnrec.hge.rhco.build_pos_graph_full --dataset=acm --num-samples=5 --use-label model/hgt/hgt_acm.pt data/graph/pos_graph_acm_t5l.bin
|
||||||
|
python -m gnnrec.hge.rhco.train_full --dataset=acm data/graph/pos_graph_acm_t5l.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
DBLP
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train_full --dataset=dblp --save-path=model/hgt/hgt_dblp.pt
|
||||||
|
python -m gnnrec.hge.rhco.build_pos_graph_full --dataset=dblp --num-samples=5 --use-label model/hgt/hgt_dblp.pt data/graph/pos_graph_dblp_t5l.bin
|
||||||
|
python -m gnnrec.hge.rhco.train_full --dataset=dblp --use-data-pos data/graph/pos_graph_dblp_t5l.bin
|
||||||
|
```
|
||||||
|
|
||||||
|
ogbn-mag(第3步如果中断可使用--load-path参数继续训练)
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train --dataset=ogbn-mag --node-embed-path=model/word2vec/ogbn-mag.model --epochs=40 --save-path=model/hgt/hgt_ogbn-mag.pt
|
||||||
|
python -m gnnrec.hge.rhco.build_pos_graph --dataset=ogbn-mag --num-samples=5 --use-label model/word2vec/ogbn-mag.model model/hgt/hgt_ogbn-mag.pt data/graph/pos_graph_ogbn-mag_t5l.bin
|
||||||
|
python -m gnnrec.hge.rhco.train --dataset=ogbn-mag --num-hidden=64 --contrast-weight=0.9 model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5l.bin model/rhco_ogbn-mag_d64_a0.9_t5l.pt
|
||||||
|
python -m gnnrec.hge.rhco.smooth --dataset=ogbn-mag model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5l.bin model/rhco_ogbn-mag_d64_a0.9_t5l.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
oag-venue
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.hgt.train --dataset=oag-venue --node-embed-path=model/word2vec/oag-cs.model --epochs=40 --save-path=model/hgt/hgt_oag-venue.pt
|
||||||
|
python -m gnnrec.hge.rhco.build_pos_graph --dataset=oag-venue --num-samples=5 --use-label model/word2vec/oag-cs.model model/hgt/hgt_oag-venue.pt data/graph/pos_graph_oag-venue_t5l.bin
|
||||||
|
python -m gnnrec.hge.rhco.train --dataset=oag-venue --num-hidden=64 --contrast-weight=0.9 model/word2vec/oag-cs.model data/graph/pos_graph_oag-venue_t5l.bin model/rhco_oag-venue.pt
|
||||||
|
python -m gnnrec.hge.rhco.smooth --dataset=oag-venue model/word2vec/oag-cs.model data/graph/pos_graph_oag-venue_t5l.bin model/rhco_oag-venue.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
消融实验
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.rhco.train --dataset=ogbn-mag --model=RHCO_sc model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5l.bin model/rhco_sc_ogbn-mag.pt
|
||||||
|
python -m gnnrec.hge.rhco.train --dataset=ogbn-mag --model=RHCO_pg model/word2vec/ogbn-mag.model data/graph/pos_graph_ogbn-mag_t5l.bin model/rhco_pg_ogbn-mag.pt
|
||||||
|
```
|
||||||
|
|
||||||
|
## 实验结果
|
||||||
|
[顶点分类](result/node_classification.csv)
|
||||||
|
|
||||||
|
[参数敏感性分析](result/param_analysis.csv)
|
||||||
|
|
||||||
|
[消融实验](result/ablation_study.csv)
|
||||||
|
|
|
|
@ -0,0 +1,9 @@
|
||||||
|
数据集,评价指标,R-GCN,HGT,HGConv,R-HGNN,C&S,HeCo,RHCO
|
||||||
|
ACM,准确率,0.7750,0.7660,0.7550,0.7220,0.7740,0.8850,0.7330->0.8200
|
||||||
|
ACM,Macro-F1,0.7556,0.7670,0.6978,0.6409,0.7780,0.8830,0.7050->0.8086
|
||||||
|
DBLP,准确率,0.9490,0.7860,0.9060,0.8680,0.7970,0.9070,0.8020->0.8840
|
||||||
|
DBLP,Macro-F1,0.9433,0.7837,0.8951,0.8591,0.7799,0.9032,0.7900->0.8732
|
||||||
|
ogbn-mag,准确率,0.3720,0.4497,0.4851,0.5201,0.3558,0.3043,0.5215->0.5662
|
||||||
|
ogbn-mag,Macro-F1,0.1970,0.2853,0.3148,0.3164,0.1863,0.0985,0.3105->0.3433
|
||||||
|
oag-venue,准确率,0.1577,0.8359,0.8144,0.9615,0.1392,0.1361,0.9607->0.9623
|
||||||
|
oag-venue,Macro-F1,0.1088,0.7628,0.7486,0.9057,0.0878,0.0681,0.8995->0.9186
|
||||||
|
|
|
@ -0,0 +1,6 @@
|
||||||
|
alpha,Accuracy_alpha,Macro-F1_alpha,Train-time_alpha(h),Tpos,Accuracy_Tpos,Macro-F1_Tpos,Train-time_Tpos(h),dimension,Accuracy_dimension,Macro-F1_dimension,Train-time_dimension(h)
|
||||||
|
0,0.5564,0.3434,24.8,3,0.5417,0.3210,16.1,16,0.5229,0.2612,14.6
|
||||||
|
0.2,0.5643,0.3440,24.8,5,0.5662,0.3433,24.8,32,0.5546,0.3169,17.9
|
||||||
|
0.5,0.5571,0.3415,24.8,10,0.5392,0.3181,40.2,64,0.5662,0.3433,24.8
|
||||||
|
0.8,0.5659,0.3371,24.8,,,,,128,0.5457,0.3389,55.4
|
||||||
|
0.9,0.5662,0.3433,24.8,,,,,,,,
|
||||||
|
|
|
@ -0,0 +1,34 @@
|
||||||
|
import matplotlib.pyplot as plt
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
from gnnrec.config import BASE_DIR
|
||||||
|
|
||||||
|
RESULT_DIR = BASE_DIR / 'gnnrec/hge/result'
|
||||||
|
|
||||||
|
|
||||||
|
def plot_param_analysis():
|
||||||
|
df = pd.read_csv(RESULT_DIR / 'param_analysis.csv')
|
||||||
|
params = ['alpha', 'Tpos', 'dimension']
|
||||||
|
|
||||||
|
for p in params:
|
||||||
|
fig, ax = plt.subplots()
|
||||||
|
x = df[p].dropna().to_numpy()
|
||||||
|
ax.plot(x, df[f'Accuracy_{p}'].dropna().to_numpy(), '.-', label='Accuracy')
|
||||||
|
ax.plot(x, df[f'Macro-F1_{p}'].dropna().to_numpy(), '*--', label='Macro-F1')
|
||||||
|
ax.set_xlabel(p)
|
||||||
|
ax.set_ylabel('Accuracy / Macro-F1')
|
||||||
|
|
||||||
|
ax2 = ax.twinx()
|
||||||
|
ax2.plot(x, df[f'Train-time_{p}(h)'].dropna().to_numpy(), 'x-.', label='Train time')
|
||||||
|
ax2.set_ylabel('Train time(h)')
|
||||||
|
|
||||||
|
fig.legend(loc='upper center')
|
||||||
|
fig.savefig(RESULT_DIR / f'param_analysis_{p}.png')
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
plot_param_analysis()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,95 @@
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from dgl.nn import HeteroGraphConv, GraphConv
|
||||||
|
|
||||||
|
|
||||||
|
class RelGraphConv(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, in_dim, out_dim, ntypes, etypes, activation=None, dropout=0.0):
|
||||||
|
"""R-GCN层(用于异构图)
|
||||||
|
|
||||||
|
:param in_dim: 输入特征维数
|
||||||
|
:param out_dim: 输出特征维数
|
||||||
|
:param ntypes: List[str] 顶点类型列表
|
||||||
|
:param etypes: List[str] 边类型列表
|
||||||
|
:param activation: callable, optional 激活函数,默认为None
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.activation = activation
|
||||||
|
self.dropout = nn.Dropout(dropout)
|
||||||
|
|
||||||
|
self.conv = HeteroGraphConv({
|
||||||
|
etype: GraphConv(in_dim, out_dim, norm='right', bias=False)
|
||||||
|
for etype in etypes
|
||||||
|
}, 'sum')
|
||||||
|
self.loop_weight = nn.ModuleDict({
|
||||||
|
ntype: nn.Linear(in_dim, out_dim, bias=False) for ntype in ntypes
|
||||||
|
})
|
||||||
|
|
||||||
|
def forward(self, g, feats):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in)] 顶点类型到输入特征的映射
|
||||||
|
:return: Dict[str, tensor(N_i, d_out)] 顶点类型到输出特征的映射
|
||||||
|
"""
|
||||||
|
if g.is_block:
|
||||||
|
feats_dst = {ntype: feat[:g.num_dst_nodes(ntype)] for ntype, feat in feats.items()}
|
||||||
|
else:
|
||||||
|
feats_dst = feats
|
||||||
|
out = self.conv(g, (feats, feats_dst)) # Dict[ntype, (N_i, d_out)]
|
||||||
|
for ntype in out:
|
||||||
|
out[ntype] += self.loop_weight[ntype](feats_dst[ntype])
|
||||||
|
if self.activation:
|
||||||
|
out[ntype] = self.activation(out[ntype])
|
||||||
|
out[ntype] = self.dropout(out[ntype])
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class RGCN(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, in_dim, hidden_dim, out_dim, input_ntypes, num_nodes, etypes, predict_ntype,
|
||||||
|
num_layers=2, dropout=0.0):
|
||||||
|
"""R-GCN模型
|
||||||
|
|
||||||
|
:param in_dim: int 输入特征维数
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param input_ntypes: List[str] 有输入特征的顶点类型列表
|
||||||
|
:param num_nodes: Dict[str, int] 顶点类型到顶点数的映射
|
||||||
|
:param etypes: List[str] 边类型列表
|
||||||
|
:param predict_ntype: str 待预测顶点类型
|
||||||
|
:param num_layers: int, optional 层数,默认为2
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.embeds = nn.ModuleDict({
|
||||||
|
ntype: nn.Embedding(num_nodes[ntype], in_dim)
|
||||||
|
for ntype in num_nodes if ntype not in input_ntypes
|
||||||
|
})
|
||||||
|
ntypes = list(num_nodes)
|
||||||
|
self.layers = nn.ModuleList()
|
||||||
|
self.layers.append(RelGraphConv(in_dim, hidden_dim, ntypes, etypes, F.relu, dropout))
|
||||||
|
for i in range(num_layers - 2):
|
||||||
|
self.layers.append(RelGraphConv(hidden_dim, hidden_dim, ntypes, etypes, F.relu, dropout))
|
||||||
|
self.layers.append(RelGraphConv(hidden_dim, out_dim, ntypes, etypes))
|
||||||
|
self.predict_ntype = predict_ntype
|
||||||
|
self.reset_parameters()
|
||||||
|
|
||||||
|
def reset_parameters(self):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
for k in self.embeds:
|
||||||
|
nn.init.xavier_uniform_(self.embeds[k].weight, gain=gain)
|
||||||
|
|
||||||
|
def forward(self, g, feats):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in_i)] (部分)顶点类型到输入特征的映射
|
||||||
|
:return: Dict[str, tensor(N_i, d_out)] 顶点类型到顶点嵌入的映射
|
||||||
|
"""
|
||||||
|
for k in self.embeds:
|
||||||
|
feats[k] = self.embeds[k].weight
|
||||||
|
for i in range(len(self.layers)):
|
||||||
|
feats = self.layers[i](g, feats) # Dict[ntype, (N_i, d_hid)]
|
||||||
|
return feats[self.predict_ntype]
|
||||||
|
|
@ -0,0 +1,60 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
|
||||||
|
from gnnrec.hge.rgcn.model import RGCN
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, calc_metrics, METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, features, labels, predict_ntype, train_idx, val_idx, test_idx, evaluator = \
|
||||||
|
load_data(args.dataset, device, reverse_self=False)
|
||||||
|
|
||||||
|
model = RGCN(
|
||||||
|
features.shape[1], args.num_hidden, data.num_classes, [predict_ntype],
|
||||||
|
{ntype: g.num_nodes(ntype) for ntype in g.ntypes}, g.etypes,
|
||||||
|
predict_ntype, args.num_layers, args.dropout
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr)
|
||||||
|
features = {predict_ntype: features}
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
logits = model(g, features)
|
||||||
|
loss = F.cross_entropy(logits[train_idx], labels[train_idx])
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
print(('Epoch {:d} | Loss {:.4f} | ' + METRICS_STR).format(
|
||||||
|
epoch, loss.item(),
|
||||||
|
*evaluate(model, g, features, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
))
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def evaluate(model, g, features, labels, train_idx, val_idx, test_idx, evaluator):
|
||||||
|
model.eval()
|
||||||
|
logits = model(g, features)
|
||||||
|
return calc_metrics(logits, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练R-GCN模型')
|
||||||
|
parser.add_argument('--seed', type=int, default=8, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['acm', 'dblp', 'ogbn-mag', 'oag-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=32, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='模型层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.8, help='Dropout概率')
|
||||||
|
parser.add_argument('--epochs', type=int, default=50, help='训练epoch数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.01, help='学习率')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,138 @@
|
||||||
|
import argparse
|
||||||
|
import random
|
||||||
|
from collections import defaultdict
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
from dgl.dataloading import MultiLayerNeighborSampler, NodeDataLoader
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from gnnrec.hge.hgt.model import HGT
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
print(args)
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, _ = load_data(args.dataset)
|
||||||
|
g = g.to(device)
|
||||||
|
labels = labels.tolist()
|
||||||
|
train_idx = torch.cat([train_idx, val_idx])
|
||||||
|
add_node_feat(g, 'pretrained', args.node_embed_path)
|
||||||
|
|
||||||
|
label_neigh = sample_label_neighbors(labels, args.num_samples) # (N, T_pos)
|
||||||
|
# List[tensor(N, T_pos)] HGT计算出的注意力权重,M条元路径+一个总体
|
||||||
|
attn_pos = calc_attn_pos(g, data.num_classes, predict_ntype, args.num_samples, device, args)
|
||||||
|
|
||||||
|
# 元路径对应的正样本图
|
||||||
|
v = torch.repeat_interleave(g.nodes(predict_ntype), args.num_samples).cpu()
|
||||||
|
pos_graphs = []
|
||||||
|
for p in attn_pos[:-1]:
|
||||||
|
u = p.view(1, -1).squeeze(dim=0) # (N*T_pos,)
|
||||||
|
pos_graphs.append(dgl.graph((u, v)))
|
||||||
|
|
||||||
|
# 整体正样本图
|
||||||
|
pos = attn_pos[-1]
|
||||||
|
if args.use_label:
|
||||||
|
pos[train_idx] = label_neigh[train_idx]
|
||||||
|
# pos[test_idx, 0] = label_neigh[test_idx, 0]
|
||||||
|
u = pos.view(1, -1).squeeze(dim=0)
|
||||||
|
pos_graphs.append(dgl.graph((u, v)))
|
||||||
|
|
||||||
|
dgl.save_graphs(args.save_graph_path, pos_graphs)
|
||||||
|
print('正样本图已保存到', args.save_graph_path)
|
||||||
|
|
||||||
|
|
||||||
|
def calc_attn_pos(g, num_classes, predict_ntype, num_samples, device, args):
|
||||||
|
"""使用预训练的HGT模型计算的注意力权重选择目标顶点的正样本。"""
|
||||||
|
# 第1层只保留AB边,第2层只保留BA边,其中A是目标顶点类型,B是中间顶点类型
|
||||||
|
num_neighbors = [{}, {}]
|
||||||
|
# 形如ABA的元路径,其中A是目标顶点类型
|
||||||
|
metapaths = []
|
||||||
|
rev_etype = {
|
||||||
|
e: next(re for rs, re, rd in g.canonical_etypes if rs == d and rd == s and re != e)
|
||||||
|
for s, e, d in g.canonical_etypes
|
||||||
|
}
|
||||||
|
for s, e, d in g.canonical_etypes:
|
||||||
|
if d == predict_ntype:
|
||||||
|
re = rev_etype[e]
|
||||||
|
num_neighbors[0][re] = num_neighbors[1][e] = 10
|
||||||
|
metapaths.append((re, e))
|
||||||
|
for i in range(len(num_neighbors)):
|
||||||
|
d = dict.fromkeys(g.etypes, 0)
|
||||||
|
d.update(num_neighbors[i])
|
||||||
|
num_neighbors[i] = d
|
||||||
|
sampler = MultiLayerNeighborSampler(num_neighbors)
|
||||||
|
loader = NodeDataLoader(
|
||||||
|
g, {predict_ntype: g.nodes(predict_ntype)}, sampler,
|
||||||
|
device=device, batch_size=args.batch_size
|
||||||
|
)
|
||||||
|
|
||||||
|
model = HGT(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, num_classes, args.num_heads, g.ntypes, g.canonical_etypes,
|
||||||
|
predict_ntype, 2, args.dropout
|
||||||
|
).to(device)
|
||||||
|
model.load_state_dict(torch.load(args.hgt_model_path, map_location=device))
|
||||||
|
|
||||||
|
# 每条元路径ABA对应一个正样本图G_ABA,加一个总体正样本图G_pos
|
||||||
|
pos = [
|
||||||
|
torch.zeros(g.num_nodes(predict_ntype), num_samples, dtype=torch.long, device=device)
|
||||||
|
for _ in range(len(metapaths) + 1)
|
||||||
|
]
|
||||||
|
with torch.no_grad():
|
||||||
|
for input_nodes, output_nodes, blocks in tqdm(loader):
|
||||||
|
_ = model(blocks, blocks[0].srcdata['feat'])
|
||||||
|
# List[tensor(N_src, N_dst)]
|
||||||
|
attn = [calc_attn(mp, model, blocks, device).t() for mp in metapaths]
|
||||||
|
for i in range(len(attn)):
|
||||||
|
_, nid = torch.topk(attn[i], num_samples) # (N_dst, T_pos)
|
||||||
|
# nid是blocks[0]中的源顶点id,将其转换为原异构图中的顶点id
|
||||||
|
pos[i][output_nodes[predict_ntype]] = input_nodes[predict_ntype][nid]
|
||||||
|
_, nid = torch.topk(sum(attn), num_samples)
|
||||||
|
pos[-1][output_nodes[predict_ntype]] = input_nodes[predict_ntype][nid]
|
||||||
|
return [p.cpu() for p in pos]
|
||||||
|
|
||||||
|
|
||||||
|
def calc_attn(metapath, model, blocks, device):
|
||||||
|
"""计算通过指定元路径与目标顶点连接的同类型顶点的注意力权重。"""
|
||||||
|
re, e = metapath
|
||||||
|
s, _, d = blocks[0].to_canonical_etype(re) # s是目标顶点类型, d是中间顶点类型
|
||||||
|
a0 = torch.zeros(blocks[0].num_src_nodes(s), blocks[0].num_dst_nodes(d), device=device)
|
||||||
|
a0[blocks[0].edges(etype=re)] = model.layers[0].conv.mods[re].attn.mean(dim=1)
|
||||||
|
a1 = torch.zeros(blocks[1].num_src_nodes(d), blocks[1].num_dst_nodes(s), device=device)
|
||||||
|
a1[blocks[1].edges(etype=e)] = model.layers[1].conv.mods[e].attn.mean(dim=1)
|
||||||
|
return torch.matmul(a0, a1) # (N_src, N_dst)
|
||||||
|
|
||||||
|
|
||||||
|
def sample_label_neighbors(labels, num_samples):
|
||||||
|
"""为每个顶点采样相同标签的邻居。"""
|
||||||
|
label2id = defaultdict(list)
|
||||||
|
for i, y in enumerate(labels):
|
||||||
|
label2id[y].append(i)
|
||||||
|
return torch.tensor([random.sample(label2id[y], num_samples) for y in labels])
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
parser = argparse.ArgumentParser(description='使用预训练的HGT计算的注意力权重构造正样本图')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['ogbn-mag', 'oag-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=512, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=256, help='批大小')
|
||||||
|
parser.add_argument('--num-samples', type=int, default=5, help='每个顶点采样的正样本数量')
|
||||||
|
parser.add_argument('--use-label', action='store_true', help='训练集使用真实标签')
|
||||||
|
parser.add_argument('node_embed_path', help='预训练顶点嵌入路径')
|
||||||
|
parser.add_argument('hgt_model_path', help='预训练的HGT模型保存路径')
|
||||||
|
parser.add_argument('save_graph_path', help='正样本图保存路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,107 @@
|
||||||
|
import argparse
|
||||||
|
import random
|
||||||
|
from collections import defaultdict
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
|
||||||
|
from gnnrec.hge.hgt.model import HGTFull
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
print(args)
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, _ = load_data(args.dataset)
|
||||||
|
g = g.to(device)
|
||||||
|
labels = labels.tolist()
|
||||||
|
train_idx = torch.cat([train_idx, val_idx])
|
||||||
|
add_node_feat(g, 'one-hot')
|
||||||
|
|
||||||
|
label_neigh = sample_label_neighbors(labels, args.num_samples) # (N, T_pos)
|
||||||
|
# List[tensor(N, T_pos)] HGT计算出的注意力权重,M条元路径+一个总体
|
||||||
|
attn_pos = calc_attn_pos(g, data.num_classes, predict_ntype, args.num_samples, device, args)
|
||||||
|
|
||||||
|
# 元路径对应的正样本图
|
||||||
|
v = torch.repeat_interleave(g.nodes(predict_ntype), args.num_samples).cpu()
|
||||||
|
pos_graphs = []
|
||||||
|
for p in attn_pos[:-1]:
|
||||||
|
u = p.view(1, -1).squeeze(dim=0) # (N*T_pos,)
|
||||||
|
pos_graphs.append(dgl.graph((u, v)))
|
||||||
|
|
||||||
|
# 整体正样本图
|
||||||
|
pos = attn_pos[-1]
|
||||||
|
if args.use_label:
|
||||||
|
pos[train_idx] = label_neigh[train_idx]
|
||||||
|
u = pos.view(1, -1).squeeze(dim=0)
|
||||||
|
pos_graphs.append(dgl.graph((u, v)))
|
||||||
|
|
||||||
|
dgl.save_graphs(args.save_graph_path, pos_graphs)
|
||||||
|
print('正样本图已保存到', args.save_graph_path)
|
||||||
|
|
||||||
|
|
||||||
|
def calc_attn_pos(g, num_classes, predict_ntype, num_samples, device, args):
|
||||||
|
"""使用预训练的HGT模型计算的注意力权重选择目标顶点的正样本。"""
|
||||||
|
# 形如ABA的元路径,其中A是目标顶点类型
|
||||||
|
metapaths = []
|
||||||
|
for s, e, d in g.canonical_etypes:
|
||||||
|
if d == predict_ntype:
|
||||||
|
re = next(re for rs, re, rd in g.canonical_etypes if rs == d and rd == s)
|
||||||
|
metapaths.append((re, e))
|
||||||
|
|
||||||
|
model = HGTFull(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, num_classes, args.num_heads, g.ntypes, g.canonical_etypes,
|
||||||
|
predict_ntype, 2, args.dropout
|
||||||
|
).to(device)
|
||||||
|
model.load_state_dict(torch.load(args.hgt_model_path, map_location=device))
|
||||||
|
|
||||||
|
# 每条元路径ABA对应一个正样本图G_ABA,加一个总体正样本图G_pos
|
||||||
|
with torch.no_grad():
|
||||||
|
_ = model(g, g.ndata['feat'])
|
||||||
|
attn = [calc_attn(mp, model, g, device).t() for mp in metapaths] # List[tensor(N, N)]
|
||||||
|
pos = [torch.topk(a, num_samples)[1] for a in attn] # List[tensor(N, T_pos)]
|
||||||
|
pos.append(torch.topk(sum(attn), num_samples)[1])
|
||||||
|
return [p.cpu() for p in pos]
|
||||||
|
|
||||||
|
|
||||||
|
def calc_attn(metapath, model, g, device):
|
||||||
|
"""计算通过指定元路径与目标顶点连接的同类型顶点的注意力权重。"""
|
||||||
|
re, e = metapath
|
||||||
|
s, _, d = g.to_canonical_etype(re) # s是目标顶点类型, d是中间顶点类型
|
||||||
|
a0 = torch.zeros(g.num_nodes(s), g.num_nodes(d), device=device)
|
||||||
|
a0[g.edges(etype=re)] = model.layers[0].conv.mods[re].attn.mean(dim=1)
|
||||||
|
a1 = torch.zeros(g.num_nodes(d), g.num_nodes(s), device=device)
|
||||||
|
a1[g.edges(etype=e)] = model.layers[1].conv.mods[e].attn.mean(dim=1)
|
||||||
|
return torch.matmul(a0, a1) # (N, N)
|
||||||
|
|
||||||
|
|
||||||
|
def sample_label_neighbors(labels, num_samples):
|
||||||
|
"""为每个顶点采样相同标签的邻居。"""
|
||||||
|
label2id = defaultdict(list)
|
||||||
|
for i, y in enumerate(labels):
|
||||||
|
label2id[y].append(i)
|
||||||
|
return torch.tensor([random.sample(label2id[y], num_samples) for y in labels])
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
parser = argparse.ArgumentParser(description='使用预训练的HGT计算的注意力权重构造正样本图(full-batch)')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['acm', 'dblp'], default='acm', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=512, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--num-samples', type=int, default=5, help='每个顶点采样的正样本数量')
|
||||||
|
parser.add_argument('--use-label', action='store_true', help='训练集使用真实标签')
|
||||||
|
parser.add_argument('hgt_model_path', help='预训练的HGT模型保存路径')
|
||||||
|
parser.add_argument('save_graph_path', help='正样本图保存路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
return args
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,126 @@
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
from dgl.dataloading import MultiLayerFullNeighborSampler, NodeDataLoader
|
||||||
|
|
||||||
|
from ..heco.model import PositiveGraphEncoder, Contrast
|
||||||
|
from ..rhgnn.model import RHGNN
|
||||||
|
|
||||||
|
|
||||||
|
class RHCO(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, in_dims, hidden_dim, out_dim, rel_hidden_dim, num_heads,
|
||||||
|
ntypes, etypes, predict_ntype, num_layers, dropout, num_pos_graphs, tau, lambda_):
|
||||||
|
"""基于对比学习的关系感知异构图神经网络RHCO
|
||||||
|
|
||||||
|
:param in_dims: Dict[str, int] 顶点类型到输入特征维数的映射
|
||||||
|
:param hidden_dim: int 隐含特征维数
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param rel_hidden_dim: int 关系隐含特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param ntypes: List[str] 顶点类型列表
|
||||||
|
:param etypes – List[(str, str, str)] 规范边类型列表
|
||||||
|
:param predict_ntype: str 目标顶点类型
|
||||||
|
:param num_layers: int 网络结构编码器层数
|
||||||
|
:param dropout: float 输入特征dropout
|
||||||
|
:param num_pos_graphs: int 正样本图个数M
|
||||||
|
:param tau: float 温度参数τ
|
||||||
|
:param lambda_: float 0~1之间,网络结构视图损失的系数λ(元路径视图损失的系数为1-λ)
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.hidden_dim = hidden_dim
|
||||||
|
self.predict_ntype = predict_ntype
|
||||||
|
self.sc_encoder = RHGNN(
|
||||||
|
in_dims, hidden_dim, hidden_dim, rel_hidden_dim, rel_hidden_dim, num_heads,
|
||||||
|
ntypes, etypes, predict_ntype, num_layers, dropout
|
||||||
|
)
|
||||||
|
self.pg_encoder = PositiveGraphEncoder(
|
||||||
|
num_pos_graphs, in_dims[predict_ntype], hidden_dim, dropout
|
||||||
|
)
|
||||||
|
self.contrast = Contrast(hidden_dim, tau, lambda_)
|
||||||
|
self.predict = nn.Linear(hidden_dim, out_dim)
|
||||||
|
self.reset_parameters()
|
||||||
|
|
||||||
|
def reset_parameters(self):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
nn.init.xavier_normal_(self.predict.weight, gain)
|
||||||
|
|
||||||
|
def forward(self, blocks, feats, mgs, mg_feats, pos):
|
||||||
|
"""
|
||||||
|
:param blocks: List[DGLBlock]
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in)] 顶点类型到输入特征的映射
|
||||||
|
:param mgs: List[DGLBlock] 正样本图,len(mgs)=元路径数量=目标顶点邻居类型数S≠模型层数
|
||||||
|
:param mg_feats: List[tensor(N_pos_src, d_in)] 正样本图源顶点的输入特征
|
||||||
|
:param pos: tensor(B, N) 布尔张量,每个顶点的正样本
|
||||||
|
(B是batch大小,真正的目标顶点;N是B个目标顶点加上其正样本后的顶点数)
|
||||||
|
:return: float, tensor(B, d_out) 对比损失,目标顶点输出特征
|
||||||
|
"""
|
||||||
|
z_sc = self.sc_encoder(blocks, feats) # (N, d_hid)
|
||||||
|
z_pg = self.pg_encoder(mgs, mg_feats) # (N, d_hid)
|
||||||
|
loss = self.contrast(z_sc, z_pg, pos)
|
||||||
|
return loss, self.predict(z_sc[:pos.shape[0]])
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def get_embeds(self, g, batch_size, device):
|
||||||
|
"""计算目标顶点的最终嵌入(z_sc)
|
||||||
|
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param batch_size: int 批大小
|
||||||
|
:param device torch.device GPU设备
|
||||||
|
:return: tensor(N_tgt, d_out) 目标顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
sampler = MultiLayerFullNeighborSampler(len(self.sc_encoder.layers))
|
||||||
|
loader = NodeDataLoader(
|
||||||
|
g, {self.predict_ntype: g.nodes(self.predict_ntype)}, sampler,
|
||||||
|
device=device, batch_size=batch_size
|
||||||
|
)
|
||||||
|
embeds = torch.zeros(g.num_nodes(self.predict_ntype), self.hidden_dim, device=device)
|
||||||
|
for input_nodes, output_nodes, blocks in loader:
|
||||||
|
z_sc = self.sc_encoder(blocks, blocks[0].srcdata['feat'])
|
||||||
|
embeds[output_nodes[self.predict_ntype]] = z_sc
|
||||||
|
return self.predict(embeds)
|
||||||
|
|
||||||
|
|
||||||
|
class RHCOFull(RHCO):
|
||||||
|
"""Full-batch RHCO"""
|
||||||
|
|
||||||
|
def forward(self, g, feats, mgs, mg_feat, pos):
|
||||||
|
return super().forward(
|
||||||
|
[g] * len(self.sc_encoder.layers), feats, mgs, [mg_feat] * len(mgs), pos
|
||||||
|
)
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def get_embeds(self, g, *args):
|
||||||
|
return self.predict(self.sc_encoder([g] * len(self.sc_encoder.layers), g.ndata['feat']))
|
||||||
|
|
||||||
|
|
||||||
|
class RHCOsc(RHCO):
|
||||||
|
"""RHCO消融实验变体:仅使用网络结构编码器"""
|
||||||
|
|
||||||
|
def forward(self, blocks, feats, mgs, mg_feats, pos):
|
||||||
|
z_sc = self.sc_encoder(blocks, feats) # (N, d_hid)
|
||||||
|
loss = self.contrast(z_sc, z_sc, pos)
|
||||||
|
return loss, self.predict(z_sc[:pos.shape[0]])
|
||||||
|
|
||||||
|
|
||||||
|
class RHCOpg(RHCO):
|
||||||
|
"""RHCO消融实验变体:仅使用正样本图编码器"""
|
||||||
|
|
||||||
|
def forward(self, blocks, feats, mgs, mg_feats, pos):
|
||||||
|
z_pg = self.pg_encoder(mgs, mg_feats) # (N, d_hid)
|
||||||
|
loss = self.contrast(z_pg, z_pg, pos)
|
||||||
|
return loss, self.predict(z_pg[:pos.shape[0]])
|
||||||
|
|
||||||
|
def get_embeds(self, mgs, feat, batch_size, device):
|
||||||
|
sampler = MultiLayerFullNeighborSampler(1)
|
||||||
|
mg_loaders = [
|
||||||
|
NodeDataLoader(mg, mg.nodes(self.predict_ntype), sampler, device=device, batch_size=batch_size)
|
||||||
|
for mg in mgs
|
||||||
|
]
|
||||||
|
embeds = torch.zeros(mgs[0].num_nodes(self.predict_ntype), self.hidden_dim, device=device)
|
||||||
|
for mg_blocks in zip(*mg_loaders):
|
||||||
|
output_nodes = mg_blocks[0][1]
|
||||||
|
mg_feats = [feat[i] for i, _, _ in mg_blocks]
|
||||||
|
mg_blocks = [b[0] for _, _, b in mg_blocks]
|
||||||
|
embeds[output_nodes] = self.pg_encoder(mg_blocks, mg_feats)
|
||||||
|
return self.predict(embeds)
|
||||||
|
|
@ -0,0 +1,75 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
|
||||||
|
from gnnrec.hge.cs.model import LabelPropagation
|
||||||
|
from gnnrec.hge.rhco.model import RHCO
|
||||||
|
from gnnrec.hge.utils import get_device, load_data, add_node_feat, calc_metrics
|
||||||
|
|
||||||
|
|
||||||
|
def smooth(base_pred, g, labels, mask, args):
|
||||||
|
cs = LabelPropagation(args.num_smooth_layers, args.smooth_alpha, args.smooth_norm)
|
||||||
|
labels = F.one_hot(labels).float()
|
||||||
|
base_pred[mask] = labels[mask]
|
||||||
|
return cs(g, base_pred)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
args = parse_args()
|
||||||
|
print(args)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, evaluator = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, 'pretrained', args.node_embed_path, True)
|
||||||
|
if args.dataset == 'oag-venue':
|
||||||
|
labels[labels == -1] = 0
|
||||||
|
(*mgs, pos_g), _ = dgl.load_graphs(args.pos_graph_path)
|
||||||
|
pos_g = pos_g.to(device)
|
||||||
|
|
||||||
|
model = RHCO(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_rel_hidden, args.num_heads,
|
||||||
|
g.ntypes, g.canonical_etypes, predict_ntype, args.num_layers, args.dropout,
|
||||||
|
len(mgs), args.tau, args.lambda_
|
||||||
|
).to(device)
|
||||||
|
model.load_state_dict(torch.load(args.model_path, map_location=device))
|
||||||
|
model.eval()
|
||||||
|
|
||||||
|
base_pred = model.get_embeds(g, args.neighbor_size, args.batch_size, device)
|
||||||
|
mask = torch.cat([train_idx, val_idx])
|
||||||
|
logits = smooth(base_pred, pos_g, labels, mask, args)
|
||||||
|
_, _, test_acc, _, _, test_f1 = calc_metrics(logits, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
print('After smoothing: Test Acc {:.4f} | Test Macro-F1 {:.4f}'.format(test_acc, test_f1))
|
||||||
|
|
||||||
|
|
||||||
|
def parse_args():
|
||||||
|
parser = argparse.ArgumentParser(description='RHCO+C&S(仅Smooth步骤)')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['ogbn-mag', 'oag-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
# RHCO
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=64, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-rel-hidden', type=int, default=8, help='关系表示的隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--tau', type=float, default=0.8, help='温度参数')
|
||||||
|
parser.add_argument('--lambda', type=float, default=0.5, dest='lambda_', help='对比损失的平衡系数')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=1024, help='批大小')
|
||||||
|
parser.add_argument('--neighbor-size', type=int, default=10, help='邻居采样数')
|
||||||
|
parser.add_argument('node_embed_path', help='预训练顶点嵌入路径')
|
||||||
|
parser.add_argument('pos_graph_path', help='正样本图保存路径')
|
||||||
|
parser.add_argument('model_path', help='预训练的模型保存路径')
|
||||||
|
# C&S
|
||||||
|
parser.add_argument('--num-smooth-layers', type=int, default=50, help='Smooth步骤传播层数')
|
||||||
|
parser.add_argument('--smooth-alpha', type=float, default=0.5, help='Smooth步骤α值')
|
||||||
|
parser.add_argument(
|
||||||
|
'--smooth-norm', choices=['left', 'right', 'both'], default='right',
|
||||||
|
help='Smooth步骤归一化方式'
|
||||||
|
)
|
||||||
|
return parser.parse_args()
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,127 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
from dgl.dataloading import NodeDataLoader
|
||||||
|
from torch.utils.data import DataLoader
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from gnnrec.hge.heco.sampler import PositiveSampler
|
||||||
|
from gnnrec.hge.rhco.model import RHCO, RHCOsc, RHCOpg
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, calc_metrics, \
|
||||||
|
METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def get_model_class(model):
|
||||||
|
return RHCOsc if model == 'RHCO_sc' else RHCOpg if model == 'RHCO_pg' else RHCO
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, evaluator = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, 'pretrained', args.node_embed_path, True)
|
||||||
|
features = g.nodes[predict_ntype].data['feat']
|
||||||
|
|
||||||
|
(*mgs, pos_g), _ = dgl.load_graphs(args.pos_graph_path)
|
||||||
|
mgs = [mg.to(device) for mg in mgs]
|
||||||
|
pos_g = pos_g.to(device)
|
||||||
|
pos = pos_g.in_edges(pos_g.nodes())[0].view(pos_g.num_nodes(), -1) # (N, T_pos) 每个目标顶点的正样本id
|
||||||
|
# 不能用pos_g.edges(),必须按终点id排序
|
||||||
|
|
||||||
|
id_loader = DataLoader(train_idx, batch_size=args.batch_size)
|
||||||
|
loader = NodeDataLoader(
|
||||||
|
g, {predict_ntype: train_idx}, PositiveSampler([args.neighbor_size] * args.num_layers, pos),
|
||||||
|
device=device, batch_size=args.batch_size
|
||||||
|
)
|
||||||
|
sampler = PositiveSampler([None], pos)
|
||||||
|
mg_loaders = [
|
||||||
|
NodeDataLoader(mg, train_idx, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
for mg in mgs
|
||||||
|
]
|
||||||
|
pos_loader = NodeDataLoader(pos_g, train_idx, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
|
||||||
|
model_class = get_model_class(args.model)
|
||||||
|
model = model_class(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_rel_hidden, args.num_heads,
|
||||||
|
g.ntypes, g.canonical_etypes, predict_ntype, args.num_layers, args.dropout,
|
||||||
|
len(mgs), args.tau, args.lambda_
|
||||||
|
).to(device)
|
||||||
|
if args.load_path:
|
||||||
|
model.load_state_dict(torch.load(args.load_path, map_location=device))
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr)
|
||||||
|
scheduler = optim.lr_scheduler.CosineAnnealingLR(
|
||||||
|
optimizer, T_max=len(loader) * args.epochs, eta_min=args.lr / 100
|
||||||
|
)
|
||||||
|
alpha = args.contrast_weight
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
losses = []
|
||||||
|
for (batch, (_, _, blocks), *mg_blocks, (_, _, pos_blocks)) in tqdm(zip(id_loader, loader, *mg_loaders, pos_loader)):
|
||||||
|
mg_feats = [features[i] for i, _, _ in mg_blocks]
|
||||||
|
mg_blocks = [b[0] for _, _, b in mg_blocks]
|
||||||
|
pos_block = pos_blocks[0]
|
||||||
|
# pos_block.num_dst_nodes() = batch_size + 正样本数
|
||||||
|
batch_pos = torch.zeros(pos_block.num_dst_nodes(), batch.shape[0], dtype=torch.int, device=device)
|
||||||
|
batch_pos[pos_block.in_edges(torch.arange(batch.shape[0], device=device))] = 1
|
||||||
|
contrast_loss, logits = model(blocks, blocks[0].srcdata['feat'], mg_blocks, mg_feats, batch_pos.t())
|
||||||
|
clf_loss = F.cross_entropy(logits, labels[batch])
|
||||||
|
loss = alpha * contrast_loss + (1 - alpha) * clf_loss
|
||||||
|
losses.append(loss.item())
|
||||||
|
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print('Epoch {:d} | Loss {:.4f}'.format(epoch, sum(losses) / len(losses)))
|
||||||
|
torch.save(model.state_dict(), args.save_path)
|
||||||
|
if epoch % args.eval_every == 0 or epoch == args.epochs - 1:
|
||||||
|
print(METRICS_STR.format(*evaluate(
|
||||||
|
model, g, args.batch_size, device, labels, train_idx, val_idx, test_idx, evaluator
|
||||||
|
)))
|
||||||
|
torch.save(model.state_dict(), args.save_path)
|
||||||
|
print('模型已保存到', args.save_path)
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def evaluate(model, g, batch_size, device, labels, train_idx, val_idx, test_idx, evaluator):
|
||||||
|
model.eval()
|
||||||
|
embeds = model.get_embeds(g, batch_size, device)
|
||||||
|
return calc_metrics(embeds, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练RHCO模型')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['ogbn-mag', 'oag-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
parser.add_argument('--model', choices=['RHCO', 'RHCO_sc', 'RHCO_pg'], default='RHCO', help='模型名称(用于消融实验)')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=64, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-rel-hidden', type=int, default=8, help='关系表示的隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--tau', type=float, default=0.8, help='温度参数')
|
||||||
|
parser.add_argument('--lambda', type=float, default=0.5, dest='lambda_', help='对比损失的平衡系数')
|
||||||
|
parser.add_argument('--epochs', type=int, default=150, help='训练epoch数')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=512, help='批大小')
|
||||||
|
parser.add_argument('--neighbor-size', type=int, default=10, help='邻居采样数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
|
||||||
|
parser.add_argument('--contrast-weight', type=float, default=0.9, help='对比损失权重')
|
||||||
|
parser.add_argument('--eval-every', type=int, default=10, help='每多少个epoch计算一次准确率')
|
||||||
|
parser.add_argument('--load-path', help='模型加载路径,用于继续训练')
|
||||||
|
parser.add_argument('node_embed_path', help='预训练顶点嵌入路径')
|
||||||
|
parser.add_argument('pos_graph_path', help='正样本图路径')
|
||||||
|
parser.add_argument('save_path', help='模型保存路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,100 @@
|
||||||
|
import argparse
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
|
||||||
|
from gnnrec.hge.rhco.model import RHCOFull
|
||||||
|
from gnnrec.hge.rhco.smooth import smooth
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, calc_metrics, \
|
||||||
|
METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, features, labels, predict_ntype, train_idx, val_idx, test_idx, _ = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, 'one-hot')
|
||||||
|
|
||||||
|
(*mgs, pos_g), _ = dgl.load_graphs(args.pos_graph_path)
|
||||||
|
mgs = [mg.to(device) for mg in mgs]
|
||||||
|
if args.use_data_pos:
|
||||||
|
pos_v, pos_u = data.pos
|
||||||
|
pos_g = dgl.graph((pos_u, pos_v), device=device)
|
||||||
|
pos = torch.zeros((g.num_nodes(predict_ntype), g.num_nodes(predict_ntype)), dtype=torch.int, device=device)
|
||||||
|
pos[data.pos] = 1
|
||||||
|
|
||||||
|
model = RHCOFull(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_rel_hidden, args.num_heads,
|
||||||
|
g.ntypes, g.canonical_etypes, predict_ntype, args.num_layers, args.dropout,
|
||||||
|
len(mgs), args.tau, args.lambda_
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr)
|
||||||
|
scheduler = optim.lr_scheduler.CosineAnnealingLR(
|
||||||
|
optimizer, T_max=args.epochs, eta_min=args.lr / 100
|
||||||
|
)
|
||||||
|
alpha = args.contrast_weight
|
||||||
|
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
contrast_loss, logits = model(g, g.ndata['feat'], mgs, features, pos)
|
||||||
|
clf_loss = F.cross_entropy(logits[train_idx], labels[train_idx])
|
||||||
|
loss = alpha * contrast_loss + (1 - alpha) * clf_loss
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print(('Epoch {:d} | Loss {:.4f} | ' + METRICS_STR).format(
|
||||||
|
epoch, loss.item(), *evaluate(model, g, labels, train_idx, val_idx, test_idx)
|
||||||
|
))
|
||||||
|
|
||||||
|
model.eval()
|
||||||
|
_, base_pred = model(g, g.ndata['feat'], mgs, features, pos)
|
||||||
|
mask = torch.cat([train_idx, val_idx])
|
||||||
|
logits = smooth(base_pred, pos_g, labels, mask, args)
|
||||||
|
_, _, test_acc, _, _, test_f1 = calc_metrics(logits, labels, train_idx, val_idx, test_idx)
|
||||||
|
print('After smoothing: Test Acc {:.4f} | Test Macro-F1 {:.4f}'.format(test_acc, test_f1))
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def evaluate(model, g, labels, train_idx, val_idx, test_idx):
|
||||||
|
model.eval()
|
||||||
|
embeds = model.get_embeds(g)
|
||||||
|
return calc_metrics(embeds, labels, train_idx, val_idx, test_idx)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练RHCO模型(full-batch)')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['acm', 'dblp'], default='acm', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=64, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-rel-hidden', type=int, default=8, help='关系表示的隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--tau', type=float, default=0.8, help='温度参数')
|
||||||
|
parser.add_argument('--lambda', type=float, default=0.5, dest='lambda_', help='对比损失的平衡系数')
|
||||||
|
parser.add_argument('--epochs', type=int, default=10, help='训练epoch数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
|
||||||
|
parser.add_argument('--contrast-weight', type=float, default=0.5, help='对比损失权重')
|
||||||
|
parser.add_argument('--num-smooth-layers', type=int, default=50, help='Smooth步骤传播层数')
|
||||||
|
parser.add_argument('--smooth-alpha', type=float, default=0.5, help='Smooth步骤α值')
|
||||||
|
parser.add_argument(
|
||||||
|
'--smooth-norm', choices=['left', 'right', 'both'], default='right',
|
||||||
|
help='Smooth步骤归一化方式'
|
||||||
|
)
|
||||||
|
parser.add_argument('--use-data-pos', action='store_true', help='使用数据集中的正样本图作为标签传播图')
|
||||||
|
parser.add_argument('pos_graph_path', help='正样本图路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,370 @@
|
||||||
|
import dgl.function as fn
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from dgl.ops import edge_softmax
|
||||||
|
from dgl.utils import expand_as_pair
|
||||||
|
|
||||||
|
|
||||||
|
class RelationGraphConv(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, out_dim, num_heads, fc_src, fc_dst, fc_rel,
|
||||||
|
feat_drop=0.0, negative_slope=0.2, activation=None):
|
||||||
|
"""特定关系的卷积
|
||||||
|
|
||||||
|
针对一种关系(边类型)R=<stype, etype, dtype>,聚集关系R下的邻居信息,得到dtype类型顶点在关系R下的表示,
|
||||||
|
注意力向量使用关系R的表示
|
||||||
|
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param fc_src: nn.Linear(d_in, K*d_out) 源顶点特征转换模块
|
||||||
|
:param fc_dst: nn.Linear(d_in, K*d_out) 目标顶点特征转换模块
|
||||||
|
:param fc_rel: nn.Linear(d_rel, 2*K*d_out) 关系表示转换模块
|
||||||
|
:param feat_drop: float, optional 输入特征Dropout概率,默认为0
|
||||||
|
:param negative_slope: float, optional LeakyReLU负斜率,默认为0.2
|
||||||
|
:param activation: callable, optional 用于输出特征的激活函数,默认为None
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.out_dim = out_dim
|
||||||
|
self.num_heads = num_heads
|
||||||
|
self.fc_src = fc_src
|
||||||
|
self.fc_dst = fc_dst
|
||||||
|
self.fc_rel = fc_rel
|
||||||
|
self.feat_drop = nn.Dropout(feat_drop)
|
||||||
|
self.leaky_relu = nn.LeakyReLU(negative_slope)
|
||||||
|
self.activation = activation
|
||||||
|
|
||||||
|
def forward(self, g, feat, feat_rel):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 二分图(只包含一种关系)
|
||||||
|
:param feat: tensor(N_src, d_in) or (tensor(N_src, d_in), tensor(N_dst, d_in)) 输入特征
|
||||||
|
:param feat_rel: tensor(d_rel) 关系R的表示
|
||||||
|
:return: tensor(N_dst, K*d_out) 目标顶点在关系R下的表示
|
||||||
|
"""
|
||||||
|
with g.local_scope():
|
||||||
|
feat_src, feat_dst = expand_as_pair(feat, g)
|
||||||
|
feat_src = self.fc_src(self.feat_drop(feat_src)).view(-1, self.num_heads, self.out_dim)
|
||||||
|
feat_dst = self.fc_dst(self.feat_drop(feat_dst)).view(-1, self.num_heads, self.out_dim)
|
||||||
|
attn = self.fc_rel(feat_rel).view(self.num_heads, 2 * self.out_dim)
|
||||||
|
|
||||||
|
# a^T (z_u || z_v) = (a_l^T || a_r^T) (z_u || z_v) = a_l^T z_u + a_r^T z_v = el + er
|
||||||
|
el = (feat_src * attn[:, :self.out_dim]).sum(dim=-1, keepdim=True) # (N_src, K, 1)
|
||||||
|
er = (feat_dst * attn[:, self.out_dim:]).sum(dim=-1, keepdim=True) # (N_dst, K, 1)
|
||||||
|
g.srcdata.update({'ft': feat_src, 'el': el})
|
||||||
|
g.dstdata['er'] = er
|
||||||
|
g.apply_edges(fn.u_add_v('el', 'er', 'e'))
|
||||||
|
e = self.leaky_relu(g.edata.pop('e'))
|
||||||
|
g.edata['a'] = edge_softmax(g, e) # (E, K, 1)
|
||||||
|
|
||||||
|
# 消息传递
|
||||||
|
g.update_all(fn.u_mul_e('ft', 'a', 'm'), fn.sum('m', 'ft'))
|
||||||
|
ret = g.dstdata['ft'].view(-1, self.num_heads * self.out_dim)
|
||||||
|
if self.activation:
|
||||||
|
ret = self.activation(ret)
|
||||||
|
return ret
|
||||||
|
|
||||||
|
|
||||||
|
class RelationCrossing(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, out_dim, num_heads, rel_attn, dropout=0.0, negative_slope=0.2):
|
||||||
|
"""跨关系消息传递
|
||||||
|
|
||||||
|
针对一种关系R=<stype, etype, dtype>,将dtype类型顶点在不同关系下的表示进行组合
|
||||||
|
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param rel_attn: nn.Parameter(K, d) 关系R的注意力向量
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
:param negative_slope: float, optional LeakyReLU负斜率,默认为0.2
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.out_dim = out_dim
|
||||||
|
self.num_heads = num_heads
|
||||||
|
self.rel_attn = rel_attn
|
||||||
|
self.dropout = nn.Dropout(dropout)
|
||||||
|
self.leaky_relu = nn.LeakyReLU(negative_slope)
|
||||||
|
|
||||||
|
def forward(self, feats):
|
||||||
|
"""
|
||||||
|
:param feats: tensor(N_R, N, K*d) dtype类型顶点在不同关系下的表示
|
||||||
|
:return: tensor(N, K*d) 跨关系消息传递后dtype类型顶点在关系R下的表示
|
||||||
|
"""
|
||||||
|
num_rel = feats.shape[0]
|
||||||
|
if num_rel == 1:
|
||||||
|
return feats.squeeze(dim=0)
|
||||||
|
feats = feats.view(num_rel, -1, self.num_heads, self.out_dim) # (N_R, N, K, d)
|
||||||
|
attn_scores = (self.rel_attn * feats).sum(dim=-1, keepdim=True)
|
||||||
|
attn_scores = F.softmax(self.leaky_relu(attn_scores), dim=0) # (N_R, N, K, 1)
|
||||||
|
out = (attn_scores * feats).sum(dim=0) # (N, K, d)
|
||||||
|
out = self.dropout(out.view(-1, self.num_heads * self.out_dim)) # (N, K*d)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class RelationFusing(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, node_hidden_dim, rel_hidden_dim, num_heads,
|
||||||
|
w_node, w_rel, dropout=0.0, negative_slope=0.2):
|
||||||
|
"""关系混合
|
||||||
|
|
||||||
|
针对一种顶点类型,将该类型顶点在不同关系下的表示进行组合
|
||||||
|
|
||||||
|
:param node_hidden_dim: int 顶点隐含特征维数
|
||||||
|
:param rel_hidden_dim: int 关系隐含特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param w_node: Dict[str, tensor(K, d_node, d_node)] 边类型到顶点关于该关系的特征转换矩阵的映射
|
||||||
|
:param w_rel: Dict[str, tensor(K, d_rel, d_node)] 边类型到关系的特征转换矩阵的映射
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
:param negative_slope: float, optional LeakyReLU负斜率,默认为0.2
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.node_hidden_dim = node_hidden_dim
|
||||||
|
self.rel_hidden_dim = rel_hidden_dim
|
||||||
|
self.num_heads = num_heads
|
||||||
|
self.w_node = nn.ParameterDict(w_node)
|
||||||
|
self.w_rel = nn.ParameterDict(w_rel)
|
||||||
|
self.dropout = nn.Dropout(dropout)
|
||||||
|
self.leaky_relu = nn.LeakyReLU(negative_slope)
|
||||||
|
|
||||||
|
def forward(self, node_feats, rel_feats):
|
||||||
|
"""
|
||||||
|
:param node_feats: Dict[str, tensor(N, K*d_node)] 边类型到顶点在该关系下的表示的映射
|
||||||
|
:param rel_feats: Dict[str, tensor(K*d_rel)] 边类型到关系的表示的映射
|
||||||
|
:return: tensor(N, K*d_node) 该类型顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
etypes = list(node_feats.keys())
|
||||||
|
num_rel = len(node_feats)
|
||||||
|
if num_rel == 1:
|
||||||
|
return node_feats[etypes[0]]
|
||||||
|
node_feats = torch.stack([node_feats[e] for e in etypes], dim=0) \
|
||||||
|
.reshape(num_rel, -1, self.num_heads, self.node_hidden_dim) # (N_R, N, K, d_node)
|
||||||
|
rel_feats = torch.stack([rel_feats[e] for e in etypes], dim=0) \
|
||||||
|
.reshape(num_rel, self.num_heads, self.rel_hidden_dim) # (N_R, K, d_rel)
|
||||||
|
w_node = torch.stack([self.w_node[e] for e in etypes], dim=0) # (N_R, K, d_node, d_node)
|
||||||
|
w_rel = torch.stack([self.w_rel[e] for e in etypes], dim=0) # (N_R, K, d_rel, d_node)
|
||||||
|
|
||||||
|
# hn[r, n, h] @= wn[r, h] => hn[r, n, h, i] = ∑(k) hn[r, n, h, k] * wn[r, h, k, i]
|
||||||
|
node_feats = torch.einsum('rnhk,rhki->rnhi', node_feats, w_node) # (N_R, N, K, d_node)
|
||||||
|
# hr[r, h] @= wr[r, h] => hr[r, h, i] = ∑(k) hr[r, h, k] * wr[r, h, k, i]
|
||||||
|
rel_feats = torch.einsum('rhk,rhki->rhi', rel_feats, w_rel) # (N_R, K, d_node)
|
||||||
|
|
||||||
|
attn_scores = (node_feats * rel_feats.unsqueeze(dim=1)).sum(dim=-1, keepdim=True)
|
||||||
|
attn_scores = F.softmax(self.leaky_relu(attn_scores), dim=0) # (N_R, N, K, 1)
|
||||||
|
out = (attn_scores * node_feats).sum(dim=0) # (N_R, N, K, d_node)
|
||||||
|
out = self.dropout(out.view(-1, self.num_heads * self.node_hidden_dim)) # (N, K*d_node)
|
||||||
|
return out
|
||||||
|
|
||||||
|
|
||||||
|
class RHGNNLayer(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, node_in_dim, node_out_dim, rel_in_dim, rel_out_dim, num_heads,
|
||||||
|
ntypes, etypes, dropout=0.0, negative_slope=0.2, residual=True):
|
||||||
|
"""R-HGNN层
|
||||||
|
|
||||||
|
:param node_in_dim: int 顶点输入特征维数
|
||||||
|
:param node_out_dim: int 顶点输出特征维数
|
||||||
|
:param rel_in_dim: int 关系输入特征维数
|
||||||
|
:param rel_out_dim: int 关系输出特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param ntypes: List[str] 顶点类型列表
|
||||||
|
:param etypes: List[(str, str, str)] 规范边类型列表
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
:param negative_slope: float, optional LeakyReLU负斜率,默认为0.2
|
||||||
|
:param residual: bool, optional 是否使用残差连接,默认True
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
# 特定关系的卷积的参数
|
||||||
|
fc_node = {
|
||||||
|
ntype: nn.Linear(node_in_dim, num_heads * node_out_dim, bias=False)
|
||||||
|
for ntype in ntypes
|
||||||
|
}
|
||||||
|
fc_rel = {
|
||||||
|
etype: nn.Linear(rel_in_dim, 2 * num_heads * node_out_dim, bias=False)
|
||||||
|
for _, etype, _ in etypes
|
||||||
|
}
|
||||||
|
self.rel_graph_conv = nn.ModuleDict({
|
||||||
|
etype: RelationGraphConv(
|
||||||
|
node_out_dim, num_heads, fc_node[stype], fc_node[dtype], fc_rel[etype],
|
||||||
|
dropout, negative_slope, F.relu
|
||||||
|
) for stype, etype, dtype in etypes
|
||||||
|
})
|
||||||
|
|
||||||
|
# 残差连接的参数
|
||||||
|
self.residual = residual
|
||||||
|
if residual:
|
||||||
|
self.fc_res = nn.ModuleDict({
|
||||||
|
ntype: nn.Linear(node_in_dim, num_heads * node_out_dim) for ntype in ntypes
|
||||||
|
})
|
||||||
|
self.res_weight = nn.ParameterDict({
|
||||||
|
ntype: nn.Parameter(torch.rand(1)) for ntype in ntypes
|
||||||
|
})
|
||||||
|
|
||||||
|
# 关系表示学习的参数
|
||||||
|
self.fc_upd = nn.ModuleDict({
|
||||||
|
etype: nn.Linear(rel_in_dim, num_heads * rel_out_dim)
|
||||||
|
for _, etype, _ in etypes
|
||||||
|
})
|
||||||
|
|
||||||
|
# 跨关系消息传递的参数
|
||||||
|
rel_attn = {
|
||||||
|
etype: nn.Parameter(torch.FloatTensor(num_heads, node_out_dim))
|
||||||
|
for _, etype, _ in etypes
|
||||||
|
}
|
||||||
|
self.rel_cross = nn.ModuleDict({
|
||||||
|
etype: RelationCrossing(
|
||||||
|
node_out_dim, num_heads, rel_attn[etype], dropout, negative_slope
|
||||||
|
) for _, etype, _ in etypes
|
||||||
|
})
|
||||||
|
|
||||||
|
self.rev_etype = {
|
||||||
|
e: next(re for rs, re, rd in etypes if rs == d and rd == s and re != e)
|
||||||
|
for s, e, d in etypes
|
||||||
|
}
|
||||||
|
self.reset_parameters(rel_attn)
|
||||||
|
|
||||||
|
def reset_parameters(self, rel_attn):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
for etype in rel_attn:
|
||||||
|
nn.init.xavier_normal_(rel_attn[etype], gain=gain)
|
||||||
|
|
||||||
|
def forward(self, g, feats, rel_feats):
|
||||||
|
"""
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param feats: Dict[(str, str, str), tensor(N_i, d_in)] 关系(三元组)到目标顶点输入特征的映射
|
||||||
|
:param rel_feats: Dict[str, tensor(d_in_rel)] 边类型到输入关系特征的映射
|
||||||
|
:return: Dict[(str, str, str), tensor(N_i, K*d_out)], Dict[str, tensor(K*d_out_rel)]
|
||||||
|
关系(三元组)到目标顶点在该关系下的表示的映射、边类型到关系表示的映射
|
||||||
|
"""
|
||||||
|
if g.is_block:
|
||||||
|
feats_dst = {r: feats[r][:g.num_dst_nodes(r[2])] for r in feats}
|
||||||
|
else:
|
||||||
|
feats_dst = feats
|
||||||
|
|
||||||
|
node_rel_feats = {
|
||||||
|
(stype, etype, dtype): self.rel_graph_conv[etype](
|
||||||
|
g[stype, etype, dtype],
|
||||||
|
(feats[(dtype, self.rev_etype[etype], stype)], feats_dst[(stype, etype, dtype)]),
|
||||||
|
rel_feats[etype]
|
||||||
|
) for stype, etype, dtype in g.canonical_etypes
|
||||||
|
if g.num_edges((stype, etype, dtype)) > 0
|
||||||
|
} # {rel: tensor(N_dst, K*d_out)}
|
||||||
|
|
||||||
|
if self.residual:
|
||||||
|
for stype, etype, dtype in node_rel_feats:
|
||||||
|
alpha = torch.sigmoid(self.res_weight[dtype])
|
||||||
|
inherit_feat = self.fc_res[dtype](feats_dst[(stype, etype, dtype)])
|
||||||
|
node_rel_feats[(stype, etype, dtype)] = \
|
||||||
|
alpha * node_rel_feats[(stype, etype, dtype)] + (1 - alpha) * inherit_feat
|
||||||
|
|
||||||
|
out_feats = {} # {rel: tensor(N_dst, K*d_out)}
|
||||||
|
for stype, etype, dtype in node_rel_feats:
|
||||||
|
dst_node_rel_feats = torch.stack([
|
||||||
|
node_rel_feats[r] for r in node_rel_feats if r[2] == dtype
|
||||||
|
], dim=0) # (N_Ri, N_i, K*d_out)
|
||||||
|
out_feats[(stype, etype, dtype)] = self.rel_cross[etype](dst_node_rel_feats)
|
||||||
|
|
||||||
|
rel_feats = {etype: self.fc_upd[etype](rel_feats[etype]) for etype in rel_feats}
|
||||||
|
return out_feats, rel_feats
|
||||||
|
|
||||||
|
|
||||||
|
class RHGNN(nn.Module):
|
||||||
|
|
||||||
|
def __init__(
|
||||||
|
self, in_dims, hidden_dim, out_dim, rel_in_dim, rel_hidden_dim, num_heads, ntypes,
|
||||||
|
etypes, predict_ntype, num_layers, dropout=0.0, negative_slope=0.2, residual=True):
|
||||||
|
"""R-HGNN模型
|
||||||
|
|
||||||
|
:param in_dims: Dict[str, int] 顶点类型到输入特征维数的映射
|
||||||
|
:param hidden_dim: int 顶点隐含特征维数
|
||||||
|
:param out_dim: int 顶点输出特征维数
|
||||||
|
:param rel_in_dim: int 关系输入特征维数
|
||||||
|
:param rel_hidden_dim: int 关系隐含特征维数
|
||||||
|
:param num_heads: int 注意力头数K
|
||||||
|
:param ntypes: List[str] 顶点类型列表
|
||||||
|
:param etypes: List[(str, str, str)] 规范边类型列表
|
||||||
|
:param predict_ntype: str 待预测顶点类型
|
||||||
|
:param num_layers: int 层数
|
||||||
|
:param dropout: float, optional Dropout概率,默认为0
|
||||||
|
:param negative_slope: float, optional LeakyReLU负斜率,默认为0.2
|
||||||
|
:param residual: bool, optional 是否使用残差连接,默认True
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self._d = num_heads * hidden_dim
|
||||||
|
self.etypes = etypes
|
||||||
|
self.predict_ntype = predict_ntype
|
||||||
|
# 对齐输入特征维数
|
||||||
|
self.fc_in = nn.ModuleDict({
|
||||||
|
ntype: nn.Linear(in_dim, num_heads * hidden_dim) for ntype, in_dim in in_dims.items()
|
||||||
|
})
|
||||||
|
# 关系输入特征
|
||||||
|
self.rel_embed = nn.ParameterDict({
|
||||||
|
etype: nn.Parameter(torch.FloatTensor(1, rel_in_dim)) for _, etype, _ in etypes
|
||||||
|
})
|
||||||
|
|
||||||
|
self.layers = nn.ModuleList()
|
||||||
|
self.layers.append(RHGNNLayer(
|
||||||
|
num_heads * hidden_dim, hidden_dim, rel_in_dim, rel_hidden_dim,
|
||||||
|
num_heads, ntypes, etypes, dropout, negative_slope, residual
|
||||||
|
))
|
||||||
|
for _ in range(1, num_layers):
|
||||||
|
self.layers.append(RHGNNLayer(
|
||||||
|
num_heads * hidden_dim, hidden_dim, num_heads * rel_hidden_dim, rel_hidden_dim,
|
||||||
|
num_heads, ntypes, etypes, dropout, negative_slope, residual
|
||||||
|
))
|
||||||
|
|
||||||
|
w_node = {
|
||||||
|
etype: nn.Parameter(torch.FloatTensor(num_heads, hidden_dim, hidden_dim))
|
||||||
|
for _, etype, _ in etypes
|
||||||
|
}
|
||||||
|
w_rel = {
|
||||||
|
etype: nn.Parameter(torch.FloatTensor(num_heads, rel_hidden_dim, hidden_dim))
|
||||||
|
for _, etype, _ in etypes
|
||||||
|
}
|
||||||
|
self.rel_fusing = nn.ModuleDict({
|
||||||
|
ntype: RelationFusing(
|
||||||
|
hidden_dim, rel_hidden_dim, num_heads,
|
||||||
|
{e: w_node[e] for _, e, d in etypes if d == ntype},
|
||||||
|
{e: w_rel[e] for _, e, d in etypes if d == ntype},
|
||||||
|
dropout, negative_slope
|
||||||
|
) for ntype in ntypes
|
||||||
|
})
|
||||||
|
self.classifier = nn.Linear(num_heads * hidden_dim, out_dim)
|
||||||
|
self.reset_parameters(self.rel_embed, w_node, w_rel)
|
||||||
|
|
||||||
|
def reset_parameters(self, rel_embed, w_node, w_rel):
|
||||||
|
gain = nn.init.calculate_gain('relu')
|
||||||
|
for etype in rel_embed:
|
||||||
|
nn.init.xavier_normal_(rel_embed[etype], gain=gain)
|
||||||
|
nn.init.xavier_normal_(w_node[etype], gain=gain)
|
||||||
|
nn.init.xavier_normal_(w_rel[etype], gain=gain)
|
||||||
|
|
||||||
|
def forward(self, blocks, feats):
|
||||||
|
"""
|
||||||
|
:param blocks: blocks: List[DGLBlock]
|
||||||
|
:param feats: Dict[str, tensor(N_i, d_in_i)] 顶点类型到输入顶点特征的映射
|
||||||
|
:return: tensor(N_i, d_out) 待预测顶点的最终嵌入
|
||||||
|
"""
|
||||||
|
feats = {
|
||||||
|
(stype, etype, dtype): self.fc_in[dtype](feats[dtype])
|
||||||
|
for stype, etype, dtype in self.etypes
|
||||||
|
}
|
||||||
|
rel_feats = {rel: emb.flatten() for rel, emb in self.rel_embed.items()}
|
||||||
|
for block, layer in zip(blocks, self.layers):
|
||||||
|
# {(stype, etype, dtype): tensor(N_i, K*d_hid)}, {etype: tensor(K*d_hid_rel)}
|
||||||
|
feats, rel_feats = layer(block, feats, rel_feats)
|
||||||
|
|
||||||
|
out_feats = {
|
||||||
|
ntype: self.rel_fusing[ntype](
|
||||||
|
{e: feats[(s, e, d)] for s, e, d in feats if d == ntype},
|
||||||
|
{e: rel_feats[e] for s, e, d in feats if d == ntype}
|
||||||
|
) for ntype in set(d for _, _, d in feats)
|
||||||
|
} # {ntype: tensor(N_i, K*d_hid)}
|
||||||
|
return self.classifier(out_feats[self.predict_ntype])
|
||||||
|
|
||||||
|
|
||||||
|
class RHGNNFull(RHGNN):
|
||||||
|
|
||||||
|
def forward(self, g, feats):
|
||||||
|
return super().forward([g] * len(self.layers), feats)
|
||||||
|
|
@ -0,0 +1,85 @@
|
||||||
|
import argparse
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
from dgl.dataloading import MultiLayerNeighborSampler, NodeDataLoader
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from gnnrec.hge.rhgnn.model import RHGNN
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, evaluate, \
|
||||||
|
METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, evaluator = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, 'pretrained', args.node_embed_path, True)
|
||||||
|
|
||||||
|
sampler = MultiLayerNeighborSampler(list(range(args.neighbor_size, args.neighbor_size + args.num_layers)))
|
||||||
|
train_loader = NodeDataLoader(g, {predict_ntype: train_idx}, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
loader = NodeDataLoader(g, {predict_ntype: g.nodes(predict_ntype)}, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
|
||||||
|
model = RHGNN(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_rel_hidden, args.num_rel_hidden, args.num_heads,
|
||||||
|
g.ntypes, g.canonical_etypes, predict_ntype, args.num_layers, args.dropout
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
|
||||||
|
scheduler = optim.lr_scheduler.CosineAnnealingLR(
|
||||||
|
optimizer, T_max=len(train_loader) * args.epochs, eta_min=args.lr / 100
|
||||||
|
)
|
||||||
|
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
losses = []
|
||||||
|
for input_nodes, output_nodes, blocks in tqdm(train_loader):
|
||||||
|
batch_logits = model(blocks, blocks[0].srcdata['feat'])
|
||||||
|
batch_labels = labels[output_nodes[predict_ntype]]
|
||||||
|
loss = F.cross_entropy(batch_logits, batch_labels)
|
||||||
|
losses.append(loss.item())
|
||||||
|
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print('Epoch {:d} | Loss {:.4f}'.format(epoch, sum(losses) / len(losses)))
|
||||||
|
if epoch % args.eval_every == 0 or epoch == args.epochs - 1:
|
||||||
|
print(METRICS_STR.format(*evaluate(
|
||||||
|
model, loader, g, labels, data.num_classes, predict_ntype,
|
||||||
|
train_idx, val_idx, test_idx, evaluator
|
||||||
|
)))
|
||||||
|
if args.save_path:
|
||||||
|
torch.save(model.cpu().state_dict(), args.save_path)
|
||||||
|
print('模型已保存到', args.save_path)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练R-HGNN模型')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['ogbn-mag', 'oag-venue'], default='ogbn-mag', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=64, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-rel-hidden', type=int, default=8, help='关系表示的隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--epochs', type=int, default=200, help='训练epoch数')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=1024, help='批大小')
|
||||||
|
parser.add_argument('--neighbor-size', type=int, default=10, help='邻居采样数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
|
||||||
|
parser.add_argument('--weight-decay', type=float, default=0.0, help='权重衰减')
|
||||||
|
parser.add_argument('--eval-every', type=int, default=10, help='每多少个epoch计算一次准确率')
|
||||||
|
parser.add_argument('--save-path', help='模型保存路径')
|
||||||
|
parser.add_argument('node_embed_path', help='预训练顶点嵌入路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,63 @@
|
||||||
|
import argparse
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn.functional as F
|
||||||
|
import torch.optim as optim
|
||||||
|
|
||||||
|
from gnnrec.hge.rhgnn.model import RHGNNFull
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, load_data, add_node_feat, evaluate_full, \
|
||||||
|
METRICS_STR
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
data, g, _, labels, predict_ntype, train_idx, val_idx, test_idx, _ = \
|
||||||
|
load_data(args.dataset, device)
|
||||||
|
add_node_feat(g, 'one-hot')
|
||||||
|
|
||||||
|
model = RHGNNFull(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, data.num_classes, args.num_rel_hidden, args.num_rel_hidden, args.num_heads,
|
||||||
|
g.ntypes, g.canonical_etypes, predict_ntype, args.num_layers, args.dropout
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
|
||||||
|
scheduler = optim.lr_scheduler.CosineAnnealingLR(
|
||||||
|
optimizer, T_max=args.epochs, eta_min=args.lr / 100
|
||||||
|
)
|
||||||
|
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
logits = model(g, g.ndata['feat'])
|
||||||
|
loss = F.cross_entropy(logits[train_idx], labels[train_idx])
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print(('Epoch {:d} | Loss {:.4f} | ' + METRICS_STR).format(
|
||||||
|
epoch, loss.item(), *evaluate_full(model, g, labels, train_idx, val_idx, test_idx)
|
||||||
|
))
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='训练R-HGNN模型(full-batch)')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
parser.add_argument('--dataset', choices=['acm', 'dblp'], default='acm', help='数据集')
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=64, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-rel-hidden', type=int, default=8, help='关系表示的隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--epochs', type=int, default=10, help='训练epoch数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
|
||||||
|
parser.add_argument('--weight-decay', type=float, default=0.0, help='权重衰减')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,28 @@
|
||||||
|
import random
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
|
||||||
|
from .data import *
|
||||||
|
from .metrics import *
|
||||||
|
|
||||||
|
|
||||||
|
def set_random_seed(seed):
|
||||||
|
"""设置Python, numpy, PyTorch的随机数种子
|
||||||
|
|
||||||
|
:param seed: int 随机数种子
|
||||||
|
"""
|
||||||
|
random.seed(seed)
|
||||||
|
np.random.seed(seed)
|
||||||
|
torch.manual_seed(seed)
|
||||||
|
if torch.cuda.is_available():
|
||||||
|
torch.cuda.manual_seed(seed)
|
||||||
|
dgl.seed(seed)
|
||||||
|
|
||||||
|
|
||||||
|
def get_device(device):
|
||||||
|
"""返回指定的GPU设备
|
||||||
|
|
||||||
|
:param device: int GPU编号,-1表示CPU
|
||||||
|
:return: torch.device
|
||||||
|
"""
|
||||||
|
return torch.device(f'cuda:{device}' if device >= 0 and torch.cuda.is_available() else 'cpu')
|
||||||
|
|
@ -0,0 +1,138 @@
|
||||||
|
import dgl
|
||||||
|
import dgl.function as fn
|
||||||
|
import torch
|
||||||
|
from gensim.models import Word2Vec
|
||||||
|
from ogb.nodeproppred import DglNodePropPredDataset, Evaluator
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR
|
||||||
|
from gnnrec.hge.data import ACMDataset, DBLPDataset
|
||||||
|
from gnnrec.kgrec.data import OAGVenueDataset
|
||||||
|
|
||||||
|
|
||||||
|
def load_data(name, device='cpu', add_reverse_edge=True, reverse_self=True):
|
||||||
|
"""加载数据集
|
||||||
|
|
||||||
|
:param name: str 数据集名称 acm, dblp, ogbn-mag, oag-venue
|
||||||
|
:param device: torch.device, optional 将图和数据移动到指定的设备上,默认为CPU
|
||||||
|
:param add_reverse_edge: bool, optional 是否添加反向边,默认为True
|
||||||
|
:param reverse_self: bool, optional 起点和终点类型相同时是否添加反向边,默认为True
|
||||||
|
:return: dataset, g, features, labels, predict_ntype, train_mask, val_mask, test_mask, evaluator
|
||||||
|
"""
|
||||||
|
if name == 'ogbn-mag':
|
||||||
|
return load_ogbn_mag(device, add_reverse_edge, reverse_self)
|
||||||
|
elif name == 'acm':
|
||||||
|
data = ACMDataset()
|
||||||
|
elif name == 'dblp':
|
||||||
|
data = DBLPDataset()
|
||||||
|
elif name == 'oag-venue':
|
||||||
|
data = OAGVenueDataset()
|
||||||
|
else:
|
||||||
|
raise ValueError(f'load_data: 未知数据集{name}')
|
||||||
|
g = data[0]
|
||||||
|
predict_ntype = data.predict_ntype
|
||||||
|
# ACM和DBLP数据集已添加反向边
|
||||||
|
if add_reverse_edge and name not in ('acm', 'dblp'):
|
||||||
|
g = add_reverse_edges(g, reverse_self)
|
||||||
|
g = g.to(device)
|
||||||
|
features = g.nodes[predict_ntype].data['feat']
|
||||||
|
labels = g.nodes[predict_ntype].data['label']
|
||||||
|
train_mask = g.nodes[predict_ntype].data['train_mask'].nonzero(as_tuple=True)[0]
|
||||||
|
val_mask = g.nodes[predict_ntype].data['val_mask'].nonzero(as_tuple=True)[0]
|
||||||
|
test_mask = g.nodes[predict_ntype].data['test_mask'].nonzero(as_tuple=True)[0]
|
||||||
|
return data, g, features, labels, predict_ntype, train_mask, val_mask, test_mask, None
|
||||||
|
|
||||||
|
|
||||||
|
def load_ogbn_mag(device, add_reverse_edge, reverse_self):
|
||||||
|
"""加载ogbn-mag数据集
|
||||||
|
|
||||||
|
:param device: torch.device 将图和数据移动到指定的设备上,默认为CPU
|
||||||
|
:param add_reverse_edge: bool 是否添加反向边
|
||||||
|
:param reverse_self: bool 起点和终点类型相同时是否添加反向边
|
||||||
|
:return: dataset, g, features, labels, predict_ntype, train_mask, val_mask, test_mask, evaluator
|
||||||
|
"""
|
||||||
|
data = DglNodePropPredDataset('ogbn-mag', DATA_DIR)
|
||||||
|
g, labels = data[0]
|
||||||
|
if add_reverse_edge:
|
||||||
|
g = add_reverse_edges(g, reverse_self)
|
||||||
|
g = g.to(device)
|
||||||
|
features = g.nodes['paper'].data['feat']
|
||||||
|
labels = labels['paper'].squeeze(dim=1).to(device)
|
||||||
|
split_idx = data.get_idx_split()
|
||||||
|
train_idx = split_idx['train']['paper'].to(device)
|
||||||
|
val_idx = split_idx['valid']['paper'].to(device)
|
||||||
|
test_idx = split_idx['test']['paper'].to(device)
|
||||||
|
evaluator = Evaluator(data.name)
|
||||||
|
return data, g, features, labels, 'paper', train_idx, val_idx, test_idx, evaluator
|
||||||
|
|
||||||
|
|
||||||
|
def add_reverse_edges(g, reverse_self=True):
|
||||||
|
"""给异构图的每种边添加反向边,返回新的异构图
|
||||||
|
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param reverse_self: bool, optional 起点和终点类型相同时是否添加反向边,默认为True
|
||||||
|
:return: DGLGraph 添加反向边之后的异构图
|
||||||
|
"""
|
||||||
|
data = {}
|
||||||
|
for stype, etype, dtype in g.canonical_etypes:
|
||||||
|
u, v = g.edges(etype=(stype, etype, dtype))
|
||||||
|
data[(stype, etype, dtype)] = u, v
|
||||||
|
if stype != dtype or reverse_self:
|
||||||
|
data[(dtype, etype + '_rev', stype)] = v, u
|
||||||
|
new_g = dgl.heterograph(data, {ntype: g.num_nodes(ntype) for ntype in g.ntypes})
|
||||||
|
for ntype in g.ntypes:
|
||||||
|
new_g.nodes[ntype].data.update(g.nodes[ntype].data)
|
||||||
|
for etype in g.canonical_etypes:
|
||||||
|
new_g.edges[etype].data.update(g.edges[etype].data)
|
||||||
|
return new_g
|
||||||
|
|
||||||
|
|
||||||
|
def one_hot_node_feat(g):
|
||||||
|
for ntype in g.ntypes:
|
||||||
|
if 'feat' not in g.nodes[ntype].data:
|
||||||
|
g.nodes[ntype].data['feat'] = torch.eye(g.num_nodes(ntype), device=g.device)
|
||||||
|
|
||||||
|
|
||||||
|
def average_node_feat(g):
|
||||||
|
"""ogbn-mag数据集没有输入特征的顶点取邻居平均"""
|
||||||
|
message_func, reduce_func = fn.copy_u('feat', 'm'), fn.mean('m', 'feat')
|
||||||
|
g.multi_update_all({
|
||||||
|
'writes_rev': (message_func, reduce_func),
|
||||||
|
'has_topic': (message_func, reduce_func)
|
||||||
|
}, 'sum')
|
||||||
|
g.multi_update_all({'affiliated_with': (message_func, reduce_func)}, 'sum')
|
||||||
|
|
||||||
|
|
||||||
|
def load_pretrained_node_embed(g, node_embed_path, concat=False):
|
||||||
|
"""为没有输入特征的顶点加载预训练的顶点特征
|
||||||
|
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param node_embed_path: str 预训练的word2vec模型路径
|
||||||
|
:param concat: bool, optional 如果为True则将预训练特征与原输入特征拼接
|
||||||
|
"""
|
||||||
|
model = Word2Vec.load(node_embed_path)
|
||||||
|
for ntype in g.ntypes:
|
||||||
|
embed = torch.from_numpy(model.wv[[f'{ntype}_{i}' for i in range(g.num_nodes(ntype))]]) \
|
||||||
|
.to(g.device)
|
||||||
|
if 'feat' in g.nodes[ntype].data:
|
||||||
|
if concat:
|
||||||
|
g.nodes[ntype].data['feat'] = torch.cat([g.nodes[ntype].data['feat'], embed], dim=1)
|
||||||
|
else:
|
||||||
|
g.nodes[ntype].data['feat'] = embed
|
||||||
|
|
||||||
|
|
||||||
|
def add_node_feat(g, method, node_embed_path=None, concat=False):
|
||||||
|
"""为没有输入特征的顶点添加输入特征
|
||||||
|
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param method: str one-hot, average(仅用于ogbn-mag数据集), pretrained
|
||||||
|
:param node_embed_path: str 预训练的word2vec模型路径
|
||||||
|
:param concat: bool, optional 如果为True则将预训练特征与原输入特征拼接
|
||||||
|
"""
|
||||||
|
if method == 'one-hot':
|
||||||
|
one_hot_node_feat(g)
|
||||||
|
elif method == 'average':
|
||||||
|
average_node_feat(g)
|
||||||
|
elif method == 'pretrained':
|
||||||
|
load_pretrained_node_embed(g, node_embed_path, concat)
|
||||||
|
else:
|
||||||
|
raise ValueError(f'add_node_feat: 未知方法{method}')
|
||||||
|
|
@ -0,0 +1,87 @@
|
||||||
|
import torch
|
||||||
|
from sklearn.metrics import f1_score
|
||||||
|
|
||||||
|
|
||||||
|
def accuracy(predict, labels, evaluator=None):
|
||||||
|
"""计算准确率
|
||||||
|
|
||||||
|
:param predict: tensor(N) 预测标签
|
||||||
|
:param labels: tensor(N) 正确标签
|
||||||
|
:param evaluator: ogb.nodeproppred.Evaluator
|
||||||
|
:return: float 准确率
|
||||||
|
"""
|
||||||
|
if evaluator is not None:
|
||||||
|
y_true, y_pred = labels.unsqueeze(dim=1), predict.unsqueeze(dim=1)
|
||||||
|
return evaluator.eval({'y_true': y_true, 'y_pred': y_pred})['acc']
|
||||||
|
else:
|
||||||
|
return torch.sum(predict == labels).item() / labels.shape[0]
|
||||||
|
|
||||||
|
|
||||||
|
def macro_f1_score(predict, labels):
|
||||||
|
"""计算Macro-F1得分
|
||||||
|
|
||||||
|
:param predict: tensor(N) 预测标签
|
||||||
|
:param labels: tensor(N) 正确标签
|
||||||
|
:return: float Macro-F1得分
|
||||||
|
"""
|
||||||
|
return f1_score(labels.numpy(), predict.long().numpy(), average='macro')
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def evaluate(
|
||||||
|
model, loader, g, labels, num_classes, predict_ntype,
|
||||||
|
train_idx, val_idx, test_idx, evaluator=None):
|
||||||
|
"""评估模型性能
|
||||||
|
|
||||||
|
:param model: nn.Module GNN模型
|
||||||
|
:param loader: NodeDataLoader 图数据加载器
|
||||||
|
:param g: DGLGraph 图
|
||||||
|
:param labels: tensor(N) 顶点标签
|
||||||
|
:param num_classes: int 类别数
|
||||||
|
:param predict_ntype: str 目标顶点类型
|
||||||
|
:param train_idx: tensor(N_train) 训练集顶点id
|
||||||
|
:param val_idx: tensor(N_val) 验证集顶点id
|
||||||
|
:param test_idx: tensor(N_test) 测试集顶点id
|
||||||
|
:param evaluator: ogb.nodeproppred.Evaluator
|
||||||
|
:return: train_acc, val_acc, test_acc, train_f1, val_f1, test_f1
|
||||||
|
"""
|
||||||
|
model.eval()
|
||||||
|
logits = torch.zeros(g.num_nodes(predict_ntype), num_classes, device=train_idx.device)
|
||||||
|
for input_nodes, output_nodes, blocks in loader:
|
||||||
|
logits[output_nodes[predict_ntype]] = model(blocks, blocks[0].srcdata['feat'])
|
||||||
|
return calc_metrics(logits, labels, train_idx, val_idx, test_idx, evaluator)
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def evaluate_full(model, g, labels, train_idx, val_idx, test_idx):
|
||||||
|
"""评估模型性能(full-batch)
|
||||||
|
|
||||||
|
:param model: nn.Module GNN模型
|
||||||
|
:param g: DGLGraph 图
|
||||||
|
:param labels: tensor(N) 顶点标签
|
||||||
|
:param train_idx: tensor(N_train) 训练集顶点id
|
||||||
|
:param val_idx: tensor(N_val) 验证集顶点id
|
||||||
|
:param test_idx: tensor(N_test) 测试集顶点id
|
||||||
|
:return: train_acc, val_acc, test_acc, train_f1, val_f1, test_f1
|
||||||
|
"""
|
||||||
|
model.eval()
|
||||||
|
logits = model(g, g.ndata['feat'])
|
||||||
|
return calc_metrics(logits, labels, train_idx, val_idx, test_idx)
|
||||||
|
|
||||||
|
|
||||||
|
def calc_metrics(logits, labels, train_idx, val_idx, test_idx, evaluator=None):
|
||||||
|
predict = logits.detach().cpu().argmax(dim=1)
|
||||||
|
labels = labels.cpu()
|
||||||
|
train_acc = accuracy(predict[train_idx], labels[train_idx], evaluator)
|
||||||
|
val_acc = accuracy(predict[val_idx], labels[val_idx], evaluator)
|
||||||
|
test_acc = accuracy(predict[test_idx], labels[test_idx], evaluator)
|
||||||
|
train_f1 = macro_f1_score(predict[train_idx], labels[train_idx])
|
||||||
|
val_f1 = macro_f1_score(predict[val_idx], labels[val_idx])
|
||||||
|
test_f1 = macro_f1_score(predict[test_idx], labels[test_idx])
|
||||||
|
return train_acc, val_acc, test_acc, train_f1, val_f1, test_f1
|
||||||
|
|
||||||
|
|
||||||
|
METRICS_STR = ' | '.join(
|
||||||
|
f'{split} {metric} {{:.4f}}'
|
||||||
|
for metric in ('Acc', 'Macro-F1') for split in ('Train', 'Val', 'Test')
|
||||||
|
)
|
||||||
|
|
@ -0,0 +1,3 @@
|
||||||
|
from .oagcs import OAGCSDataset
|
||||||
|
from .contrast import OAGCSContrastDataset
|
||||||
|
from .venue import OAGVenueDataset
|
||||||
|
|
@ -0,0 +1,38 @@
|
||||||
|
CS = 'computer science'
|
||||||
|
|
||||||
|
CS_FIELD_L2 = [
|
||||||
|
'algorithm',
|
||||||
|
'artificial intelligence',
|
||||||
|
'computational science',
|
||||||
|
'computer architecture',
|
||||||
|
'computer engineering',
|
||||||
|
'computer graphics',
|
||||||
|
'computer hardware',
|
||||||
|
'computer network',
|
||||||
|
'computer security',
|
||||||
|
'computer vision',
|
||||||
|
'data mining',
|
||||||
|
'data science',
|
||||||
|
'database',
|
||||||
|
'distributed computing',
|
||||||
|
'embedded system',
|
||||||
|
'human computer interaction',
|
||||||
|
'information retrieval',
|
||||||
|
'internet privacy',
|
||||||
|
'knowledge management',
|
||||||
|
'library science',
|
||||||
|
'machine learning',
|
||||||
|
'multimedia',
|
||||||
|
'natural language processing',
|
||||||
|
'operating system',
|
||||||
|
'parallel computing',
|
||||||
|
'pattern recognition',
|
||||||
|
'programming language',
|
||||||
|
'real time computing',
|
||||||
|
'simulation',
|
||||||
|
'software engineering',
|
||||||
|
'speech recognition',
|
||||||
|
'telecommunications',
|
||||||
|
'theoretical computer science',
|
||||||
|
'world wide web',
|
||||||
|
]
|
||||||
|
|
@ -0,0 +1,30 @@
|
||||||
|
from torch.utils.data import Dataset
|
||||||
|
|
||||||
|
from gnnrec.kgrec.utils import iter_json
|
||||||
|
|
||||||
|
|
||||||
|
class OAGCSContrastDataset(Dataset):
|
||||||
|
SPLIT_YEAR = 2016
|
||||||
|
|
||||||
|
def __init__(self, raw_file, split='train'):
|
||||||
|
"""oag-cs论文标题-关键词对比学习数据集
|
||||||
|
|
||||||
|
由于原始数据不包含关键词,因此使用研究领域(fos字段)作为关键词
|
||||||
|
|
||||||
|
:param raw_file: str 原始论文数据文件
|
||||||
|
:param split: str "train", "valid", "all"
|
||||||
|
"""
|
||||||
|
self.titles = []
|
||||||
|
self.keywords = []
|
||||||
|
for p in iter_json(raw_file):
|
||||||
|
if split == 'train' and p['year'] <= self.SPLIT_YEAR \
|
||||||
|
or split == 'valid' and p['year'] > self.SPLIT_YEAR \
|
||||||
|
or split == 'all':
|
||||||
|
self.titles.append(p['title'])
|
||||||
|
self.keywords.append('; '.join(p['fos']))
|
||||||
|
|
||||||
|
def __getitem__(self, item):
|
||||||
|
return self.titles[item], self.keywords[item]
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return len(self.titles)
|
||||||
|
|
@ -0,0 +1,153 @@
|
||||||
|
import os
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import pandas as pd
|
||||||
|
import torch
|
||||||
|
from dgl.data import DGLDataset, extract_archive
|
||||||
|
from dgl.data.utils import save_graphs, load_graphs
|
||||||
|
|
||||||
|
from gnnrec.kgrec.utils import iter_json
|
||||||
|
|
||||||
|
|
||||||
|
class OAGCSDataset(DGLDataset):
|
||||||
|
"""OAG MAG数据集(https://www.aminer.cn/oag-2-1)计算机领域的子集,只有一个异构图
|
||||||
|
|
||||||
|
统计数据
|
||||||
|
-----
|
||||||
|
顶点
|
||||||
|
|
||||||
|
* 2248205 author
|
||||||
|
* 1852225 paper
|
||||||
|
* 11177 venue
|
||||||
|
* 13747 institution
|
||||||
|
* 120992 field
|
||||||
|
|
||||||
|
边
|
||||||
|
|
||||||
|
* 6349317 author-writes->paper
|
||||||
|
* 1852225 paper-published_at->venue
|
||||||
|
* 17250107 paper-has_field->field
|
||||||
|
* 9194781 paper-cites->paper
|
||||||
|
* 1726212 author-affiliated_with->institution
|
||||||
|
|
||||||
|
paper顶点属性
|
||||||
|
-----
|
||||||
|
* feat: tensor(N_paper, 128) 预训练的标题和摘要词向量
|
||||||
|
* year: tensor(N_paper) 发表年份(2010~2021)
|
||||||
|
* citation: tensor(N_paper) 引用数
|
||||||
|
* 不包含标签
|
||||||
|
|
||||||
|
field顶点属性
|
||||||
|
-----
|
||||||
|
* feat: tensor(N_field, 128) 预训练的领域向量
|
||||||
|
|
||||||
|
writes边属性
|
||||||
|
-----
|
||||||
|
* order: tensor(N_writes) 作者顺序(从1开始)
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, **kwargs):
|
||||||
|
super().__init__('oag-cs', 'https://pan.baidu.com/s/1ayH3tQxsiDDnqPoXhR0Ekg', **kwargs)
|
||||||
|
|
||||||
|
def download(self):
|
||||||
|
zip_file_path = os.path.join(self.raw_dir, 'oag-cs.zip')
|
||||||
|
if not os.path.exists(zip_file_path):
|
||||||
|
raise FileNotFoundError('请手动下载文件 {} 提取码:2ylp 并保存为 {}'.format(
|
||||||
|
self.url, zip_file_path
|
||||||
|
))
|
||||||
|
extract_archive(zip_file_path, self.raw_path)
|
||||||
|
|
||||||
|
def save(self):
|
||||||
|
save_graphs(os.path.join(self.save_path, self.name + '_dgl_graph.bin'), [self.g])
|
||||||
|
|
||||||
|
def load(self):
|
||||||
|
self.g = load_graphs(os.path.join(self.save_path, self.name + '_dgl_graph.bin'))[0][0]
|
||||||
|
|
||||||
|
def process(self):
|
||||||
|
self._vid_map = self._read_venues() # {原始id: 顶点id}
|
||||||
|
self._oid_map = self._read_institutions() # {原始id: 顶点id}
|
||||||
|
self._fid_map = self._read_fields() # {领域名称: 顶点id}
|
||||||
|
self._aid_map, author_inst = self._read_authors() # {原始id: 顶点id}, R(aid, oid)
|
||||||
|
# PA(pid, aid), PV(pid, vid), PF(pid, fid), PP(pid, rid), [年份], [引用数]
|
||||||
|
paper_author, paper_venue, paper_field, paper_ref, paper_year, paper_citation = self._read_papers()
|
||||||
|
self.g = self._build_graph(paper_author, paper_venue, paper_field, paper_ref, author_inst, paper_year, paper_citation)
|
||||||
|
|
||||||
|
def _iter_json(self, filename):
|
||||||
|
yield from iter_json(os.path.join(self.raw_path, filename))
|
||||||
|
|
||||||
|
def _read_venues(self):
|
||||||
|
print('正在读取期刊数据...')
|
||||||
|
# 行号=索引=顶点id
|
||||||
|
return {v['id']: i for i, v in enumerate(self._iter_json('mag_venues.txt'))}
|
||||||
|
|
||||||
|
def _read_institutions(self):
|
||||||
|
print('正在读取机构数据...')
|
||||||
|
return {o['id']: i for i, o in enumerate(self._iter_json('mag_institutions.txt'))}
|
||||||
|
|
||||||
|
def _read_fields(self):
|
||||||
|
print('正在读取领域数据...')
|
||||||
|
return {f['name']: f['id'] for f in self._iter_json('mag_fields.txt')}
|
||||||
|
|
||||||
|
def _read_authors(self):
|
||||||
|
print('正在读取学者数据...')
|
||||||
|
author_id_map, author_inst = {}, []
|
||||||
|
for i, a in enumerate(self._iter_json('mag_authors.txt')):
|
||||||
|
author_id_map[a['id']] = i
|
||||||
|
if a['org'] is not None:
|
||||||
|
author_inst.append([i, self._oid_map[a['org']]])
|
||||||
|
return author_id_map, pd.DataFrame(author_inst, columns=['aid', 'oid'])
|
||||||
|
|
||||||
|
def _read_papers(self):
|
||||||
|
print('正在读取论文数据...')
|
||||||
|
paper_id_map, paper_author, paper_venue, paper_field = {}, [], [], []
|
||||||
|
paper_year, paper_citation = [], []
|
||||||
|
for i, p in enumerate(self._iter_json('mag_papers.txt')):
|
||||||
|
paper_id_map[p['id']] = i
|
||||||
|
paper_author.extend([i, self._aid_map[a], r + 1] for r, a in enumerate(p['authors']))
|
||||||
|
paper_venue.append([i, self._vid_map[p['venue']]])
|
||||||
|
paper_field.extend([i, self._fid_map[f]] for f in p['fos'] if f in self._fid_map)
|
||||||
|
paper_year.append(p['year'])
|
||||||
|
paper_citation.append(p['n_citation'])
|
||||||
|
|
||||||
|
paper_ref = []
|
||||||
|
for i, p in enumerate(self._iter_json('mag_papers.txt')):
|
||||||
|
paper_ref.extend([i, paper_id_map[r]] for r in p['references'] if r in paper_id_map)
|
||||||
|
return (
|
||||||
|
pd.DataFrame(paper_author, columns=['pid', 'aid', 'order']).drop_duplicates(subset=['pid', 'aid']),
|
||||||
|
pd.DataFrame(paper_venue, columns=['pid', 'vid']),
|
||||||
|
pd.DataFrame(paper_field, columns=['pid', 'fid']),
|
||||||
|
pd.DataFrame(paper_ref, columns=['pid', 'rid']),
|
||||||
|
paper_year, paper_citation
|
||||||
|
)
|
||||||
|
|
||||||
|
def _build_graph(self, paper_author, paper_venue, paper_field, paper_ref, author_inst, paper_year, paper_citation):
|
||||||
|
print('正在构造异构图...')
|
||||||
|
pa_p, pa_a = paper_author['pid'].to_list(), paper_author['aid'].to_list()
|
||||||
|
pv_p, pv_v = paper_venue['pid'].to_list(), paper_venue['vid'].to_list()
|
||||||
|
pf_p, pf_f = paper_field['pid'].to_list(), paper_field['fid'].to_list()
|
||||||
|
pp_p, pp_r = paper_ref['pid'].to_list(), paper_ref['rid'].to_list()
|
||||||
|
ai_a, ai_i = author_inst['aid'].to_list(), author_inst['oid'].to_list()
|
||||||
|
g = dgl.heterograph({
|
||||||
|
('author', 'writes', 'paper'): (pa_a, pa_p),
|
||||||
|
('paper', 'published_at', 'venue'): (pv_p, pv_v),
|
||||||
|
('paper', 'has_field', 'field'): (pf_p, pf_f),
|
||||||
|
('paper', 'cites', 'paper'): (pp_p, pp_r),
|
||||||
|
('author', 'affiliated_with', 'institution'): (ai_a, ai_i)
|
||||||
|
})
|
||||||
|
g.nodes['paper'].data['feat'] = torch.load(os.path.join(self.raw_path, 'paper_feat.pkl'))
|
||||||
|
g.nodes['paper'].data['year'] = torch.tensor(paper_year)
|
||||||
|
g.nodes['paper'].data['citation'] = torch.tensor(paper_citation)
|
||||||
|
g.nodes['field'].data['feat'] = torch.load(os.path.join(self.raw_path, 'field_feat.pkl'))
|
||||||
|
g.edges['writes'].data['order'] = torch.tensor(paper_author['order'].to_list())
|
||||||
|
return g
|
||||||
|
|
||||||
|
def has_cache(self):
|
||||||
|
return os.path.exists(os.path.join(self.save_path, self.name + '_dgl_graph.bin'))
|
||||||
|
|
||||||
|
def __getitem__(self, idx):
|
||||||
|
if idx != 0:
|
||||||
|
raise IndexError('This dataset has only one graph')
|
||||||
|
return self.g
|
||||||
|
|
||||||
|
def __len__(self):
|
||||||
|
return 1
|
||||||
|
|
@ -0,0 +1,72 @@
|
||||||
|
import json
|
||||||
|
import os
|
||||||
|
from collections import defaultdict
|
||||||
|
|
||||||
|
import scrapy
|
||||||
|
from itemadapter import ItemAdapter
|
||||||
|
|
||||||
|
|
||||||
|
class ScholarItem(scrapy.Item):
|
||||||
|
name = scrapy.Field()
|
||||||
|
org = scrapy.Field()
|
||||||
|
field = scrapy.Field()
|
||||||
|
rank = scrapy.Field()
|
||||||
|
|
||||||
|
|
||||||
|
class AI2000Spider(scrapy.Spider):
|
||||||
|
name = 'ai2000'
|
||||||
|
allowed_domains = ['aminer.cn']
|
||||||
|
custom_settings = {
|
||||||
|
'DEFAULT_REQUEST_HEADERS': {
|
||||||
|
'Content-Type': 'application/json',
|
||||||
|
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
|
||||||
|
},
|
||||||
|
'DOWNLOAD_DELAY': 20,
|
||||||
|
'ITEM_PIPELINES': {'ai2000_crawler.JsonWriterPipeline': 0}
|
||||||
|
}
|
||||||
|
|
||||||
|
def __init__(self, save_path, *args, **kwargs):
|
||||||
|
super().__init__(*args, **kwargs)
|
||||||
|
self.save_path = save_path
|
||||||
|
|
||||||
|
def start_requests(self):
|
||||||
|
return [scrapy.Request(
|
||||||
|
'https://apiv2.aminer.cn/magic?a=__mostinfluentialscholars.GetDomainList___',
|
||||||
|
callback=self.parse_domain_list, method='POST',
|
||||||
|
body='[{"action":"mostinfluentialscholars.GetDomainList","parameters":{"year":2019}}]'
|
||||||
|
)]
|
||||||
|
|
||||||
|
def parse_domain_list(self, response):
|
||||||
|
domains = json.loads(response.body)['data'][0]['item']
|
||||||
|
body_fmt = '[{"action":"ai2000v2.GetDomainTopScholars","parameters":{"year_filter":2020,"domain":"%s","top_n":100,"type":"AI 2000"}}]'
|
||||||
|
for domain in domains:
|
||||||
|
yield scrapy.Request(
|
||||||
|
'https://apiv2.aminer.cn/magic?a=__ai2000v2.GetDomainTopScholars___',
|
||||||
|
method='POST', body=body_fmt % domain['id'],
|
||||||
|
cb_kwargs={'domain_name': domain['name']}
|
||||||
|
)
|
||||||
|
|
||||||
|
def parse(self, response, **kwargs):
|
||||||
|
domain_name = kwargs['domain_name']
|
||||||
|
scholars = json.loads(response.body)['data'][0]['data']
|
||||||
|
for i, scholar in enumerate(scholars[:100]):
|
||||||
|
yield ScholarItem(
|
||||||
|
name=scholar['person']['name'], org=scholar['org_en'],
|
||||||
|
field=domain_name, rank=i
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
class JsonWriterPipeline:
|
||||||
|
|
||||||
|
def open_spider(self, spider):
|
||||||
|
self.scholar_rank = defaultdict(lambda: [None] * 100)
|
||||||
|
self.save_path = spider.save_path
|
||||||
|
|
||||||
|
def process_item(self, item, spider):
|
||||||
|
scholar = ItemAdapter(item).asdict()
|
||||||
|
self.scholar_rank[scholar.pop('field')][scholar.pop('rank')] = scholar
|
||||||
|
return item
|
||||||
|
|
||||||
|
def close_spider(self, spider):
|
||||||
|
with open(os.path.join(self.save_path), 'w', encoding='utf8') as f:
|
||||||
|
json.dump(self.scholar_rank, f, ensure_ascii=False)
|
||||||
|
|
@ -0,0 +1,41 @@
|
||||||
|
import argparse
|
||||||
|
from collections import Counter
|
||||||
|
|
||||||
|
from gnnrec.kgrec.data.preprocess.utils import iter_lines
|
||||||
|
|
||||||
|
|
||||||
|
def analyze(args):
|
||||||
|
total = 0
|
||||||
|
max_fields = set()
|
||||||
|
min_fields = None
|
||||||
|
field_count = Counter()
|
||||||
|
sample = None
|
||||||
|
for d in iter_lines(args.raw_path, args.type):
|
||||||
|
total += 1
|
||||||
|
keys = [k for k in d if d[k]]
|
||||||
|
max_fields.update(keys)
|
||||||
|
if min_fields is None:
|
||||||
|
min_fields = set(keys)
|
||||||
|
else:
|
||||||
|
min_fields.intersection_update(keys)
|
||||||
|
field_count.update(keys)
|
||||||
|
if len(keys) == len(max_fields):
|
||||||
|
sample = d
|
||||||
|
print('数据类型:', args.type)
|
||||||
|
print('总量:', total)
|
||||||
|
print('最大字段集合:', max_fields)
|
||||||
|
print('最小字段集合:', min_fields)
|
||||||
|
print('字段出现比例:', {k: v / total for k, v in field_count.items()})
|
||||||
|
print('示例:', sample)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='分析OAG MAG数据集的字段')
|
||||||
|
parser.add_argument('type', choices=['author', 'paper', 'venue', 'affiliation'], help='数据类型')
|
||||||
|
parser.add_argument('raw_path', help='原始zip文件所在目录')
|
||||||
|
args = parser.parse_args()
|
||||||
|
analyze(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,202 @@
|
||||||
|
import argparse
|
||||||
|
import json
|
||||||
|
import math
|
||||||
|
import random
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import dgl.function as fn
|
||||||
|
import django
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
from dgl.ops import edge_softmax
|
||||||
|
from sklearn.metrics import ndcg_score
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR
|
||||||
|
from gnnrec.hge.utils import set_random_seed, add_reverse_edges
|
||||||
|
from gnnrec.kgrec.data import OAGCSDataset
|
||||||
|
from gnnrec.kgrec.utils import iter_json, precision_at_k, recall_at_k
|
||||||
|
|
||||||
|
|
||||||
|
def build_ground_truth_valid(args):
|
||||||
|
"""从AI 2000抓取的学者排名数据匹配学者id,作为学者排名ground truth验证集。"""
|
||||||
|
field_map = {
|
||||||
|
'AAAI/IJCAI': 'artificial intelligence',
|
||||||
|
'Machine Learning': 'machine learning',
|
||||||
|
'Computer Vision': 'computer vision',
|
||||||
|
'Natural Language Processing': 'natural language processing',
|
||||||
|
'Robotics': 'robotics',
|
||||||
|
'Knowledge Engineering': 'knowledge engineering',
|
||||||
|
'Speech Recognition': 'speech recognition',
|
||||||
|
'Data Mining': 'data mining',
|
||||||
|
'Information Retrieval and Recommendation': 'information retrieval',
|
||||||
|
'Database': 'database',
|
||||||
|
'Human-Computer Interaction': 'human computer interaction',
|
||||||
|
'Computer Graphics': 'computer graphics',
|
||||||
|
'Multimedia': 'multimedia',
|
||||||
|
'Visualization': 'visualization',
|
||||||
|
'Security and Privacy': 'security privacy',
|
||||||
|
'Computer Networking': 'computer network',
|
||||||
|
'Computer Systems': 'operating system',
|
||||||
|
'Theory': 'theory',
|
||||||
|
'Chip Technology': 'chip',
|
||||||
|
'Internet of Things': 'internet of things',
|
||||||
|
}
|
||||||
|
with open(DATA_DIR / 'rank/ai2000.json', encoding='utf8') as f:
|
||||||
|
ai2000_author_rank = json.load(f)
|
||||||
|
|
||||||
|
django.setup()
|
||||||
|
from rank.models import Author
|
||||||
|
|
||||||
|
author_rank = {}
|
||||||
|
for field, scholars in ai2000_author_rank.items():
|
||||||
|
aid = []
|
||||||
|
for s in scholars:
|
||||||
|
qs = Author.objects.filter(name=s['name'], institution__name=s['org']).order_by('-n_citation')
|
||||||
|
if qs.exists():
|
||||||
|
aid.append(qs[0].id)
|
||||||
|
else:
|
||||||
|
qs = Author.objects.filter(name=s['name']).order_by('-n_citation')
|
||||||
|
aid.append(qs[0].id if qs.exists() else -1)
|
||||||
|
author_rank[field_map[field]] = aid
|
||||||
|
if not args.use_field_name:
|
||||||
|
field2id = {f['name']: i for i, f in enumerate(iter_json(DATA_DIR / 'oag/cs/mag_fields.txt'))}
|
||||||
|
author_rank = {field2id[f]: aid for f, aid in author_rank.items()}
|
||||||
|
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_val.json', 'w') as f:
|
||||||
|
json.dump(author_rank, f)
|
||||||
|
print('结果已保存到', f.name)
|
||||||
|
|
||||||
|
|
||||||
|
def build_ground_truth_train(args):
|
||||||
|
"""根据某个领域的论文引用数加权求和构造学者排名,作为ground truth训练集。"""
|
||||||
|
data = OAGCSDataset()
|
||||||
|
g = data[0]
|
||||||
|
g.nodes['paper'].data['citation'] = g.nodes['paper'].data['citation'].float().log1p()
|
||||||
|
g.edges['writes'].data['order'] = g.edges['writes'].data['order'].float()
|
||||||
|
apg = g['author', 'writes', 'paper']
|
||||||
|
|
||||||
|
# 1.筛选论文数>=num_papers的领域
|
||||||
|
field_in_degree, fid = g.in_degrees(g.nodes('field'), etype='has_field').sort(descending=True)
|
||||||
|
fid = fid[field_in_degree >= args.num_papers].tolist()
|
||||||
|
|
||||||
|
# 2.对每个领域召回论文,构造学者-论文子图,通过论文引用数之和对学者排名
|
||||||
|
author_rank = {}
|
||||||
|
for i in tqdm(fid):
|
||||||
|
pid, _ = g.in_edges(i, etype='has_field')
|
||||||
|
sg = add_reverse_edges(dgl.in_subgraph(apg, {'paper': pid}, relabel_nodes=True))
|
||||||
|
|
||||||
|
# 第k作者的权重为1/k,最后一个视为通讯作者,权重为1/2
|
||||||
|
sg.edges['writes'].data['w'] = 1.0 / sg.edges['writes'].data['order']
|
||||||
|
sg.update_all(fn.copy_e('w', 'w'), fn.min('w', 'mw'), etype='writes')
|
||||||
|
sg.apply_edges(fn.copy_u('mw', 'mw'), etype='writes_rev')
|
||||||
|
w, mw = sg.edges['writes'].data.pop('w'), sg.edges['writes_rev'].data.pop('mw')
|
||||||
|
w[w == mw] = 0.5
|
||||||
|
|
||||||
|
# 每篇论文所有作者的权重归一化,每个学者所有论文的引用数加权求和
|
||||||
|
p = edge_softmax(sg['author', 'writes', 'paper'], torch.log(w).unsqueeze(dim=1))
|
||||||
|
sg.edges['writes_rev'].data['p'] = p.squeeze(dim=1)
|
||||||
|
sg.update_all(fn.u_mul_e('citation', 'p', 'c'), fn.sum('c', 'c'), etype='writes_rev')
|
||||||
|
author_citation = sg.nodes['author'].data['c']
|
||||||
|
|
||||||
|
_, aid = author_citation.topk(args.num_authors)
|
||||||
|
aid = sg.nodes['author'].data[dgl.NID][aid]
|
||||||
|
author_rank[i] = aid.tolist()
|
||||||
|
if args.use_field_name:
|
||||||
|
fields = [f['name'] for f in iter_json(DATA_DIR / 'oag/cs/mag_fields.txt')]
|
||||||
|
author_rank = {fields[i]: aid for i, aid in author_rank.items()}
|
||||||
|
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_train.json', 'w') as f:
|
||||||
|
json.dump(author_rank, f)
|
||||||
|
print('结果已保存到', f.name)
|
||||||
|
|
||||||
|
|
||||||
|
def evaluate_ground_truth(args):
|
||||||
|
"""评估ground truth训练集的质量。"""
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_val.json') as f:
|
||||||
|
author_rank_val = json.load(f)
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_train.json') as f:
|
||||||
|
author_rank_train = json.load(f)
|
||||||
|
fields = list(set(author_rank_val) & set(author_rank_train))
|
||||||
|
author_rank_val = {k: v for k, v in author_rank_val.items() if k in fields}
|
||||||
|
author_rank_train = {k: v for k, v in author_rank_train.items() if k in fields}
|
||||||
|
|
||||||
|
num_authors = OAGCSDataset()[0].num_nodes('author')
|
||||||
|
true_relevance = np.zeros((len(fields), num_authors), dtype=np.int32)
|
||||||
|
scores = np.zeros_like(true_relevance)
|
||||||
|
for i, f in enumerate(fields):
|
||||||
|
for r, a in enumerate(author_rank_val[f]):
|
||||||
|
if a != -1:
|
||||||
|
true_relevance[i, a] = math.ceil((100 - r) / 10)
|
||||||
|
for r, a in enumerate(author_rank_train[f]):
|
||||||
|
scores[i, a] = len(author_rank_train[f]) - r
|
||||||
|
|
||||||
|
for k in (100, 50, 20, 10, 5):
|
||||||
|
print('nDGC@{0}={1:.4f}\tPrecision@{0}={2:.4f}\tRecall@{0}={3:.4f}'.format(
|
||||||
|
k, ndcg_score(true_relevance, scores, k=k, ignore_ties=True),
|
||||||
|
sum(precision_at_k(author_rank_val[f], author_rank_train[f], k) for f in fields) / len(fields),
|
||||||
|
sum(recall_at_k(author_rank_val[f], author_rank_train[f], k) for f in fields) / len(fields)
|
||||||
|
))
|
||||||
|
|
||||||
|
|
||||||
|
def sample_triplets(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_train.json') as f:
|
||||||
|
author_rank = json.load(f)
|
||||||
|
|
||||||
|
# 三元组:(t, ap, an),表示对于领域t,学者ap的排名在an之前
|
||||||
|
triplets = []
|
||||||
|
for fid, aid in author_rank.items():
|
||||||
|
fid = int(fid)
|
||||||
|
n = len(aid)
|
||||||
|
easy_margin, hard_margin = int(n * args.easy_margin), int(n * args.hard_margin)
|
||||||
|
num_triplets = min(args.max_num, 2 * n - easy_margin - hard_margin)
|
||||||
|
num_hard = int(num_triplets * args.hard_ratio)
|
||||||
|
num_easy = num_triplets - num_hard
|
||||||
|
triplets.extend(
|
||||||
|
(fid, aid[i], aid[i + easy_margin])
|
||||||
|
for i in random.sample(range(n - easy_margin), num_easy)
|
||||||
|
)
|
||||||
|
triplets.extend(
|
||||||
|
(fid, aid[i], aid[i + hard_margin])
|
||||||
|
for i in random.sample(range(n - hard_margin), num_hard)
|
||||||
|
)
|
||||||
|
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_triplets.txt', 'w') as f:
|
||||||
|
for t, ap, an in triplets:
|
||||||
|
f.write(f'{t} {ap} {an}\n')
|
||||||
|
print('结果已保存到', f.name)
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='基于oag-cs数据集构造学者排名数据集')
|
||||||
|
subparsers = parser.add_subparsers()
|
||||||
|
|
||||||
|
build_val_parser = subparsers.add_parser('build-val', help='构造学者排名验证集')
|
||||||
|
build_val_parser.add_argument('--use-field-name', action='store_true', help='使用领域名称(用于调试)')
|
||||||
|
build_val_parser.set_defaults(func=build_ground_truth_valid)
|
||||||
|
|
||||||
|
build_train_parser = subparsers.add_parser('build-train', help='构造学者排名训练集')
|
||||||
|
build_train_parser.add_argument('--num-papers', type=int, default=5000, help='筛选领域的论文数阈值')
|
||||||
|
build_train_parser.add_argument('--num-authors', type=int, default=100, help='每个领域取top k的学者数量')
|
||||||
|
build_train_parser.add_argument('--use-field-name', action='store_true', help='使用领域名称(用于调试)')
|
||||||
|
build_train_parser.set_defaults(func=build_ground_truth_train)
|
||||||
|
|
||||||
|
evaluate_parser = subparsers.add_parser('eval', help='评估ground truth训练集的质量')
|
||||||
|
evaluate_parser.set_defaults(func=evaluate_ground_truth)
|
||||||
|
|
||||||
|
sample_parser = subparsers.add_parser('sample', help='采样三元组')
|
||||||
|
sample_parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
sample_parser.add_argument('--max-num', type=int, default=100, help='每个领域采样三元组最大数量')
|
||||||
|
sample_parser.add_argument('--easy-margin', type=float, default=0.2, help='简单样本间隔(百分比)')
|
||||||
|
sample_parser.add_argument('--hard-margin', type=float, default=0.05, help='困难样本间隔(百分比)')
|
||||||
|
sample_parser.add_argument('--hard-ratio', type=float, default=0.5, help='困难样本比例')
|
||||||
|
sample_parser.set_defaults(func=sample_triplets)
|
||||||
|
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
args.func(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,129 @@
|
||||||
|
import argparse
|
||||||
|
import json
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR
|
||||||
|
from gnnrec.kgrec.data.config import CS, CS_FIELD_L2
|
||||||
|
from gnnrec.kgrec.data.preprocess.utils import iter_lines
|
||||||
|
|
||||||
|
|
||||||
|
def extract_papers(raw_path):
|
||||||
|
valid_keys = ['title', 'authors', 'venue', 'year', 'indexed_abstract', 'fos', 'references']
|
||||||
|
cs_fields = set(CS_FIELD_L2)
|
||||||
|
for p in iter_lines(raw_path, 'paper'):
|
||||||
|
if not all(p.get(k) for k in valid_keys):
|
||||||
|
continue
|
||||||
|
fos = {f['name'] for f in p['fos']}
|
||||||
|
abstract = parse_abstract(p['indexed_abstract'])
|
||||||
|
if CS in fos and not fos.isdisjoint(cs_fields) \
|
||||||
|
and 2010 <= p['year'] <= 2021 \
|
||||||
|
and len(p['title']) <= 200 and len(abstract) <= 4000 \
|
||||||
|
and 1 <= len(p['authors']) <= 20 and 1 <= len(p['references']) <= 100:
|
||||||
|
try:
|
||||||
|
yield {
|
||||||
|
'id': p['id'],
|
||||||
|
'title': p['title'],
|
||||||
|
'authors': [a['id'] for a in p['authors']],
|
||||||
|
'venue': p['venue']['id'],
|
||||||
|
'year': p['year'],
|
||||||
|
'abstract': abstract,
|
||||||
|
'fos': list(fos),
|
||||||
|
'references': p['references'],
|
||||||
|
'n_citation': p.get('n_citation', 0),
|
||||||
|
}
|
||||||
|
except KeyError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
def parse_abstract(indexed_abstract):
|
||||||
|
try:
|
||||||
|
abstract = json.loads(indexed_abstract)
|
||||||
|
words = [''] * abstract['IndexLength']
|
||||||
|
for w, idx in abstract['InvertedIndex'].items():
|
||||||
|
for i in idx:
|
||||||
|
words[i] = w
|
||||||
|
return ' '.join(words)
|
||||||
|
except json.JSONDecodeError:
|
||||||
|
return ''
|
||||||
|
|
||||||
|
|
||||||
|
def extract_authors(raw_path, author_ids):
|
||||||
|
for a in iter_lines(raw_path, 'author'):
|
||||||
|
if a['id'] in author_ids:
|
||||||
|
yield {
|
||||||
|
'id': a['id'],
|
||||||
|
'name': a['name'],
|
||||||
|
'org': int(a['last_known_aff_id']) if 'last_known_aff_id' in a else None
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
def extract_venues(raw_path, venue_ids):
|
||||||
|
for v in iter_lines(raw_path, 'venue'):
|
||||||
|
if v['id'] in venue_ids:
|
||||||
|
yield {'id': v['id'], 'name': v['DisplayName']}
|
||||||
|
|
||||||
|
|
||||||
|
def extract_institutions(raw_path, institution_ids):
|
||||||
|
for i in iter_lines(raw_path, 'affiliation'):
|
||||||
|
if i['id'] in institution_ids:
|
||||||
|
yield {'id': i['id'], 'name': i['DisplayName']}
|
||||||
|
|
||||||
|
|
||||||
|
def extract(args):
|
||||||
|
print('正在抽取计算机领域的论文...')
|
||||||
|
paper_ids, author_ids, venue_ids, fields = set(), set(), set(), set()
|
||||||
|
output_path = DATA_DIR / 'oag/cs'
|
||||||
|
with open(output_path / 'mag_papers.txt', 'w', encoding='utf8') as f:
|
||||||
|
for p in extract_papers(args.raw_path):
|
||||||
|
paper_ids.add(p['id'])
|
||||||
|
author_ids.update(p['authors'])
|
||||||
|
venue_ids.add(p['venue'])
|
||||||
|
fields.update(p['fos'])
|
||||||
|
json.dump(p, f, ensure_ascii=False)
|
||||||
|
f.write('\n')
|
||||||
|
print(f'论文抽取完成,已保存到{f.name}')
|
||||||
|
print(f'论文数{len(paper_ids)},学者数{len(author_ids)},期刊数{len(venue_ids)},领域数{len(fields)}')
|
||||||
|
|
||||||
|
print('正在抽取学者...')
|
||||||
|
institution_ids = set()
|
||||||
|
with open(output_path / 'mag_authors.txt', 'w', encoding='utf8') as f:
|
||||||
|
for a in extract_authors(args.raw_path, author_ids):
|
||||||
|
if a['org']:
|
||||||
|
institution_ids.add(a['org'])
|
||||||
|
json.dump(a, f, ensure_ascii=False)
|
||||||
|
f.write('\n')
|
||||||
|
print(f'学者抽取完成,已保存到{f.name}')
|
||||||
|
print(f'机构数{len(institution_ids)}')
|
||||||
|
|
||||||
|
print('正在抽取期刊...')
|
||||||
|
with open(output_path / 'mag_venues.txt', 'w', encoding='utf8') as f:
|
||||||
|
for v in extract_venues(args.raw_path, venue_ids):
|
||||||
|
json.dump(v, f, ensure_ascii=False)
|
||||||
|
f.write('\n')
|
||||||
|
print(f'期刊抽取完成,已保存到{f.name}')
|
||||||
|
|
||||||
|
print('正在抽取机构...')
|
||||||
|
with open(output_path / 'mag_institutions.txt', 'w', encoding='utf8') as f:
|
||||||
|
for i in extract_institutions(args.raw_path, institution_ids):
|
||||||
|
json.dump(i, f, ensure_ascii=False)
|
||||||
|
f.write('\n')
|
||||||
|
print(f'机构抽取完成,已保存到{f.name}')
|
||||||
|
|
||||||
|
print('正在抽取领域...')
|
||||||
|
fields.remove(CS)
|
||||||
|
fields = sorted(fields)
|
||||||
|
with open(output_path / 'mag_fields.txt', 'w', encoding='utf8') as f:
|
||||||
|
for i, field in enumerate(fields):
|
||||||
|
json.dump({'id': i, 'name': field}, f, ensure_ascii=False)
|
||||||
|
f.write('\n')
|
||||||
|
print(f'领域抽取完成,已保存到{f.name}')
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='抽取OAG数据集计算机领域的子集')
|
||||||
|
parser.add_argument('raw_path', help='原始zip文件所在目录')
|
||||||
|
args = parser.parse_args()
|
||||||
|
extract(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,131 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.optim as optim
|
||||||
|
from torch.utils.data import DataLoader
|
||||||
|
from tqdm import tqdm
|
||||||
|
from transformers import get_linear_schedule_with_warmup
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR, MODEL_DIR
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, accuracy
|
||||||
|
from gnnrec.kgrec.data import OAGCSContrastDataset
|
||||||
|
from gnnrec.kgrec.scibert import ContrastiveSciBERT
|
||||||
|
from gnnrec.kgrec.utils import iter_json
|
||||||
|
|
||||||
|
|
||||||
|
def collate(samples):
|
||||||
|
return map(list, zip(*samples))
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
|
||||||
|
raw_file = DATA_DIR / 'oag/cs/mag_papers.txt'
|
||||||
|
train_dataset = OAGCSContrastDataset(raw_file, split='train')
|
||||||
|
train_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, collate_fn=collate)
|
||||||
|
valid_dataset = OAGCSContrastDataset(raw_file, split='valid')
|
||||||
|
valid_loader = DataLoader(valid_dataset, batch_size=args.batch_size, shuffle=True, collate_fn=collate)
|
||||||
|
|
||||||
|
model = ContrastiveSciBERT(args.num_hidden, args.tau, device).to(device)
|
||||||
|
optimizer = optim.AdamW(model.parameters(), lr=args.lr)
|
||||||
|
total_steps = len(train_loader) * args.epochs
|
||||||
|
scheduler = get_linear_schedule_with_warmup(
|
||||||
|
optimizer, num_warmup_steps=total_steps * 0.1, num_training_steps=total_steps
|
||||||
|
)
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
losses, scores = [], []
|
||||||
|
for titles, keywords in tqdm(train_loader):
|
||||||
|
logits, loss = model(titles, keywords)
|
||||||
|
labels = torch.arange(len(titles), device=device)
|
||||||
|
losses.append(loss.item())
|
||||||
|
scores.append(score(logits, labels))
|
||||||
|
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
val_score = evaluate(valid_loader, model, device)
|
||||||
|
print('Epoch {:d} | Loss {:.4f} | Train Acc {:.4f} | Val Acc {:.4f}'.format(
|
||||||
|
epoch, sum(losses) / len(losses), sum(scores) / len(scores), val_score
|
||||||
|
))
|
||||||
|
model_save_path = MODEL_DIR / 'scibert.pt'
|
||||||
|
torch.save(model.state_dict(), model_save_path)
|
||||||
|
print('模型已保存到', model_save_path)
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def evaluate(loader, model, device):
|
||||||
|
model.eval()
|
||||||
|
scores = []
|
||||||
|
for titles, keywords in tqdm(loader):
|
||||||
|
logits = model.calc_sim(titles, keywords)
|
||||||
|
labels = torch.arange(len(titles), device=device)
|
||||||
|
scores.append(score(logits, labels))
|
||||||
|
return sum(scores) / len(scores)
|
||||||
|
|
||||||
|
|
||||||
|
def score(logits, labels):
|
||||||
|
return (accuracy(logits.argmax(dim=1), labels) + accuracy(logits.argmax(dim=0), labels)) / 2
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def infer(args):
|
||||||
|
device = get_device(args.device)
|
||||||
|
model = ContrastiveSciBERT(args.num_hidden, args.tau, device).to(device)
|
||||||
|
model.load_state_dict(torch.load(MODEL_DIR / 'scibert.pt', map_location=device))
|
||||||
|
model.eval()
|
||||||
|
|
||||||
|
raw_path = DATA_DIR / 'oag/cs'
|
||||||
|
dataset = OAGCSContrastDataset(raw_path / 'mag_papers.txt', split='all')
|
||||||
|
loader = DataLoader(dataset, batch_size=args.batch_size, collate_fn=collate)
|
||||||
|
print('正在推断论文向量...')
|
||||||
|
h = []
|
||||||
|
for titles, _ in tqdm(loader):
|
||||||
|
h.append(model.get_embeds(titles).detach().cpu())
|
||||||
|
h = torch.cat(h) # (N_paper, d_hid)
|
||||||
|
h = h / h.norm(dim=1, keepdim=True)
|
||||||
|
torch.save(h, raw_path / 'paper_feat.pkl')
|
||||||
|
print('论文向量已保存到', raw_path / 'paper_feat.pkl')
|
||||||
|
|
||||||
|
fields = [f['name'] for f in iter_json(raw_path / 'mag_fields.txt')]
|
||||||
|
loader = DataLoader(fields, batch_size=args.batch_size)
|
||||||
|
print('正在推断领域向量...')
|
||||||
|
h = []
|
||||||
|
for fields in tqdm(loader):
|
||||||
|
h.append(model.get_embeds(fields).detach().cpu())
|
||||||
|
h = torch.cat(h) # (N_field, d_hid)
|
||||||
|
h = h / h.norm(dim=1, keepdim=True)
|
||||||
|
torch.save(h, raw_path / 'field_feat.pkl')
|
||||||
|
print('领域向量已保存到', raw_path / 'field_feat.pkl')
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='通过论文标题和关键词的对比学习对SciBERT模型进行fine-tune')
|
||||||
|
subparsers = parser.add_subparsers()
|
||||||
|
|
||||||
|
train_parser = subparsers.add_parser('train', help='训练')
|
||||||
|
train_parser.add_argument('--seed', type=int, default=42, help='随机数种子')
|
||||||
|
train_parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
train_parser.add_argument('--num-hidden', type=int, default=128, help='隐藏层维数')
|
||||||
|
train_parser.add_argument('--tau', type=float, default=0.07, help='温度参数')
|
||||||
|
train_parser.add_argument('--epochs', type=int, default=5, help='训练epoch数')
|
||||||
|
train_parser.add_argument('--batch-size', type=int, default=64, help='批大小')
|
||||||
|
train_parser.add_argument('--lr', type=float, default=5e-5, help='学习率')
|
||||||
|
train_parser.set_defaults(func=train)
|
||||||
|
|
||||||
|
infer_parser = subparsers.add_parser('infer', help='推断')
|
||||||
|
infer_parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
infer_parser.add_argument('--num-hidden', type=int, default=128, help='隐藏层维数')
|
||||||
|
infer_parser.add_argument('--tau', type=float, default=0.07, help='温度参数')
|
||||||
|
infer_parser.add_argument('--batch-size', type=int, default=64, help='批大小')
|
||||||
|
infer_parser.set_defaults(func=infer)
|
||||||
|
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
args.func(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,23 @@
|
||||||
|
import os
|
||||||
|
import tempfile
|
||||||
|
import zipfile
|
||||||
|
|
||||||
|
from gnnrec.kgrec.utils import iter_json
|
||||||
|
|
||||||
|
|
||||||
|
def iter_lines(raw_path, data_type):
|
||||||
|
"""依次迭代OAG数据集某种类型数据所有txt文件的每一行并将JSON解析为字典
|
||||||
|
|
||||||
|
:param raw_path: str 原始zip文件所在目录
|
||||||
|
:param data_type: str 数据类型,author, paper, venue, affiliation之一
|
||||||
|
:return: Iterable[dict]
|
||||||
|
"""
|
||||||
|
with tempfile.TemporaryDirectory() as tmp:
|
||||||
|
for zip_file in os.listdir(raw_path):
|
||||||
|
if zip_file.startswith(f'mag_{data_type}s'):
|
||||||
|
with zipfile.ZipFile(os.path.join(raw_path, zip_file)) as z:
|
||||||
|
for txt in z.namelist():
|
||||||
|
print(f'{zip_file}\\{txt}')
|
||||||
|
txt_file = z.extract(txt, tmp)
|
||||||
|
yield from iter_json(txt_file)
|
||||||
|
os.remove(txt_file)
|
||||||
|
|
@ -0,0 +1,157 @@
|
||||||
|
# oag-cs数据集
|
||||||
|
## 原始数据
|
||||||
|
[Open Academic Graph 2.1](https://www.aminer.cn/oag-2-1)
|
||||||
|
|
||||||
|
使用其中的微软学术(MAG)数据,总大小169 GB
|
||||||
|
|
||||||
|
| 类型 | 文件 | 总量 |
|
||||||
|
| --- | --- | --- |
|
||||||
|
| author | mag_authors_{0-1}.zip | 243477150 |
|
||||||
|
| paper | mag_papers_{0-16}.zip | 240255240 |
|
||||||
|
| venue | mag_venues.zip | 53422 |
|
||||||
|
| affiliation | mag_affiliations.zip | 25776 |
|
||||||
|
|
||||||
|
## 字段分析
|
||||||
|
假设原始zip文件所在目录为data/oag/mag/
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.analyze author data/oag/mag/
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.analyze paper data/oag/mag/
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.analyze venue data/oag/mag/
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.analyze affiliation data/oag/mag/
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
数据类型: venue
|
||||||
|
总量: 53422
|
||||||
|
最大字段集合: {'JournalId', 'NormalizedName', 'id', 'ConferenceId', 'DisplayName'}
|
||||||
|
最小字段集合: {'NormalizedName', 'DisplayName', 'id'}
|
||||||
|
字段出现比例: {'id': 1.0, 'JournalId': 0.9162891692561117, 'DisplayName': 1.0, 'NormalizedName': 1.0, 'ConferenceId': 0.08371083074388828}
|
||||||
|
示例: {'id': 2898614270, 'JournalId': 2898614270, 'DisplayName': 'Revista de Psiquiatría y Salud Mental', 'NormalizedName': 'revista de psiquiatria y salud mental'}
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
数据类型: affiliation
|
||||||
|
总量: 25776
|
||||||
|
最大字段集合: {'id', 'NormalizedName', 'url', 'Latitude', 'Longitude', 'WikiPage', 'DisplayName'}
|
||||||
|
最小字段集合: {'id', 'NormalizedName', 'Latitude', 'Longitude', 'DisplayName'}
|
||||||
|
字段出现比例: {'id': 1.0, 'DisplayName': 1.0, 'NormalizedName': 1.0, 'WikiPage': 0.9887880198634389, 'Latitude': 1.0, 'Longitude': 1.0, 'url': 0.6649984481688392}
|
||||||
|
示例: {'id': 3032752892, 'DisplayName': 'Universidad Internacional de La Rioja', 'NormalizedName': 'universidad internacional de la rioja', 'WikiPage': 'https://en.wikipedia.org/wiki/International_University_of_La_Rioja', 'Latitude': '42.46270', 'Longitude': '2.45500', 'url': 'https://en.unir.net/'}
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
数据类型: author
|
||||||
|
总量: 243477150
|
||||||
|
最大字段集合: {'normalized_name', 'name', 'pubs', 'n_pubs', 'n_citation', 'last_known_aff_id', 'id'}
|
||||||
|
最小字段集合: {'normalized_name', 'name', 'n_pubs', 'pubs', 'id'}
|
||||||
|
字段出现比例: {'id': 1.0, 'name': 1.0, 'normalized_name': 1.0, 'last_known_aff_id': 0.17816547055853085, 'pubs': 1.0, 'n_pubs': 1.0, 'n_citation': 0.39566894470384595}
|
||||||
|
示例: {'id': 3040689058, 'name': 'Jeong Hoe Heo', 'normalized_name': 'jeong hoe heo', 'last_known_aff_id': '59412607', 'pubs': [{'i': 2770054759, 'r': 10}], 'n_pubs': 1, 'n_citation': 44}
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
数据类型: paper
|
||||||
|
总量: 240255240
|
||||||
|
最大字段集合: {'issue', 'authors', 'page_start', 'publisher', 'doc_type', 'title', 'id', 'doi', 'references', 'volume', 'fos', 'n_citation', 'venue', 'page_end', 'year', 'indexed_abstract', 'url'}
|
||||||
|
最小字段集合: {'id'}
|
||||||
|
字段出现比例: {'id': 1.0, 'title': 0.9999999958377599, 'authors': 0.9998381970774082, 'venue': 0.5978255167296247, 'year': 0.9999750931550963, 'page_start': 0.5085962370685443, 'page_end': 0.4468983111460961, 'publisher': 0.5283799512551735, 'issue': 0.41517357124031923, 'url': 0.9414517743712895, 'doi': 0.37333226530251745, 'indexed_abstract': 0.5832887141192009, 'fos': 0.8758779954185391, 'n_citation': 0.3795505812901313, 'doc_type': 0.6272126634990355, 'volume': 0.43235134434528877, 'references': 0.3283648464857624}
|
||||||
|
示例: {
|
||||||
|
'id': 2507145174,
|
||||||
|
'title': 'Structure-Activity Relationships and Kinetic Studies of Peptidic Antagonists of CBX Chromodomains.',
|
||||||
|
'authors': [{'name': 'Jacob I. Stuckey', 'id': 2277886111, 'org': 'Center for Integrative Chemical Biology and Drug Discovery, Division of Chemical Biology and Medicinal Chemistry, UNC Eshelman School of Pharmacy, University of North Carolina at Chapel Hill , Chapel Hill, North Carolina 27599, United States.\r', 'org_id': 114027177}, {'name': 'Catherine Simpson', 'id': 2098592917, 'org': 'Center for Integrative Chemical Biology and Drug Discovery, Division of Chemical Biology and Medicinal Chemistry, UNC Eshelman School of Pharmacy, University of North Carolina at Chapel Hill , Chapel Hill, North Carolina 27599, United States.\r', 'org_id': 114027177}, ...],
|
||||||
|
'venue': {'name': 'Journal of Medicinal Chemistry', 'id': 162030435},
|
||||||
|
'year': 2016, 'n_citation': 13, 'page_start': '8913', 'page_end': '8923', 'doc_type': 'Journal', 'publisher': 'American Chemical Society', 'volume': '59', 'issue': '19', 'doi': '10.1021/ACS.JMEDCHEM.6B00801',
|
||||||
|
'references': [1976962550, 1982791788, 1988515229, 2000127174, 2002698073, 2025496265, 2032915605, 2050256263, 2059999434, 2076333986, 2077957449, 2082815186, 2105928678, 2116982909, 2120121380, 2146641795, 2149566960, 2156518222, 2160723017, 2170079272, 2207535250, 2270756322, 2326025506, 2327795699, 2332365177, 2346619380, 2466657786],
|
||||||
|
'indexed_abstract': '{"IndexLength":108,"InvertedIndex":{"To":[0],"better":[1],"understand":[2],"the":[3,19,54,70,80,95],"contribution":[4],"of":[5,21,31,47,56,82,90,98],"methyl-lysine":[6],"(Kme)":[7],"binding":[8,33,96],"proteins":[9],"to":[10,79],"various":[11],"disease":[12],"states,":[13],"we":[14,68],"recently":[15],"developed":[16],"and":[17,36,43,63,73,84],"reported":[18],"discovery":[20,46],"1":[22,48,83],"(UNC3866),":[23],"a":[24],"chemical":[25],"probe":[26],"that":[27,77],"targets":[28],"two":[29],"families":[30],"Kme":[32],"proteins,":[34],"CBX":[35],"CDY":[37],"chromodomains,":[38],"with":[39,61,101],"selectivity":[40],"for":[41,87],"CBX4":[42],"-7.":[44],"The":[45],"was":[49],"enabled":[50],"in":[51],"part":[52],"by":[53,93,105],"use":[55],"molecular":[57],"dynamics":[58],"simulations":[59],"performed":[60],"CBX7":[62,102],"its":[64],"endogenous":[65],"substrate.":[66],"Herein,":[67],"describe":[69],"design,":[71],"synthesis,":[72],"structure–activity":[74],"relationship":[75],"studies":[76],"led":[78],"development":[81],"provide":[85],"support":[86],"our":[88,99],"model":[89],"CBX7–ligand":[91],"recognition":[92],"examining":[94],"kinetics":[97],"antagonists":[100],"as":[103],"determined":[104],"surface-plasmon":[106],"resonance.":[107]}}',
|
||||||
|
'fos': [{'name': 'chemistry', 'w': 0.36301}, {'name': 'chemical probe', 'w': 0.0}, {'name': 'receptor ligand kinetics', 'w': 0.46173}, {'name': 'dna binding protein', 'w': 0.42292}, {'name': 'biochemistry', 'w': 0.39304}],
|
||||||
|
'url': ['https://pubs.acs.org/doi/full/10.1021/acs.jmedchem.6b00801', 'https://www.ncbi.nlm.nih.gov/pubmed/27571219', 'http://pubsdc3.acs.org/doi/abs/10.1021/acs.jmedchem.6b00801']
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## 第1步:抽取计算机领域的子集
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.extract_cs data/oag/mag/
|
||||||
|
```
|
||||||
|
|
||||||
|
筛选近10年计算机领域的论文,从微软学术抓取了计算机科学下的34个二级领域作为领域字段过滤条件,过滤掉主要字段为空的论文
|
||||||
|
|
||||||
|
二级领域列表:[CS_FIELD_L2](config.py)
|
||||||
|
|
||||||
|
输出5个文件:
|
||||||
|
|
||||||
|
(1)学者:mag_authors.txt
|
||||||
|
|
||||||
|
`{"id": aid, "name": "author name", "org": oid}`
|
||||||
|
|
||||||
|
(2)论文:mag_papers.txt
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"id": pid,
|
||||||
|
"title": "paper title",
|
||||||
|
"authors": [aid],
|
||||||
|
"venue": vid,
|
||||||
|
"year": year,
|
||||||
|
"abstract": "abstract",
|
||||||
|
"fos": ["field"],
|
||||||
|
"references": [pid],
|
||||||
|
"n_citation": n_citation
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
(3)期刊:mag_venues.txt
|
||||||
|
|
||||||
|
`{"id": vid, "name": "venue name"}`
|
||||||
|
|
||||||
|
(4)机构:mag_institutions.txt
|
||||||
|
|
||||||
|
`{"id": oid, "name": "org name"}`
|
||||||
|
|
||||||
|
(5)领域:mag_fields.txt
|
||||||
|
|
||||||
|
`{"id": fid, "name": "field name"}`
|
||||||
|
|
||||||
|
## 第2步:预训练论文和领域向量
|
||||||
|
通过论文标题和关键词的**对比学习**对预训练的SciBERT模型进行fine-tune,之后将隐藏层输出的128维向量作为paper和field顶点的输入特征
|
||||||
|
|
||||||
|
预训练的SciBERT模型来自Transformers [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased)
|
||||||
|
|
||||||
|
注:由于原始数据不包含关键词,因此使用研究领域(fos字段)作为关键词
|
||||||
|
|
||||||
|
1. fine-tune
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.fine_tune train
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
Epoch 0 | Loss 0.3470 | Train Acc 0.9105 | Val Acc 0.9426
|
||||||
|
Epoch 1 | Loss 0.1609 | Train Acc 0.9599 | Val Acc 0.9535
|
||||||
|
Epoch 2 | Loss 0.1065 | Train Acc 0.9753 | Val Acc 0.9573
|
||||||
|
Epoch 3 | Loss 0.0741 | Train Acc 0.9846 | Val Acc 0.9606
|
||||||
|
Epoch 4 | Loss 0.0551 | Train Acc 0.9898 | Val Acc 0.9614
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 推断
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.fine_tune infer
|
||||||
|
```
|
||||||
|
|
||||||
|
预训练的论文和领域向量分别保存到paper_feat.pkl和field_feat.pkl文件(已归一化),
|
||||||
|
该向量既可用于GNN模型的输入特征,也可用于计算相似度召回论文
|
||||||
|
|
||||||
|
## 第3步:构造图数据集
|
||||||
|
将以上5个txt和2个pkl文件压缩为oag-cs.zip,得到oag-cs数据集的原始数据
|
||||||
|
|
||||||
|
将oag-cs.zip文件放到`$DGL_DOWNLOAD_DIR`目录下(环境变量`DGL_DOWNLOAD_DIR`默认为`~/.dgl/`)
|
||||||
|
|
||||||
|
```python
|
||||||
|
from gnnrec.kgrec.data import OAGCSDataset
|
||||||
|
|
||||||
|
data = OAGCSDataset()
|
||||||
|
g = data[0]
|
||||||
|
```
|
||||||
|
|
||||||
|
统计数据见 [OAGCSDataset](oagcs.py) 的文档字符串
|
||||||
|
|
||||||
|
## 下载地址
|
||||||
|
下载地址:<https://pan.baidu.com/s/1ayH3tQxsiDDnqPoXhR0Ekg>,提取码:2ylp
|
||||||
|
|
||||||
|
大小:1.91 GB,解压后大小:3.93 GB
|
||||||
|
|
@ -0,0 +1,67 @@
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
|
||||||
|
from .oagcs import OAGCSDataset
|
||||||
|
|
||||||
|
|
||||||
|
class OAGVenueDataset(OAGCSDataset):
|
||||||
|
"""oag-cs期刊分类数据集,删除了venue顶点,作为paper顶点的标签
|
||||||
|
|
||||||
|
属性
|
||||||
|
-----
|
||||||
|
* num_classes: 类别数
|
||||||
|
* predict_ntype: 目标顶点类型
|
||||||
|
|
||||||
|
增加的paper顶点属性
|
||||||
|
-----
|
||||||
|
* label: tensor(N_paper) 论文所属期刊(-1~176)
|
||||||
|
* train_mask, val_mask, test_mask: tensor(N_paper) 数量分别为402457, 280762, 255387,划分方式:年份
|
||||||
|
"""
|
||||||
|
|
||||||
|
def load(self):
|
||||||
|
super().load()
|
||||||
|
for k in ('train_mask', 'val_mask', 'test_mask'):
|
||||||
|
self.g.nodes['paper'].data[k] = self.g.nodes['paper'].data[k].bool()
|
||||||
|
|
||||||
|
def process(self):
|
||||||
|
super().process()
|
||||||
|
venue_in_degrees = self.g.in_degrees(etype='published_at')
|
||||||
|
drop_venue_id = torch.nonzero(venue_in_degrees < 1000, as_tuple=True)[0]
|
||||||
|
# 删除论文数1000以下的期刊,剩余360种
|
||||||
|
tmp_g = dgl.remove_nodes(self.g, drop_venue_id, 'venue')
|
||||||
|
|
||||||
|
pv_p, pv_v = tmp_g.edges(etype='published_at')
|
||||||
|
labels = torch.full((tmp_g.num_nodes('paper'),), -1)
|
||||||
|
mask = torch.full((tmp_g.num_nodes('paper'),), False)
|
||||||
|
labels[pv_p] = pv_v
|
||||||
|
mask[pv_p] = True
|
||||||
|
|
||||||
|
g = dgl.heterograph({etype: tmp_g.edges(etype=etype) for etype in [
|
||||||
|
('author', 'writes', 'paper'), ('paper', 'has_field', 'field'),
|
||||||
|
('paper', 'cites', 'paper'), ('author', 'affiliated_with', 'institution')
|
||||||
|
]})
|
||||||
|
for ntype in g.ntypes:
|
||||||
|
g.nodes[ntype].data.update(self.g.nodes[ntype].data)
|
||||||
|
for etype in g.canonical_etypes:
|
||||||
|
g.edges[etype].data.update(self.g.edges[etype].data)
|
||||||
|
|
||||||
|
year = g.nodes['paper'].data['year']
|
||||||
|
g.nodes['paper'].data.update({
|
||||||
|
'label': labels,
|
||||||
|
'train_mask': mask & (year < 2015),
|
||||||
|
'val_mask': mask & (year >= 2015) & (year < 2018),
|
||||||
|
'test_mask': mask & (year >= 2018)
|
||||||
|
})
|
||||||
|
self.g = g
|
||||||
|
|
||||||
|
@property
|
||||||
|
def name(self):
|
||||||
|
return 'oag-venue'
|
||||||
|
|
||||||
|
@property
|
||||||
|
def num_classes(self):
|
||||||
|
return 360
|
||||||
|
|
||||||
|
@property
|
||||||
|
def predict_ntype(self):
|
||||||
|
return 'paper'
|
||||||
|
|
@ -0,0 +1,28 @@
|
||||||
|
import argparse
|
||||||
|
|
||||||
|
from gnnrec.hge.metapath2vec.random_walk import random_walk
|
||||||
|
from gnnrec.hge.utils import add_reverse_edges
|
||||||
|
from gnnrec.kgrec.data import OAGCSDataset
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='oag-cs数据集 metapath2vec基于元路径的随机游走')
|
||||||
|
parser.add_argument('--num-walks', type=int, default=4, help='每个顶点游走次数')
|
||||||
|
parser.add_argument('--walk-length', type=int, default=10, help='元路径重复次数')
|
||||||
|
parser.add_argument('output_file', help='输出文件名')
|
||||||
|
args = parser.parse_args()
|
||||||
|
|
||||||
|
data = OAGCSDataset()
|
||||||
|
g = add_reverse_edges(data[0])
|
||||||
|
metapaths = {
|
||||||
|
'author': ['writes', 'published_at', 'published_at_rev', 'writes_rev'], # APVPA
|
||||||
|
'paper': ['writes_rev', 'writes', 'published_at', 'published_at_rev', 'has_field', 'has_field_rev'], # PAPVPFP
|
||||||
|
'venue': ['published_at_rev', 'writes_rev', 'writes', 'published_at'], # VPAPV
|
||||||
|
'field': ['has_field_rev', 'writes_rev', 'writes', 'has_field'], # FPAPF
|
||||||
|
'institution': ['affiliated_with_rev', 'writes', 'writes_rev', 'affiliated_with'] # IAPAI
|
||||||
|
}
|
||||||
|
random_walk(g, metapaths, args.num_walks, args.walk_length, args.output_file)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,32 @@
|
||||||
|
import json
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR
|
||||||
|
|
||||||
|
|
||||||
|
class Context:
|
||||||
|
|
||||||
|
def __init__(self, recall_ctx, author_rank):
|
||||||
|
"""学者排名模块上下文对象
|
||||||
|
|
||||||
|
:param recall_ctx: gnnrec.kgrec.recall.Context
|
||||||
|
:param author_rank: {field_id: [author_id]} 领域学者排名
|
||||||
|
"""
|
||||||
|
self.recall_ctx = recall_ctx
|
||||||
|
# 之后需要:author_embeds
|
||||||
|
self.author_rank = author_rank
|
||||||
|
|
||||||
|
|
||||||
|
def get_context(recall_ctx):
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_train.json') as f:
|
||||||
|
author_rank = json.load(f)
|
||||||
|
return Context(recall_ctx, author_rank)
|
||||||
|
|
||||||
|
|
||||||
|
def rank(ctx, query):
|
||||||
|
"""根据输入的查询词在oag-cs数据集计算学者排名
|
||||||
|
|
||||||
|
:param ctx: Context 上下文对象
|
||||||
|
:param query: str 查询词
|
||||||
|
:return: List[float], List[int] 学者得分和id,按得分降序排序
|
||||||
|
"""
|
||||||
|
return [], ctx.author_rank.get(query, [])
|
||||||
|
|
@ -0,0 +1,120 @@
|
||||||
|
# 基于图神经网络的推荐算法
|
||||||
|
## 数据集
|
||||||
|
oag-cs - 使用OAG微软学术数据构造的计算机领域的学术网络(见 [readme](data/readme.md))
|
||||||
|
|
||||||
|
## 预训练顶点嵌入
|
||||||
|
使用metapath2vec(随机游走+word2vec)预训练顶点嵌入,作为GNN模型的顶点输入特征
|
||||||
|
1. 随机游走
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.random_walk model/word2vec/oag_cs_corpus.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
2. 训练词向量
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.hge.metapath2vec.train_word2vec --size=128 --workers=8 model/word2vec/oag_cs_corpus.txt model/word2vec/oag_cs.model
|
||||||
|
```
|
||||||
|
|
||||||
|
## 召回
|
||||||
|
使用微调后的SciBERT模型(见 [readme](data/readme.md) 第2步)将查询词编码为向量,与预先计算好的论文标题向量计算余弦相似度,取top k
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.recall
|
||||||
|
```
|
||||||
|
|
||||||
|
召回结果示例:
|
||||||
|
|
||||||
|
graph neural network
|
||||||
|
```
|
||||||
|
0.9629 Aggregation Graph Neural Networks
|
||||||
|
0.9579 Neural Graph Learning: Training Neural Networks Using Graphs
|
||||||
|
0.9556 Heterogeneous Graph Neural Network
|
||||||
|
0.9552 Neural Graph Machines: Learning Neural Networks Using Graphs
|
||||||
|
0.9490 On the choice of graph neural network architectures
|
||||||
|
0.9474 Measuring and Improving the Use of Graph Information in Graph Neural Networks
|
||||||
|
0.9362 Challenging the generalization capabilities of Graph Neural Networks for network modeling
|
||||||
|
0.9295 Strategies for Pre-training Graph Neural Networks
|
||||||
|
0.9142 Supervised Neural Network Models for Processing Graphs
|
||||||
|
0.9112 Geometrically Principled Connections in Graph Neural Networks
|
||||||
|
```
|
||||||
|
|
||||||
|
recommendation algorithm based on knowledge graph
|
||||||
|
```
|
||||||
|
0.9172 Research on Video Recommendation Algorithm Based on Knowledge Reasoning of Knowledge Graph
|
||||||
|
0.8972 An Improved Recommendation Algorithm in Knowledge Network
|
||||||
|
0.8558 A personalized recommendation algorithm based on interest graph
|
||||||
|
0.8431 An Improved Recommendation Algorithm Based on Graph Model
|
||||||
|
0.8334 The Research of Recommendation Algorithm based on Complete Tripartite Graph Model
|
||||||
|
0.8220 Recommendation Algorithm based on Link Prediction and Domain Knowledge in Retail Transactions
|
||||||
|
0.8167 Recommendation Algorithm Based on Graph-Model Considering User Background Information
|
||||||
|
0.8034 A Tripartite Graph Recommendation Algorithm Based on Item Information and User Preference
|
||||||
|
0.7774 Improvement of TF-IDF Algorithm Based on Knowledge Graph
|
||||||
|
0.7770 Graph Searching Algorithms for Semantic-Social Recommendation
|
||||||
|
```
|
||||||
|
|
||||||
|
scholar disambiguation
|
||||||
|
```
|
||||||
|
0.9690 Scholar search-oriented author disambiguation
|
||||||
|
0.9040 Author name disambiguation in scientific collaboration and mobility cases
|
||||||
|
0.8901 Exploring author name disambiguation on PubMed-scale
|
||||||
|
0.8852 Author Name Disambiguation in Heterogeneous Academic Networks
|
||||||
|
0.8797 KDD Cup 2013: author disambiguation
|
||||||
|
0.8796 A survey of author name disambiguation techniques: 2010–2016
|
||||||
|
0.8721 Who is Who: Name Disambiguation in Large-Scale Scientific Literature
|
||||||
|
0.8660 Use of ResearchGate and Google CSE for author name disambiguation
|
||||||
|
0.8643 Automatic Methods for Disambiguating Author Names in Bibliographic Data Repositories
|
||||||
|
0.8641 A brief survey of automatic methods for author name disambiguation
|
||||||
|
```
|
||||||
|
|
||||||
|
## 精排
|
||||||
|
### 构造ground truth
|
||||||
|
(1)验证集
|
||||||
|
|
||||||
|
从AMiner发布的 [AI 2000人工智能全球最具影响力学者榜单](https://www.aminer.cn/ai2000) 抓取人工智能20个子领域的top 100学者
|
||||||
|
```shell
|
||||||
|
pip install scrapy>=2.3.0
|
||||||
|
cd gnnrec/kgrec/data/preprocess
|
||||||
|
scrapy runspider ai2000_crawler.py -a save_path=/home/zzy/GNN-Recommendation/data/rank/ai2000.json
|
||||||
|
```
|
||||||
|
|
||||||
|
与oag-cs数据集的学者匹配,并人工确认一些排名较高但未匹配上的学者,作为学者排名ground truth验证集
|
||||||
|
```shell
|
||||||
|
export DJANGO_SETTINGS_MODULE=academic_graph.settings.common
|
||||||
|
export SECRET_KEY=xxx
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.build_author_rank build-val
|
||||||
|
```
|
||||||
|
|
||||||
|
(2)训练集
|
||||||
|
|
||||||
|
参考AI 2000的计算公式,根据某个领域的论文引用数加权求和构造学者排名,作为ground truth训练集
|
||||||
|
|
||||||
|
计算公式:
|
||||||
|
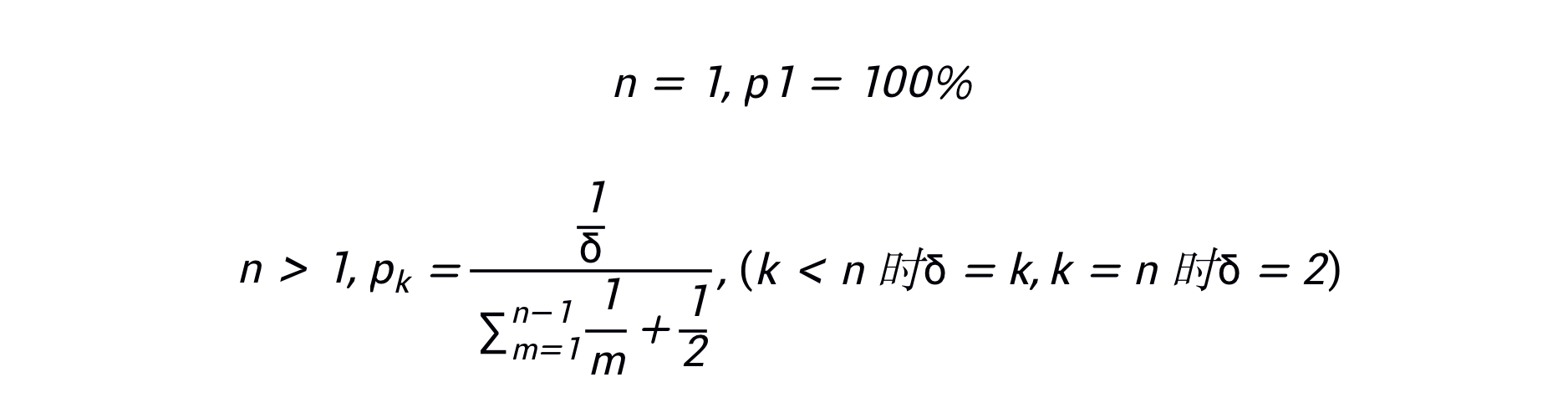
|
||||||
|
即:假设一篇论文有n个作者,第k作者的权重为1/k,最后一个视为通讯作者,权重为1/2,归一化之后计算论文引用数的加权求和
|
||||||
|
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.build_author_rank build-train
|
||||||
|
```
|
||||||
|
|
||||||
|
(3)评估ground truth训练集的质量
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.build_author_rank eval
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
nDGC@100=0.2420 Precision@100=0.1859 Recall@100=0.2016
|
||||||
|
nDGC@50=0.2308 Precision@50=0.2494 Recall@50=0.1351
|
||||||
|
nDGC@20=0.2492 Precision@20=0.3118 Recall@20=0.0678
|
||||||
|
nDGC@10=0.2743 Precision@10=0.3471 Recall@10=0.0376
|
||||||
|
nDGC@5=0.3165 Precision@5=0.3765 Recall@5=0.0203
|
||||||
|
```
|
||||||
|
|
||||||
|
(4)采样三元组
|
||||||
|
|
||||||
|
从学者排名训练集中采样三元组(t, ap, an),表示对于领域t,学者ap的排名在an之前
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.data.preprocess.build_author_rank sample
|
||||||
|
```
|
||||||
|
|
||||||
|
### 训练GNN模型
|
||||||
|
```shell
|
||||||
|
python -m gnnrec.kgrec.train model/word2vec/oag-cs.model model/garec_gnn.pt data/rank/author_embed.pt
|
||||||
|
```
|
||||||
|
|
@ -0,0 +1,53 @@
|
||||||
|
import torch
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR, MODEL_DIR
|
||||||
|
from gnnrec.kgrec.data import OAGCSContrastDataset
|
||||||
|
from gnnrec.kgrec.scibert import ContrastiveSciBERT
|
||||||
|
|
||||||
|
|
||||||
|
class Context:
|
||||||
|
|
||||||
|
def __init__(self, paper_embeds, scibert_model):
|
||||||
|
"""论文召回模块上下文对象
|
||||||
|
|
||||||
|
:param paper_embeds: tensor(N, d) 论文标题向量
|
||||||
|
:param scibert_model: ContrastiveSciBERT 微调后的SciBERT模型
|
||||||
|
"""
|
||||||
|
self.paper_embeds = paper_embeds
|
||||||
|
self.scibert_model = scibert_model
|
||||||
|
|
||||||
|
|
||||||
|
def get_context():
|
||||||
|
paper_embeds = torch.load(DATA_DIR / 'oag/cs/paper_feat.pkl', map_location='cpu')
|
||||||
|
scibert_model = ContrastiveSciBERT(128, 0.07)
|
||||||
|
scibert_model.load_state_dict(torch.load(MODEL_DIR / 'scibert.pt', map_location='cpu'))
|
||||||
|
return Context(paper_embeds, scibert_model)
|
||||||
|
|
||||||
|
|
||||||
|
def recall(ctx, query, k=1000):
|
||||||
|
"""根据输入的查询词在oag-cs数据集召回论文
|
||||||
|
|
||||||
|
:param ctx: Context 上下文对象
|
||||||
|
:param query: str 查询词
|
||||||
|
:param k: int, optional 召回论文数量,默认为1000
|
||||||
|
:return: List[float], List[int] Top k论文的相似度和id,按相似度降序排序
|
||||||
|
"""
|
||||||
|
q = ctx.scibert_model.get_embeds(query) # (1, d)
|
||||||
|
q = q / q.norm()
|
||||||
|
similarity = torch.mm(ctx.paper_embeds, q.t()).squeeze(dim=1) # (N,)
|
||||||
|
score, pid = similarity.topk(k, dim=0)
|
||||||
|
return score.tolist(), pid.tolist()
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
ctx = get_context()
|
||||||
|
paper_titles = OAGCSContrastDataset(DATA_DIR / 'oag/cs/mag_papers.txt', 'all')
|
||||||
|
while True:
|
||||||
|
query = input('query> ').strip()
|
||||||
|
score, pid = recall(ctx, query, 10)
|
||||||
|
for i in range(len(pid)):
|
||||||
|
print('{:.4f}\t{}'.format(score[i], paper_titles[pid[i]][0]))
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,61 @@
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from transformers import AutoTokenizer, AutoModel
|
||||||
|
|
||||||
|
|
||||||
|
class ContrastiveSciBERT(nn.Module):
|
||||||
|
|
||||||
|
def __init__(self, out_dim, tau, device='cpu'):
|
||||||
|
"""用于对比学习的SciBERT模型
|
||||||
|
|
||||||
|
:param out_dim: int 输出特征维数
|
||||||
|
:param tau: float 温度参数τ
|
||||||
|
:param device: torch.device, optional 默认为CPU
|
||||||
|
"""
|
||||||
|
super().__init__()
|
||||||
|
self.tau = tau
|
||||||
|
self.device = device
|
||||||
|
self.tokenizer = AutoTokenizer.from_pretrained('allenai/scibert_scivocab_uncased')
|
||||||
|
self.model = AutoModel.from_pretrained('allenai/scibert_scivocab_uncased').to(device)
|
||||||
|
self.linear = nn.Linear(self.model.config.hidden_size, out_dim)
|
||||||
|
|
||||||
|
def get_embeds(self, texts, max_length=64):
|
||||||
|
"""将文本编码为向量
|
||||||
|
|
||||||
|
:param texts: List[str] 输入文本列表,长度为N
|
||||||
|
:param max_length: int, optional padding最大长度,默认为64
|
||||||
|
:return: tensor(N, d_out)
|
||||||
|
"""
|
||||||
|
encoded = self.tokenizer(
|
||||||
|
texts, padding='max_length', truncation=True, max_length=max_length, return_tensors='pt'
|
||||||
|
).to(self.device)
|
||||||
|
return self.linear(self.model(**encoded).pooler_output)
|
||||||
|
|
||||||
|
def calc_sim(self, texts_a, texts_b):
|
||||||
|
"""计算两组文本的相似度
|
||||||
|
|
||||||
|
:param texts_a: List[str] 输入文本A列表,长度为N
|
||||||
|
:param texts_b: List[str] 输入文本B列表,长度为N
|
||||||
|
:return: tensor(N, N) 相似度矩阵,S[i, j] = cos(a[i], b[j]) / τ
|
||||||
|
"""
|
||||||
|
embeds_a = self.get_embeds(texts_a) # (N, d_out)
|
||||||
|
embeds_b = self.get_embeds(texts_b) # (N, d_out)
|
||||||
|
embeds_a = embeds_a / embeds_a.norm(dim=1, keepdim=True)
|
||||||
|
embeds_b = embeds_b / embeds_b.norm(dim=1, keepdim=True)
|
||||||
|
return embeds_a @ embeds_b.t() / self.tau
|
||||||
|
|
||||||
|
def forward(self, texts_a, texts_b):
|
||||||
|
"""计算两组文本的对比损失
|
||||||
|
|
||||||
|
:param texts_a: List[str] 输入文本A列表,长度为N
|
||||||
|
:param texts_b: List[str] 输入文本B列表,长度为N
|
||||||
|
:return: tensor(N, N), float A对B的相似度矩阵,对比损失
|
||||||
|
"""
|
||||||
|
# logits_ab等价于预测概率,对比损失等价于交叉熵损失
|
||||||
|
logits_ab = self.calc_sim(texts_a, texts_b)
|
||||||
|
logits_ba = logits_ab.t()
|
||||||
|
labels = torch.arange(len(texts_a), device=self.device)
|
||||||
|
loss_ab = F.cross_entropy(logits_ab, labels)
|
||||||
|
loss_ba = F.cross_entropy(logits_ba, labels)
|
||||||
|
return logits_ab, (loss_ab + loss_ba) / 2
|
||||||
|
|
@ -0,0 +1,133 @@
|
||||||
|
import argparse
|
||||||
|
import json
|
||||||
|
import math
|
||||||
|
import warnings
|
||||||
|
|
||||||
|
import numpy as np
|
||||||
|
import torch
|
||||||
|
import torch.optim as optim
|
||||||
|
import torch.nn.functional as F
|
||||||
|
from dgl.dataloading import MultiLayerNeighborSampler, NodeDataLoader
|
||||||
|
from sklearn.metrics import ndcg_score
|
||||||
|
from tqdm import tqdm
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR
|
||||||
|
from gnnrec.hge.rhgnn.model import RHGNN
|
||||||
|
from gnnrec.hge.utils import set_random_seed, get_device, add_reverse_edges, add_node_feat
|
||||||
|
from gnnrec.kgrec.data import OAGCSDataset
|
||||||
|
from gnnrec.kgrec.utils import TripletNodeDataLoader
|
||||||
|
|
||||||
|
|
||||||
|
def load_data(device):
|
||||||
|
g = add_reverse_edges(OAGCSDataset()[0]).to(device)
|
||||||
|
field_feat = g.nodes['field'].data['feat']
|
||||||
|
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_triplets.txt') as f:
|
||||||
|
triplets = torch.tensor([[int(x) for x in line.split()] for line in f], device=device)
|
||||||
|
|
||||||
|
with open(DATA_DIR / 'rank/author_rank_train.json') as f:
|
||||||
|
author_rank_train = json.load(f)
|
||||||
|
train_fields = list(author_rank_train)
|
||||||
|
true_relevance = np.zeros((len(train_fields), g.num_nodes('author')), dtype=np.int32)
|
||||||
|
for i, f in enumerate(train_fields):
|
||||||
|
for r, a in enumerate(author_rank_train[f]):
|
||||||
|
true_relevance[i, a] = math.ceil((100 - r) / 10)
|
||||||
|
train_fields = list(map(int, train_fields))
|
||||||
|
|
||||||
|
return g, field_feat, triplets, true_relevance, train_fields
|
||||||
|
|
||||||
|
|
||||||
|
def train(args):
|
||||||
|
set_random_seed(args.seed)
|
||||||
|
device = get_device(args.device)
|
||||||
|
g, field_feat, triplets, true_relevance, train_fields = load_data(device)
|
||||||
|
add_node_feat(g, 'pretrained', args.node_embed_path)
|
||||||
|
|
||||||
|
sampler = MultiLayerNeighborSampler([args.neighbor_size] * args.num_layers)
|
||||||
|
triplet_loader = TripletNodeDataLoader(g, triplets, sampler, device, batch_size=args.batch_size)
|
||||||
|
node_loader = NodeDataLoader(g, {'author': g.nodes('author')}, sampler, device=device, batch_size=args.batch_size)
|
||||||
|
|
||||||
|
model = RHGNN(
|
||||||
|
{ntype: g.nodes[ntype].data['feat'].shape[1] for ntype in g.ntypes},
|
||||||
|
args.num_hidden, field_feat.shape[1], args.num_rel_hidden, args.num_rel_hidden,
|
||||||
|
args.num_heads, g.ntypes, g.canonical_etypes, 'author', args.num_layers, args.dropout
|
||||||
|
).to(device)
|
||||||
|
optimizer = optim.Adam(model.parameters(), lr=args.lr)
|
||||||
|
scheduler = optim.lr_scheduler.CosineAnnealingLR(
|
||||||
|
optimizer, T_max=len(triplet_loader) * args.epochs, eta_min=args.lr / 100
|
||||||
|
)
|
||||||
|
warnings.filterwarnings('ignore', 'Setting attributes on ParameterDict is not supported')
|
||||||
|
for epoch in range(args.epochs):
|
||||||
|
model.train()
|
||||||
|
losses = []
|
||||||
|
for batch, output_nodes, blocks in tqdm(triplet_loader):
|
||||||
|
batch_logits = model(blocks, blocks[0].srcdata['feat'])
|
||||||
|
aid_map = {a: i for i, a in enumerate(output_nodes.tolist())}
|
||||||
|
anchor = field_feat[batch[:, 0]]
|
||||||
|
positive = batch_logits[[aid_map[a] for a in batch[:, 1].tolist()]]
|
||||||
|
negative = batch_logits[[aid_map[a] for a in batch[:, 2].tolist()]]
|
||||||
|
loss = F.triplet_margin_loss(anchor, positive, negative)
|
||||||
|
losses.append(loss.item())
|
||||||
|
|
||||||
|
optimizer.zero_grad()
|
||||||
|
loss.backward()
|
||||||
|
optimizer.step()
|
||||||
|
scheduler.step()
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
print('Epoch {:d} | Loss {:.4f}'.format(epoch, sum(losses) / len(losses)))
|
||||||
|
torch.save(model.state_dict(), args.model_save_path)
|
||||||
|
if epoch % args.eval_every == 0 or epoch == args.epochs - 1:
|
||||||
|
print('nDCG@{}={:.4f}'.format(args.k, evaluate(
|
||||||
|
model, node_loader, g, field_feat.shape[1], 'author',
|
||||||
|
field_feat[train_fields], true_relevance, args.k
|
||||||
|
)))
|
||||||
|
torch.save(model.state_dict(), args.model_save_path)
|
||||||
|
print('模型已保存到', args.model_save_path)
|
||||||
|
|
||||||
|
author_embeds = infer(model, node_loader, g, field_feat.shape[1], 'author')
|
||||||
|
torch.save(author_embeds.cpu(), args.author_embed_save_path)
|
||||||
|
print('学者嵌入已保存到', args.author_embed_save_path)
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def evaluate(model, loader, g, out_dim, predict_ntype, field_feat, true_relevance, k):
|
||||||
|
embeds = infer(model, loader, g, out_dim, predict_ntype)
|
||||||
|
scores = torch.mm(field_feat, embeds.t()).detach().cpu().numpy()
|
||||||
|
return ndcg_score(true_relevance, scores, k=k, ignore_ties=True)
|
||||||
|
|
||||||
|
|
||||||
|
@torch.no_grad()
|
||||||
|
def infer(model, loader, g, out_dim, predict_ntype):
|
||||||
|
model.eval()
|
||||||
|
embeds = torch.zeros((g.num_nodes(predict_ntype), out_dim), device=g.device)
|
||||||
|
for _, output_nodes, blocks in tqdm(loader):
|
||||||
|
embeds[output_nodes[predict_ntype]] = model(blocks, blocks[0].srcdata['feat'])
|
||||||
|
return embeds
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
parser = argparse.ArgumentParser(description='GARec算法 训练GNN模型')
|
||||||
|
parser.add_argument('--seed', type=int, default=0, help='随机数种子')
|
||||||
|
parser.add_argument('--device', type=int, default=0, help='GPU设备')
|
||||||
|
# R-HGNN
|
||||||
|
parser.add_argument('--num-hidden', type=int, default=64, help='隐藏层维数')
|
||||||
|
parser.add_argument('--num-rel-hidden', type=int, default=8, help='关系表示的隐藏层维数')
|
||||||
|
parser.add_argument('--num-heads', type=int, default=8, help='注意力头数')
|
||||||
|
parser.add_argument('--num-layers', type=int, default=2, help='层数')
|
||||||
|
parser.add_argument('--dropout', type=float, default=0.5, help='Dropout概率')
|
||||||
|
parser.add_argument('--epochs', type=int, default=200, help='训练epoch数')
|
||||||
|
parser.add_argument('--batch-size', type=int, default=1024, help='批大小')
|
||||||
|
parser.add_argument('--neighbor-size', type=int, default=10, help='邻居采样数')
|
||||||
|
parser.add_argument('--lr', type=float, default=0.001, help='学习率')
|
||||||
|
parser.add_argument('--eval-every', type=int, default=10, help='每多少个epoch评价一次')
|
||||||
|
parser.add_argument('-k', type=int, default=20, help='评价指标只考虑top k的学者')
|
||||||
|
parser.add_argument('node_embed_path', help='预训练顶点嵌入路径')
|
||||||
|
parser.add_argument('model_save_path', help='模型保存路径')
|
||||||
|
parser.add_argument('author_embed_save_path', help='学者嵌入保存路径')
|
||||||
|
args = parser.parse_args()
|
||||||
|
print(args)
|
||||||
|
train(args)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,2 @@
|
||||||
|
from .data import *
|
||||||
|
from .metrics import *
|
||||||
|
|
@ -0,0 +1,64 @@
|
||||||
|
import json
|
||||||
|
|
||||||
|
import dgl
|
||||||
|
import torch
|
||||||
|
from dgl.dataloading import Collator
|
||||||
|
from dgl.utils import to_dgl_context
|
||||||
|
from torch.utils.data import DataLoader
|
||||||
|
|
||||||
|
|
||||||
|
def iter_json(filename):
|
||||||
|
"""遍历每行一个JSON格式的文件。"""
|
||||||
|
with open(filename, encoding='utf8') as f:
|
||||||
|
for line in f:
|
||||||
|
yield json.loads(line)
|
||||||
|
|
||||||
|
|
||||||
|
class TripletNodeCollator(Collator):
|
||||||
|
|
||||||
|
def __init__(self, g, triplets, block_sampler, ntype):
|
||||||
|
"""用于OAGCSAuthorRankDataset数据集的NodeCollator
|
||||||
|
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param triplets: tensor(N, 3) (t, ap, an)三元组
|
||||||
|
:param block_sampler: BlockSampler 邻居采样器
|
||||||
|
:param ntype: str 目标顶点类型
|
||||||
|
"""
|
||||||
|
self.g = g
|
||||||
|
self.triplets = triplets
|
||||||
|
self.block_sampler = block_sampler
|
||||||
|
self.ntype = ntype
|
||||||
|
|
||||||
|
def collate(self, items):
|
||||||
|
"""根据三元组中的学者id构造子图
|
||||||
|
|
||||||
|
:param items: List[tensor(3)] 一个批次的三元组
|
||||||
|
:return: tensor(N_src), tensor(N_dst), List[DGLBlock] (input_nodes, output_nodes, blocks)
|
||||||
|
"""
|
||||||
|
items = torch.stack(items, dim=0)
|
||||||
|
seed_nodes = items[:, 1:].flatten().unique()
|
||||||
|
blocks = self.block_sampler.sample_blocks(self.g, {self.ntype: seed_nodes})
|
||||||
|
output_nodes = blocks[-1].dstnodes[self.ntype].data[dgl.NID]
|
||||||
|
return items, output_nodes, blocks
|
||||||
|
|
||||||
|
@property
|
||||||
|
def dataset(self):
|
||||||
|
return self.triplets
|
||||||
|
|
||||||
|
|
||||||
|
class TripletNodeDataLoader(DataLoader):
|
||||||
|
|
||||||
|
def __init__(self, g, triplets, block_sampler, device=None, **kwargs):
|
||||||
|
"""用于OAGCSAuthorRankDataset数据集的NodeDataLoader
|
||||||
|
|
||||||
|
:param g: DGLGraph 异构图
|
||||||
|
:param triplets: tensor(N, 3) (t, ap, an)三元组
|
||||||
|
:param block_sampler: BlockSampler 邻居采样器
|
||||||
|
:param device: torch.device
|
||||||
|
:param kwargs: DataLoader的其他参数
|
||||||
|
"""
|
||||||
|
if device is None:
|
||||||
|
device = g.device
|
||||||
|
block_sampler.set_output_context(to_dgl_context(device))
|
||||||
|
self.collator = TripletNodeCollator(g, triplets, block_sampler, 'author')
|
||||||
|
super().__init__(triplets, collate_fn=self.collator.collate, **kwargs)
|
||||||
|
|
@ -0,0 +1,10 @@
|
||||||
|
def precision_at_k(y_true, y_pred, k):
|
||||||
|
y_true = set(y_true)
|
||||||
|
y_pred = set(y_pred[:k])
|
||||||
|
return len(set(y_true & y_pred)) / k
|
||||||
|
|
||||||
|
|
||||||
|
def recall_at_k(y_true, y_pred, k):
|
||||||
|
y_true = set(y_true)
|
||||||
|
y_pred = set(y_pred[:k])
|
||||||
|
return len(set(y_true & y_pred)) / len(y_true)
|
||||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 27 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 43 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 121 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 49 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 123 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 121 KiB |
|
|
@ -0,0 +1,22 @@
|
||||||
|
#!/usr/bin/env python
|
||||||
|
"""Django's command-line utility for administrative tasks."""
|
||||||
|
import os
|
||||||
|
import sys
|
||||||
|
|
||||||
|
|
||||||
|
def main():
|
||||||
|
"""Run administrative tasks."""
|
||||||
|
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'academic_graph.settings')
|
||||||
|
try:
|
||||||
|
from django.core.management import execute_from_command_line
|
||||||
|
except ImportError as exc:
|
||||||
|
raise ImportError(
|
||||||
|
"Couldn't import Django. Are you sure it's installed and "
|
||||||
|
"available on your PYTHONPATH environment variable? Did you "
|
||||||
|
"forget to activate a virtual environment?"
|
||||||
|
) from exc
|
||||||
|
execute_from_command_line(sys.argv)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
main()
|
||||||
|
|
@ -0,0 +1,244 @@
|
||||||
|
# 工作计划
|
||||||
|
## 总体计划
|
||||||
|
* [x] 2020.12~2021.3 继续阅读相关文献,考虑改进方法
|
||||||
|
* [x] 2021.3~2021.7 实现现有的异构图神经网络模型
|
||||||
|
* [x] 2021.7~2021.10 改进异构图神经网络模型,完成与现有方法的对比实验
|
||||||
|
* [ ] 2021.9~2021.10 构造学术网络数据集,实现基于图神经网络的推荐算法
|
||||||
|
* [x] 2021.10~2021.11 整理实验结果,实现可视化系统,撰写毕业论文初稿
|
||||||
|
* [ ] 2021.11~2021.12 准备毕业答辩
|
||||||
|
|
||||||
|
## 论文阅读
|
||||||
|
### 异构图表示学习
|
||||||
|
#### 综述
|
||||||
|
* [x] 2020 [Heterogeneous Network Representation Learning: A Unified Framework with Survey and Benchmark](https://arxiv.org/pdf/2004.00216)
|
||||||
|
* [x] 2020 [A Survey on Heterogeneous Graph Embedding: Methods, Techniques, Applications and Sources](https://arxiv.org/pdf/2011.14867)
|
||||||
|
#### 图神经网络
|
||||||
|
* [x] 2014 KDD [DeepWalk](https://arxiv.org/pdf/1403.6652)
|
||||||
|
* [x] 2016 KDD [node2vec](https://arxiv.org/pdf/1607.00653)
|
||||||
|
* [x] 2017 KDD [metapath2vec](https://ericdongyx.github.io/papers/KDD17-dong-chawla-swami-metapath2vec.pdf)
|
||||||
|
* [x] 2017 ICLR [GCN](https://arxiv.org/pdf/1609.02907)
|
||||||
|
* [x] 2018 ESWC [R-GCN](https://arxiv.org/pdf/1703.06103)
|
||||||
|
* [x] 2018 ICLR [GAT](https://arxiv.org/pdf/1710.10903)
|
||||||
|
* [x] 2019 KDD [HetGNN](https://dl.acm.org/doi/pdf/10.1145/3292500.3330961)
|
||||||
|
* [x] 2019 WWW [HAN](https://arxiv.org/pdf/1903.07293)
|
||||||
|
* [x] 2020 WWW [MAGNN](https://arxiv.org/pdf/2002.01680)
|
||||||
|
* [x] 2020 WWW [HGT](https://arxiv.org/pdf/2003.01332)
|
||||||
|
* [x] 2020 [HGConv](https://arxiv.org/pdf/2012.14722)
|
||||||
|
* [x] 2020 KDD [GPT-GNN](https://arxiv.org/pdf/2006.15437)
|
||||||
|
* [x] 2020 ICLR [GraphSAINT](https://openreview.net/pdf?id=BJe8pkHFwS)
|
||||||
|
* [x] 2020 [SIGN](https://arxiv.org/pdf/2004.11198)
|
||||||
|
* [x] 2020 [NARS](https://arxiv.org/pdf/2011.09679)
|
||||||
|
* [x] 2021 ICLR [SuperGAT](https://openreview.net/pdf?id=Wi5KUNlqWty)
|
||||||
|
* [x] 2021 [R-HGNN](https://arxiv.org/pdf/2105.11122)
|
||||||
|
#### 自监督/预训练
|
||||||
|
* [x] 2020 [Self-Supervised Graph Representation Learning via Global Context Prediction](https://arxiv.org/pdf/2003.01604)
|
||||||
|
* [ ] 2020 ICML [When Does Self-Supervision Help Graph Convolutional Networks?](http://proceedings.mlr.press/v119/you20a/you20a.pdf)
|
||||||
|
* [x] 2020 ICLR [Strategies for Pre-Training Graph Neural Networks](https://www.openreview.net/pdf?id=HJlWWJSFDH)
|
||||||
|
* [x] 2021 WWW [Self-Supervised Learning of Contextual Embeddings for Link Prediction in Heterogeneous Networks](https://arxiv.org/pdf/2007.11192)
|
||||||
|
* [x] 2021 KDD [HeCo](https://arxiv.org/pdf/2105.09111)
|
||||||
|
#### 其他
|
||||||
|
* [x] 2021 ICLR [C&S](https://arxiv.org/pdf/2010.13993)
|
||||||
|
|
||||||
|
### 基于图神经网络的推荐算法
|
||||||
|
#### 综述
|
||||||
|
* [x] 2020 IEEE [A Survey on Knowledge Graph-Based Recommender Systems](https://arxiv.org/pdf/2003.00911)
|
||||||
|
* [x] 2020 [Graph Neural Networks in Recommender Systems: A Survey](http://arxiv.org/pdf/2011.02260)
|
||||||
|
#### 基于嵌入的方法
|
||||||
|
* [x] 2016 KDD [CKE](https://www.kdd.org/kdd2016/papers/files/adf0066-zhangA.pdf)
|
||||||
|
* [x] 2018 [CFKG](https://arxiv.org/pdf/1803.06540)
|
||||||
|
* [ ] 2018 WSDM [SHINE](https://arxiv.org/pdf/1712.00732)
|
||||||
|
#### 基于路径的方法
|
||||||
|
* [x] 2013 IJCAI [Hete-MF](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.380.3668&rep=rep1&type=pdf)
|
||||||
|
* [x] 2014 ICDM [Hete-CF](https://arxiv.org/pdf/1412.7610)
|
||||||
|
* [x] 2013 RecSys [HeteRec](http://hanj.cs.illinois.edu/pdf/recsys13_xyu.pdf)
|
||||||
|
* [ ] 2015 CIKM [SemRec](https://papers-gamma.link/static/memory/pdfs/152-Shi_Semantic_Path_Based_Personalized_Recommendation_on_Weighted_HIN_2015.pdf)
|
||||||
|
* [ ] 2019 WWW [RuleRec](https://arxiv.org/pdf/1903.03714)
|
||||||
|
* [ ] 2018 KDD [MCRec](https://dl.acm.org/doi/pdf/10.1145/3219819.3219965)
|
||||||
|
* [ ] 2018 RecSys [RKGE](https://repository.tudelft.nl/islandora/object/uuid:9a3559e9-27b6-47cd-820d-d7ecc76cbc06/datastream/OBJ/download)
|
||||||
|
#### 嵌入和路径结合的方法
|
||||||
|
* [x] 2018 CIKM [RippleNet](https://arxiv.org/pdf/1803.03467)
|
||||||
|
* [ ] 2019 KDD [AKUPM](https://dl.acm.org/doi/abs/10.1145/3292500.3330705)
|
||||||
|
* [x] 2019 WWW [KGCN](https://arxiv.org/pdf/1904.12575)
|
||||||
|
* [x] 2019 KDD [KGAT](https://arxiv.org/pdf/1905.07854)
|
||||||
|
* [ ] 2019 [KNI](https://arxiv.org/pdf/1908.04032)
|
||||||
|
|
||||||
|
## 复现模型
|
||||||
|
### 异构图表示学习
|
||||||
|
* [x] [GCN](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/gcn)
|
||||||
|
* [x] [R-GCN](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/rgcn)
|
||||||
|
* [x] [GAT](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/gat)
|
||||||
|
* [x] [HetGNN](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/hetgnn)
|
||||||
|
* [x] [HAN](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/han)
|
||||||
|
* [x] [MAGNN](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/magnn)
|
||||||
|
* [x] [HGT](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/hgt)
|
||||||
|
* [x] [metapath2vec](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/metapath2vec)
|
||||||
|
* [x] [SIGN](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/sign)
|
||||||
|
* [x] [HGConv](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/hgconv)
|
||||||
|
* [x] [SuperGAT](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/supergat)
|
||||||
|
* [x] [R-HGNN](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/rhgnn)
|
||||||
|
* [x] [C&S](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/cs)
|
||||||
|
* [x] [HeCo](https://github.com/ZZy979/pytorch-tutorial/tree/master/gnn/heco)
|
||||||
|
|
||||||
|
### 基于图神经网络的推荐算法
|
||||||
|
* [ ] CKE
|
||||||
|
* [ ] RippleNet
|
||||||
|
* [ ] KGCN
|
||||||
|
* [ ] KGAT
|
||||||
|
|
||||||
|
## 具体计划
|
||||||
|
* 2020.12.21~12.25
|
||||||
|
* [x] 阅读论文CKE
|
||||||
|
* [x] 实现GCN
|
||||||
|
* [x] 阅读论文R-GCN
|
||||||
|
* 2020.12.28~2021.1.1
|
||||||
|
* [x] 实现R-GCN
|
||||||
|
* [x] 阅读论文RippleNet
|
||||||
|
* [x] 阅读论文Hete-MF
|
||||||
|
* 2021.1.4~1.8
|
||||||
|
* [x] 实现GAT
|
||||||
|
* [x] 实现HAN
|
||||||
|
* [x] 阅读论文Hete-CF
|
||||||
|
* [x] 阅读论文CFKG
|
||||||
|
* 2021.1.11~1.15
|
||||||
|
* [x] 实现MAGNN
|
||||||
|
* [x] 阅读论文KGCN
|
||||||
|
* [x] 阅读论文HeteRec
|
||||||
|
* 2021.1.18~1.22
|
||||||
|
* [x] 阅读论文KGAT
|
||||||
|
* [x] 使用OGB数据集做实验
|
||||||
|
* 2021.2.22~2.26
|
||||||
|
* [x] 实现ogbn-mag数据集baseline: MLP和Full-batch GCN
|
||||||
|
* [x] 查找最新异构图表示学习论文
|
||||||
|
* 2021.3.1~3.5
|
||||||
|
* [x] 实现ogbn-mag数据集 R-GCN模型
|
||||||
|
* [x] 阅读论文HGConv
|
||||||
|
* 2021.3.8~3.12
|
||||||
|
* [x] 实现ogbn-mag数据集 HGConv模型
|
||||||
|
* [x] 尝试解决ogbn-mag数据集 HAN模型内存占用过大的问题
|
||||||
|
* [x] 阅读论文NARS
|
||||||
|
* 2021.3.15~3.19
|
||||||
|
* [x] 阅读论文SIGN
|
||||||
|
* [x] 阅读论文GraphSAINT
|
||||||
|
* [x] 阅读论文SuperGAT
|
||||||
|
* 2021.3.22~3.26
|
||||||
|
* 继续看上周的论文(找实习面试好难啊😢)
|
||||||
|
* 2021.4.1 人生中第一个offer🎉
|
||||||
|
* 2021.4.5~4.9
|
||||||
|
* [x] 重新训练ogbn-mag数据集 HGConv模型
|
||||||
|
* [x] 实现SuperGAT
|
||||||
|
* 2021.4.12~4.18
|
||||||
|
* [x] 阅读论文GPT-GNN
|
||||||
|
* [x] 实现metapath2vec
|
||||||
|
* 2021.4.19~4.25
|
||||||
|
* [x] 使用子图采样的方法在ogbn-mag数据集上训练HAN模型
|
||||||
|
* [x] 使用metapath2vec预训练ogbn-mag数据集的顶点特征,重新跑HGConv模型
|
||||||
|
* [x] 阅读综述A Survey on Heterogeneous Graph Embedding
|
||||||
|
* 2021.4.26~5.9
|
||||||
|
* [x] 实现HGT
|
||||||
|
* [x] 实现HetGNN
|
||||||
|
* [x] 实现ogbn-mag数据集 HGT模型
|
||||||
|
* [x] 实现ogbn-mag数据集 HetGNN模型
|
||||||
|
* [x] 尝试改进:HetGNN的内容聚集+HGConv
|
||||||
|
* 2021.5.10~5.16
|
||||||
|
* [x] 阅读论文Strategies for Pre-Training Graph Neural Networks
|
||||||
|
* [x] 阅读论文Self-Supervised Graph Representation Learning via Global Context Prediction
|
||||||
|
* 2021.5.17~5.23
|
||||||
|
* [x] 继续尝试异构图表示学习模型的改进
|
||||||
|
* [x] 阅读论文Self-Supervised Learning of Contextual Embeddings for Link Prediction in Heterogeneous Networks
|
||||||
|
* [x] 整理OAG数据集
|
||||||
|
* 2021.5.24~5.30
|
||||||
|
* 实习第一周
|
||||||
|
* [x] 阅读论文R-HGNN
|
||||||
|
* 2021.5.31~6.6
|
||||||
|
* [x] 实现R-HGNN
|
||||||
|
* 2021.6.7~6.13
|
||||||
|
* [x] 利用OAG数据集构造计算机领域的子集
|
||||||
|
* 2021.6.14~6.20
|
||||||
|
* [x] 阅读论文C&S
|
||||||
|
* [x] 完成SciBERT模型的fine-tune,获取OAG-CS数据集的paper顶点输入特征
|
||||||
|
* 2021.7.5~7.18
|
||||||
|
* [x] 实现C&S
|
||||||
|
* [x] 阅读论文HeCo
|
||||||
|
* 2021.7.19~7.25
|
||||||
|
* [x] 实现HeCo
|
||||||
|
* 2021.7.26~8.1
|
||||||
|
* [x] 尝试改进HeCo:mini-batch训练、元路径编码器改为其他方式、Loss增加分类损失
|
||||||
|
* 7.29 和吴嘉伟讨论HeCo的改进思路
|
||||||
|
* 正样本选择策略:在下游任务上预训练一个两层HGT,第二层的注意力权重是一阶邻居对目标顶点的权重,
|
||||||
|
第一层的注意力权重是二阶邻居对一阶邻居的权重,取类型与目标顶点相同的二阶邻居,并将两个权重相加,
|
||||||
|
得到二阶邻居(同类型)对目标顶点的权重,取top-k作为目标顶点的正样本
|
||||||
|
* 使用上面得到的正样本可以构造一个目标类型顶点的同构图,用于替换元路径编码器中基于元路径的同构图
|
||||||
|
* [x] 确认HGT中对注意力权重做softmax的方式(同类型/跨类型)→同类型
|
||||||
|
* 2021.8.2~8.8
|
||||||
|
* [x] 实现使用预训练的HGT计算的注意力权重选择HeCo的正样本的方法
|
||||||
|
* [x] 将HeCo迁移到ogbn-mag数据集上,尝试效果 → 24.67%
|
||||||
|
* [x] 元路径视图编码器替换为正样本图上的GCN编码器
|
||||||
|
* [x] 适配mini-batch训练
|
||||||
|
* 2021.8.9~8.15
|
||||||
|
* [x] 将HeCo训练方式改为半监督(loss增加分类损失),尝试效果 → 26.32%
|
||||||
|
* [x] 尝试C&S Baseline在ogbn-mag数据集上的效果 → 不加Correct步骤能提升更多,正样本图>引用图
|
||||||
|
* [x] 尝试增加C&S后处理步骤(重点是标签传播图的构造)
|
||||||
|
* [x] R-HGNN+C&S → 正样本图上微提升,引用图上下降
|
||||||
|
* [x] HeCo+C&S → 26.32% -> 27.7%
|
||||||
|
* 2021.8.16~8.22
|
||||||
|
* [x] 尝试HeCo的最终嵌入使用z_sc → 提升10%!
|
||||||
|
* [x] 尝试将HeCo的网络结构编码器替换为R-HGNN
|
||||||
|
* 2021.8.23~8.29
|
||||||
|
* [x] 写中期报告
|
||||||
|
* 2021.8.30~9.5
|
||||||
|
* [x] 尝试将RHCO的网络结构编码器改为两层 → 提升4.4%
|
||||||
|
* [x] 尝试其他构造正样本图的方法:训练集使用真实标签,验证集和测试集使用HGT预测 → 提升0.6%
|
||||||
|
* 2021.9.6~9.12
|
||||||
|
* [x] 尝试将构造正样本图的方法改为使用预训练的R-HGNN模型计算的注意力权重、训练集使用真实标签 → 下降2.6%
|
||||||
|
* [x] 使用metapath2vec预训练oag-cs数据集的顶点嵌入,备用
|
||||||
|
* 2021.9.13~9.19
|
||||||
|
* [x] RHCO模型删除输入特征转换和dropout(网络结构编码器已包含)、增加学习率调度器(对比损失权重为0时应该达到与R-HGNN相似的性能) → +10%
|
||||||
|
* [x] 设计推荐算法:使用SciBERT+对比学习实现召回:一篇论文的标题和关键词是一对正样本,使用(一个或两个)SciBERT分别将标题和关键词编码为向量,
|
||||||
|
计算对比损失,以此方式进行微调;使用微调后的SciBERT模型将论文标题和输入关键词编码为向量,计算相似度即可召回与查询最相关的论文
|
||||||
|
* 2021.9.20~9.26
|
||||||
|
* [x] 在oag-cs数据集上使用SciBERT+对比学习进行微调
|
||||||
|
* [x] 实现输入关键词召回论文的功能
|
||||||
|
* 2021.9.27~10.10
|
||||||
|
* [x] 实现推荐算法的精排部分
|
||||||
|
* [x] 重新构造oag-cs数据集,使field顶点包含所有领域词
|
||||||
|
* [x] 在oag-cs数据集上训练RHCO模型(预测任务:期刊分类),获取顶点表示向量
|
||||||
|
* [x] 修改训练代码,使其能够适配不同的数据集
|
||||||
|
* TODO 预测任务改为学者排名相关(例如学者和领域顶点的相似度),需要先获取ground truth:学者在某个领域的论文引用数之和,排序
|
||||||
|
* [x] 初步实现可视化系统
|
||||||
|
* [x] 创建Django项目(直接使用当前根目录即可)
|
||||||
|
* [x] 创建数据库,将oag-cs数据导入数据库
|
||||||
|
* [x] 实现论文召回的可视化
|
||||||
|
* 2021.10.11~10.17
|
||||||
|
* 精排部分GNN模型训练思路:
|
||||||
|
* (1)对于领域t召回论文,得到论文关联的学者集合,通过论文引用数之和构造学者排名;
|
||||||
|
* (2)从排名中采样N个三元组(t, ap, an),其中学者ap的排名在an之前,采样应包含简单样本(例如第1名和第10名)和困难样本(例如第1名和第3名);
|
||||||
|
* (3)计算三元组损失triplet_loss(t, ap, an) = d(t, ap) - d(t, an) + α
|
||||||
|
* [x] 可视化系统:实现查看论文详情、学者详情等基本功能
|
||||||
|
* [x] 开始写毕业论文
|
||||||
|
* [x] 第一章 绪论
|
||||||
|
* 2021.10.18~10.24
|
||||||
|
* [x] 异构图表示学习:增加ACM和DBLP数据集
|
||||||
|
* [x] 写毕业论文
|
||||||
|
* [x] 第二章 基础理论
|
||||||
|
* [x] 第三章 基于对比学习的异构图表示学习模型
|
||||||
|
* 2021.10.25~10.31
|
||||||
|
* [x] 完成毕业论文初稿
|
||||||
|
* [x] 第四章 基于图神经网络的学术推荐算法
|
||||||
|
* [x] 第五章 学术推荐系统设计与实现
|
||||||
|
* [x] 异构图表示学习
|
||||||
|
* [x] 正样本图改为类型的邻居各对应一个(PAP, PFP),使用注意力组合
|
||||||
|
* [x] 尝试:网络结构编码器由R-HGNN改为HGConv → ACM: -3.6%, DBLP: +4%, ogbn-mag: -1.86%
|
||||||
|
* 2021.11.1~11.7
|
||||||
|
* [x] 异构图表示学习
|
||||||
|
* [x] 完成参数敏感性分析
|
||||||
|
* [x] 推荐算法精排部分
|
||||||
|
* [x] 抓取AMiner AI 2000的人工智能学者榜单作为学者排名验证集
|
||||||
|
* [x] 参考AI 2000的计算公式,使用某个领域的论文引用数加权求和构造学者排名ground truth训练集,采样三元组
|
||||||
|
* [x] 训练:使用三元组损失训练GNN模型
|
||||||
|
* 2021.11.8~11.14
|
||||||
|
* [ ] 异构图表示学习
|
||||||
|
* [x] 增加oag-cs期刊分类数据集
|
||||||
|
* [ ] 完成消融实验
|
||||||
|
* [ ] 推荐算法精排部分
|
||||||
|
* [ ] 训练:目前的评价方式有问题,改为先召回论文再计算相关学者与领域的相似度(即与预测步骤相同)
|
||||||
|
* [ ] 预测:对于召回的论文构造子图,利用顶点嵌入计算查询词与学者的相似度,实现学者排名
|
||||||
|
|
@ -0,0 +1,18 @@
|
||||||
|
from django.contrib import admin
|
||||||
|
|
||||||
|
from .models import Author, Paper, Venue, Institution, Field
|
||||||
|
|
||||||
|
|
||||||
|
class AuthorAdmin(admin.ModelAdmin):
|
||||||
|
raw_id_fields = ['institution']
|
||||||
|
|
||||||
|
|
||||||
|
class PaperAdmin(admin.ModelAdmin):
|
||||||
|
raw_id_fields = ['authors', 'venue', 'fos', 'references']
|
||||||
|
|
||||||
|
|
||||||
|
admin.site.register(Author, AuthorAdmin)
|
||||||
|
admin.site.register(Paper, PaperAdmin)
|
||||||
|
admin.site.register(Venue)
|
||||||
|
admin.site.register(Institution)
|
||||||
|
admin.site.register(Field)
|
||||||
|
|
@ -0,0 +1,15 @@
|
||||||
|
from django.apps import AppConfig
|
||||||
|
from django.conf import settings
|
||||||
|
|
||||||
|
from gnnrec.kgrec import recall, rank
|
||||||
|
|
||||||
|
|
||||||
|
class RankConfig(AppConfig):
|
||||||
|
default_auto_field = 'django.db.models.BigAutoField'
|
||||||
|
name = 'rank'
|
||||||
|
|
||||||
|
def ready(self):
|
||||||
|
if not settings.TESTING:
|
||||||
|
from . import views
|
||||||
|
views.recall_ctx = recall.get_context()
|
||||||
|
views.rank_ctx = rank.get_context(views.recall_ctx)
|
||||||
|
|
@ -0,0 +1,95 @@
|
||||||
|
import dgl
|
||||||
|
import dgl.function as fn
|
||||||
|
from django.core.management import BaseCommand
|
||||||
|
from tqdm import trange
|
||||||
|
|
||||||
|
from gnnrec.config import DATA_DIR
|
||||||
|
from gnnrec.kgrec.data import OAGCSDataset
|
||||||
|
from gnnrec.kgrec.utils import iter_json
|
||||||
|
from rank.models import Venue, Institution, Field, Author, Paper, Writes
|
||||||
|
|
||||||
|
|
||||||
|
class Command(BaseCommand):
|
||||||
|
help = '将oag-cs数据集导入数据库'
|
||||||
|
|
||||||
|
def add_arguments(self, parser):
|
||||||
|
parser.add_argument('--batch-size', type=int, default=2000, help='批大小')
|
||||||
|
|
||||||
|
def handle(self, *args, **options):
|
||||||
|
batch_size = options['batch_size']
|
||||||
|
raw_path = DATA_DIR / 'oag/cs'
|
||||||
|
|
||||||
|
print('正在导入期刊数据...')
|
||||||
|
Venue.objects.bulk_create([
|
||||||
|
Venue(id=i, name=v['name'])
|
||||||
|
for i, v in enumerate(iter_json(raw_path / 'mag_venues.txt'))
|
||||||
|
], batch_size=batch_size)
|
||||||
|
vid_map = {v['id']: i for i, v in enumerate(iter_json(raw_path / 'mag_venues.txt'))}
|
||||||
|
|
||||||
|
print('正在导入机构数据...')
|
||||||
|
Institution.objects.bulk_create([
|
||||||
|
Institution(id=i, name=o['name'])
|
||||||
|
for i, o in enumerate(iter_json(raw_path / 'mag_institutions.txt'))
|
||||||
|
], batch_size=batch_size)
|
||||||
|
oid_map = {o['id']: i for i, o in enumerate(iter_json(raw_path / 'mag_institutions.txt'))}
|
||||||
|
|
||||||
|
print('正在导入领域数据...')
|
||||||
|
Field.objects.bulk_create([
|
||||||
|
Field(id=i, name=f['name'])
|
||||||
|
for i, f in enumerate(iter_json(raw_path / 'mag_fields.txt'))
|
||||||
|
], batch_size=batch_size)
|
||||||
|
|
||||||
|
data = OAGCSDataset()
|
||||||
|
g = data[0]
|
||||||
|
apg = dgl.reverse(g['author', 'writes', 'paper'], copy_ndata=False)
|
||||||
|
apg.nodes['paper'].data['c'] = g.nodes['paper'].data['citation'].float()
|
||||||
|
apg.update_all(fn.copy_u('c', 'm'), fn.sum('m', 'c'))
|
||||||
|
author_citation = apg.nodes['author'].data['c'].int().tolist()
|
||||||
|
|
||||||
|
print('正在导入学者数据...')
|
||||||
|
Author.objects.bulk_create([
|
||||||
|
Author(
|
||||||
|
id=i, name=a['name'], n_citation=author_citation[i],
|
||||||
|
institution_id=oid_map[a['org']] if a['org'] is not None else None
|
||||||
|
) for i, a in enumerate(iter_json(raw_path / 'mag_authors.txt'))
|
||||||
|
], batch_size=batch_size)
|
||||||
|
|
||||||
|
print('正在导入论文数据...')
|
||||||
|
Paper.objects.bulk_create([
|
||||||
|
Paper(
|
||||||
|
id=i, title=p['title'], venue_id=vid_map[p['venue']], year=p['year'],
|
||||||
|
abstract=p['abstract'], n_citation=p['n_citation']
|
||||||
|
) for i, p in enumerate(iter_json(raw_path / 'mag_papers.txt'))
|
||||||
|
], batch_size=batch_size)
|
||||||
|
|
||||||
|
print('正在导入论文关联数据(很慢)...')
|
||||||
|
print('writes')
|
||||||
|
u, v = g.edges(etype='writes')
|
||||||
|
order = g.edges['writes'].data['order']
|
||||||
|
edges = list(zip(u.tolist(), v.tolist(), order.tolist()))
|
||||||
|
for i in trange(0, len(edges), batch_size):
|
||||||
|
Writes.objects.bulk_create([
|
||||||
|
Writes(author_id=a, paper_id=p, order=r)
|
||||||
|
for a, p, r in edges[i:i + batch_size]
|
||||||
|
])
|
||||||
|
|
||||||
|
print('has_field')
|
||||||
|
u, v = g.edges(etype='has_field')
|
||||||
|
edges = list(zip(u.tolist(), v.tolist()))
|
||||||
|
HasField = Paper.fos.through
|
||||||
|
for i in trange(0, len(edges), batch_size):
|
||||||
|
HasField.objects.bulk_create([
|
||||||
|
HasField(paper_id=p, field_id=f)
|
||||||
|
for p, f in edges[i:i + batch_size]
|
||||||
|
])
|
||||||
|
|
||||||
|
print('cites')
|
||||||
|
u, v = g.edges(etype='cites')
|
||||||
|
edges = list(zip(u.tolist(), v.tolist()))
|
||||||
|
Cites = Paper.references.through
|
||||||
|
for i in trange(0, len(edges), batch_size):
|
||||||
|
Cites.objects.bulk_create([
|
||||||
|
Cites(from_paper_id=p, to_paper_id=r)
|
||||||
|
for p, r in edges[i:i + batch_size]
|
||||||
|
])
|
||||||
|
print('导入完成')
|
||||||
|
|
@ -0,0 +1,92 @@
|
||||||
|
# Generated by Django 3.2.8 on 2021-11-03 13:45
|
||||||
|
|
||||||
|
from django.db import migrations, models
|
||||||
|
import django.db.models.deletion
|
||||||
|
|
||||||
|
|
||||||
|
class Migration(migrations.Migration):
|
||||||
|
|
||||||
|
initial = True
|
||||||
|
|
||||||
|
dependencies = [
|
||||||
|
]
|
||||||
|
|
||||||
|
operations = [
|
||||||
|
migrations.CreateModel(
|
||||||
|
name='Author',
|
||||||
|
fields=[
|
||||||
|
('id', models.BigIntegerField(primary_key=True, serialize=False)),
|
||||||
|
('name', models.CharField(db_index=True, max_length=255)),
|
||||||
|
('n_citation', models.IntegerField(default=0)),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
migrations.CreateModel(
|
||||||
|
name='Field',
|
||||||
|
fields=[
|
||||||
|
('id', models.BigIntegerField(primary_key=True, serialize=False)),
|
||||||
|
('name', models.CharField(max_length=255, unique=True)),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
migrations.CreateModel(
|
||||||
|
name='Institution',
|
||||||
|
fields=[
|
||||||
|
('id', models.BigIntegerField(primary_key=True, serialize=False)),
|
||||||
|
('name', models.CharField(db_index=True, max_length=255)),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
migrations.CreateModel(
|
||||||
|
name='Paper',
|
||||||
|
fields=[
|
||||||
|
('id', models.BigIntegerField(primary_key=True, serialize=False)),
|
||||||
|
('title', models.CharField(db_index=True, max_length=255)),
|
||||||
|
('year', models.IntegerField()),
|
||||||
|
('abstract', models.CharField(max_length=4095)),
|
||||||
|
('n_citation', models.IntegerField(default=0)),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
migrations.CreateModel(
|
||||||
|
name='Venue',
|
||||||
|
fields=[
|
||||||
|
('id', models.BigIntegerField(primary_key=True, serialize=False)),
|
||||||
|
('name', models.CharField(db_index=True, max_length=255)),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
migrations.CreateModel(
|
||||||
|
name='Writes',
|
||||||
|
fields=[
|
||||||
|
('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),
|
||||||
|
('order', models.IntegerField(default=1)),
|
||||||
|
('author', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rank.author')),
|
||||||
|
('paper', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='rank.paper')),
|
||||||
|
],
|
||||||
|
),
|
||||||
|
migrations.AddField(
|
||||||
|
model_name='paper',
|
||||||
|
name='authors',
|
||||||
|
field=models.ManyToManyField(related_name='papers', through='rank.Writes', to='rank.Author'),
|
||||||
|
),
|
||||||
|
migrations.AddField(
|
||||||
|
model_name='paper',
|
||||||
|
name='fos',
|
||||||
|
field=models.ManyToManyField(to='rank.Field'),
|
||||||
|
),
|
||||||
|
migrations.AddField(
|
||||||
|
model_name='paper',
|
||||||
|
name='references',
|
||||||
|
field=models.ManyToManyField(related_name='citations', to='rank.Paper'),
|
||||||
|
),
|
||||||
|
migrations.AddField(
|
||||||
|
model_name='paper',
|
||||||
|
name='venue',
|
||||||
|
field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='rank.venue'),
|
||||||
|
),
|
||||||
|
migrations.AddField(
|
||||||
|
model_name='author',
|
||||||
|
name='institution',
|
||||||
|
field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='rank.institution'),
|
||||||
|
),
|
||||||
|
migrations.AddConstraint(
|
||||||
|
model_name='writes',
|
||||||
|
constraint=models.UniqueConstraint(fields=('author', 'paper'), name='unique_writes'),
|
||||||
|
),
|
||||||
|
]
|
||||||
|
|
@ -0,0 +1,17 @@
|
||||||
|
# Generated by Django 3.2.8 on 2021-11-04 04:15
|
||||||
|
|
||||||
|
from django.db import migrations
|
||||||
|
|
||||||
|
|
||||||
|
class Migration(migrations.Migration):
|
||||||
|
|
||||||
|
dependencies = [
|
||||||
|
('rank', '0001_initial'),
|
||||||
|
]
|
||||||
|
|
||||||
|
operations = [
|
||||||
|
migrations.AlterModelOptions(
|
||||||
|
name='writes',
|
||||||
|
options={'ordering': ['paper_id', 'order']},
|
||||||
|
),
|
||||||
|
]
|
||||||
|
|
@ -0,0 +1,63 @@
|
||||||
|
from django.db import models
|
||||||
|
|
||||||
|
|
||||||
|
class Venue(models.Model):
|
||||||
|
id = models.BigIntegerField(primary_key=True)
|
||||||
|
name = models.CharField(max_length=255, db_index=True)
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return self.name
|
||||||
|
|
||||||
|
|
||||||
|
class Institution(models.Model):
|
||||||
|
id = models.BigIntegerField(primary_key=True)
|
||||||
|
name = models.CharField(max_length=255, db_index=True)
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return self.name
|
||||||
|
|
||||||
|
|
||||||
|
class Field(models.Model):
|
||||||
|
id = models.BigIntegerField(primary_key=True)
|
||||||
|
name = models.CharField(max_length=255, unique=True)
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return self.name
|
||||||
|
|
||||||
|
|
||||||
|
class Author(models.Model):
|
||||||
|
id = models.BigIntegerField(primary_key=True)
|
||||||
|
name = models.CharField(max_length=255, db_index=True)
|
||||||
|
institution = models.ForeignKey(Institution, on_delete=models.SET_NULL, null=True)
|
||||||
|
n_citation = models.IntegerField(default=0)
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return self.name
|
||||||
|
|
||||||
|
|
||||||
|
class Paper(models.Model):
|
||||||
|
id = models.BigIntegerField(primary_key=True)
|
||||||
|
title = models.CharField(max_length=255, db_index=True)
|
||||||
|
authors = models.ManyToManyField(Author, related_name='papers', through='Writes')
|
||||||
|
venue = models.ForeignKey(Venue, on_delete=models.SET_NULL, null=True)
|
||||||
|
year = models.IntegerField()
|
||||||
|
abstract = models.CharField(max_length=4095)
|
||||||
|
fos = models.ManyToManyField(Field)
|
||||||
|
references = models.ManyToManyField('self', related_name='citations', symmetrical=False)
|
||||||
|
n_citation = models.IntegerField(default=0)
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return self.title
|
||||||
|
|
||||||
|
|
||||||
|
class Writes(models.Model):
|
||||||
|
author = models.ForeignKey(Author, on_delete=models.CASCADE)
|
||||||
|
paper = models.ForeignKey(Paper, on_delete=models.CASCADE)
|
||||||
|
order = models.IntegerField(default=1)
|
||||||
|
|
||||||
|
class Meta:
|
||||||
|
constraints = [models.UniqueConstraint(fields=['author', 'paper'], name='unique_writes')]
|
||||||
|
ordering = ['paper_id', 'order']
|
||||||
|
|
||||||
|
def __str__(self):
|
||||||
|
return f'(author_id={self.author_id}, paper_id={self.paper_id}, order={self.order})'
|
||||||
|
|
@ -0,0 +1,13 @@
|
||||||
|
{% for author in object_list %}
|
||||||
|
<div class="card my-2">
|
||||||
|
<div class="card-body">
|
||||||
|
<div class="row">
|
||||||
|
<h5 class="card-title col">
|
||||||
|
<a href="{% url 'rank:author-detail' author.id %}">{{ author.name }}</a>
|
||||||
|
</h5>
|
||||||
|
<small class="text-right col-3 col-lg-2">{{ author.n_citation }} citations</small>
|
||||||
|
</div>
|
||||||
|
<h6 class="card-subtitle text-muted mb-2">{{ author.institution }}</h6>
|
||||||
|
</div>
|
||||||
|
</div>
|
||||||
|
{% endfor %}
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue