initial commit
This commit is contained in:
parent
dd09f76207
commit
b1c9f1593e
151
README.md
151
README.md
|
|
@ -1,3 +1,152 @@
|
|||
# erYa
|
||||
|
||||
超星尔雅爬虫,通过courseId,爬取完整的题目。 - python实践
|
||||
#### 前言
|
||||
啦啦啦,经过3天的python学习,是时候实践一番了,将以前写的爬尔雅题库的`易语言`转成python代码,算是完全重写。
|
||||
> 通过尔雅课程的courseId,获取科目课程的所有题目。(不含答案,不含sql,纯原生爬取,输出代码)
|
||||
|
||||
![运行截图]](https://i.loli.net/2018/08/15/5b7403d689e17.png)
|
||||
|
||||
|
||||
#### 爬取步骤:
|
||||
> [尔雅课程地址:http://erya.mooc.chaoxing.com/courses](http://erya.mooc.chaoxing.com/courses)
|
||||
|
||||
##### 关键参数:
|
||||
|
||||
* courseId 课程的id
|
||||
* knowledgeId = data("xxx") 课程每一节的id,knowledgeId在域名链接中,data为跳转到其他小节的课程
|
||||
* workId 小节题目的id
|
||||
|
||||
1. 随便进入一门课程,课程链接组成为:https://mooc1.chaoxing.com/course/200837021.html
|
||||
|
||||
> https://mooc1.chaoxing.com/course/coursesId(课程ID).html
|
||||
|
||||
2. 由于要进入到类似 https://mooc1.chaoxing.com/nodedetailcontroller/visitnodedetail?courseId=200080607&knowledgeId=102433017 的一个页面,需要knowledgeId,第一次的这个id只能由第一步的地址的代码中拿,不然无法进入类似这一步的地址
|
||||
|
||||
> 在第一步地址中,先获取knowledgeId进入第二步,才算是正式开始抓取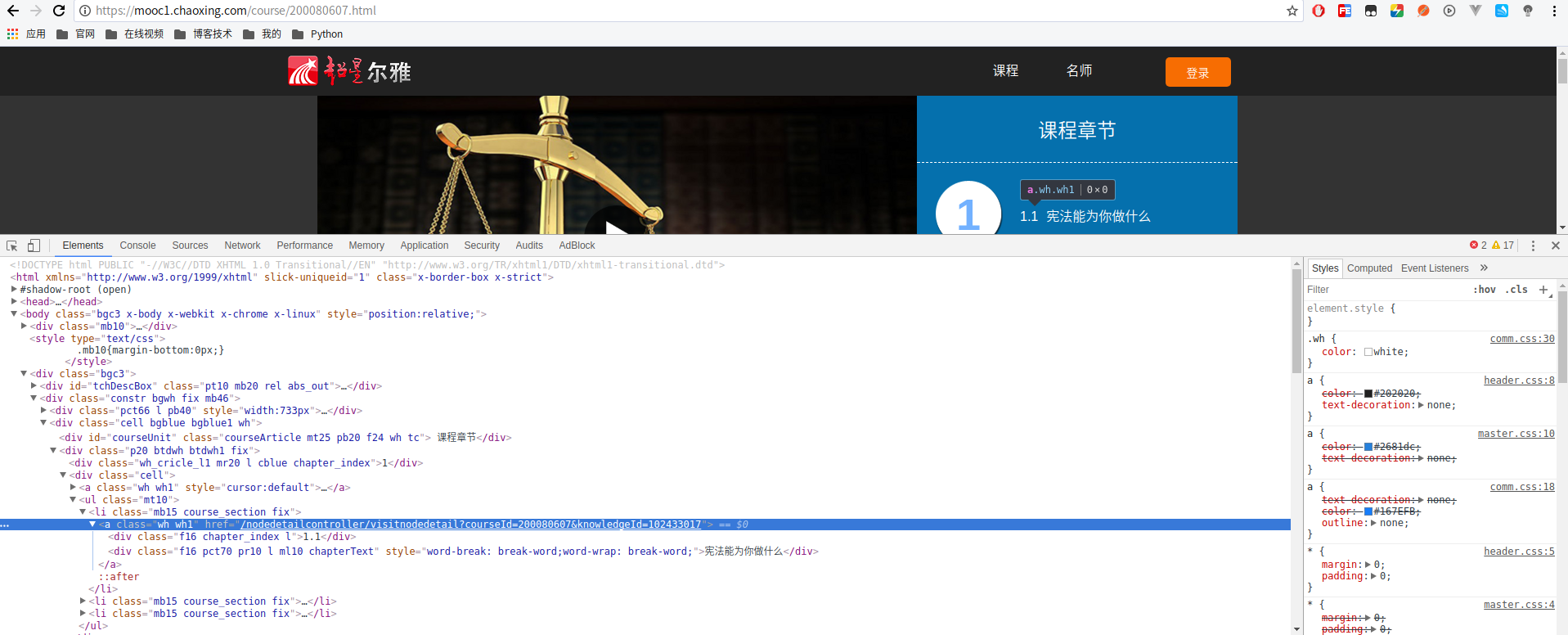
|
||||
|
||||
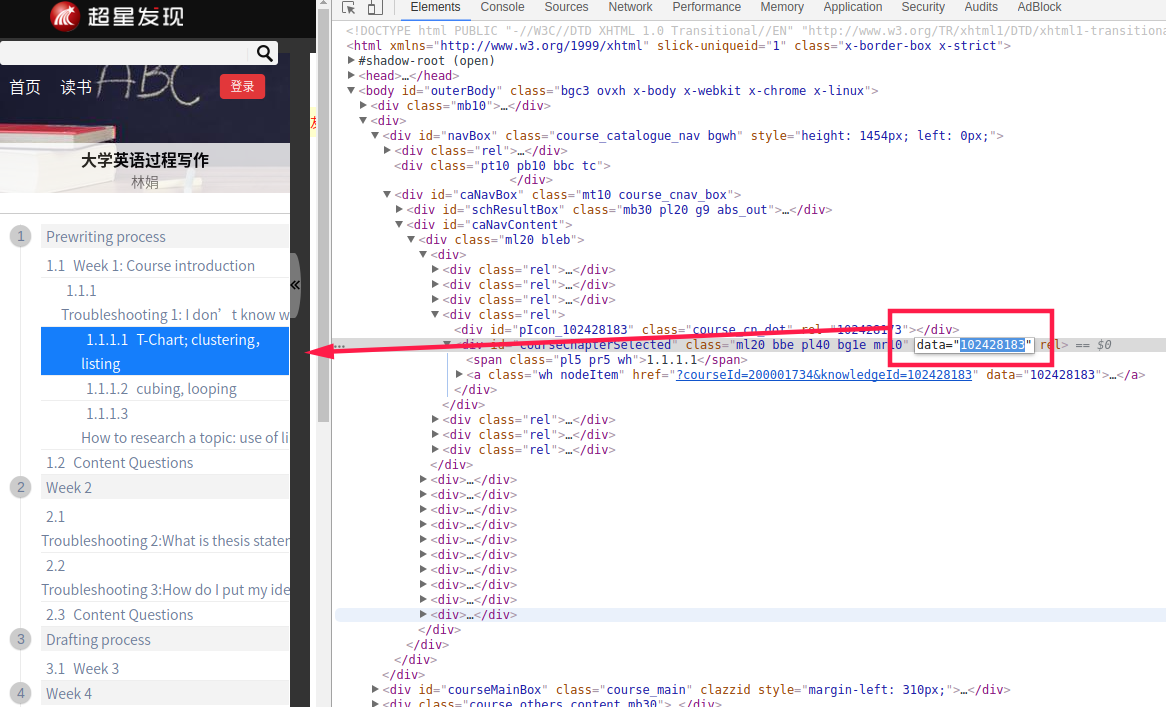
3. 进入之后目录结构部分课程比较复杂,所以爬虫遍历的方法算是很独特的。
|
||||
|
||||
|
||||
> 在网站源代码中有data=“xxx” xxx就是knowledgeId,由于部分课程可能不展开,所以id不全,爬取方法,每一次爬取之后,获取当前爬的id的下一个id,进入下一节,保证不丢小节课程
|
||||
|
||||
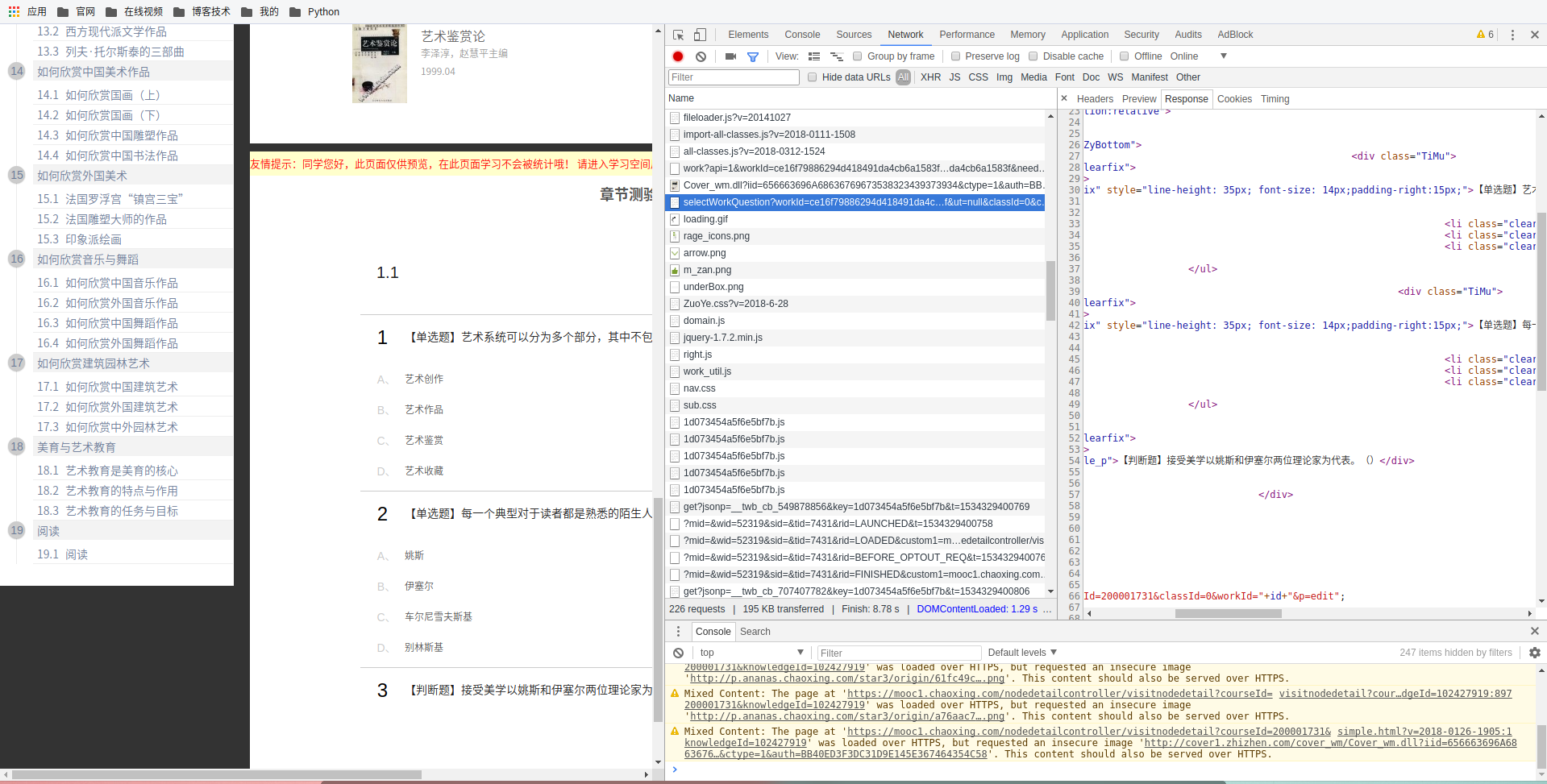
4. 进入小节页面之后,抓包找到题目包。
|
||||
|
||||
|
||||
> 其他基本就是整理工作了,几个正则表达式完美解决,贴出完整代码,仅供学习所用。
|
||||
|
||||
#### 爬尔雅题目完整代码:
|
||||
```python
|
||||
import re
|
||||
from urllib import request
|
||||
from urllib import error
|
||||
|
||||
|
||||
class Mooc:
|
||||
urlInit = 'https://mooc1.chaoxing.com/course/{{courseId}}.html'
|
||||
urlK = 'https://mooc1.chaoxing.com/nodedetailcontroller/visitnodedetail?courseId={{courseId}}&knowledgeId={{knowledgeId}}'
|
||||
workUrl = 'https://mooc1.chaoxing.com/api/selectWorkQuestion?workId={{workId}}&ut=null&classId=0&courseId={{courseId}}&utenc=null'
|
||||
|
||||
headers = {
|
||||
'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
|
||||
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3'
|
||||
}
|
||||
|
||||
def __returnWorkUrl(self, courseId, workId):
|
||||
url = self.workUrl.replace('{{courseId}}', courseId).replace(
|
||||
'{{workId}}', workId)
|
||||
return url
|
||||
|
||||
def __getRequest(self, url):
|
||||
req = request.Request(url, headers=Mooc.headers)
|
||||
try:
|
||||
page = request.urlopen(req).read()
|
||||
page = page.decode('utf-8')
|
||||
return page
|
||||
except error.URLError as e:
|
||||
print('courseId可能不存在哦!', e.reason)
|
||||
exit()
|
||||
|
||||
def __getFristData(self, courseId):
|
||||
# 组装初始URL,获取第一个包含knowledge
|
||||
url = self.urlInit.replace('{{courseId}}', courseId)
|
||||
|
||||
htmls = self.__getRequest(url)
|
||||
|
||||
# <a class="wh nodeItem" href="?courseId=200080607&knowledgeId=102433017" data="102433017">
|
||||
#re_rule = 'courseId='+courseId+'&knowledgeId=(.*)">'
|
||||
|
||||
# <div id="" class="ml20 mb5 bgf3 mr10" data="102432997">
|
||||
# <div id="courseChapterSelected" class="ml20 bbe pl0 bg1e mr10" data="102433017" rel="">
|
||||
|
||||
re_rule = 'courseId='+courseId+'&knowledgeId=(.*)">'
|
||||
url_frist = re.findall(re_rule, htmls)
|
||||
|
||||
if len(url_frist) > 0:
|
||||
return url_frist[0]
|
||||
else:
|
||||
print('courseId错误!')
|
||||
|
||||
def __returnTitle(self, courseId, knowledgeId):
|
||||
url = self.urlK.replace('{{courseId}}', courseId).replace(
|
||||
'{{knowledgeId}}', knowledgeId)
|
||||
htmls = self.__getRequest(url)
|
||||
|
||||
re_rule = '":"work-(.*?)"'
|
||||
wordId = re.findall(re_rule, htmls)
|
||||
wordId = list(set(wordId)) # 先转集合,再转队列 去重复
|
||||
|
||||
title = []
|
||||
for x in wordId:
|
||||
wordUrl = self.__returnWorkUrl(courseId, x)
|
||||
html_work = self.__getRequest(wordUrl)
|
||||
title_rule = '<div class="Zy_TItle clearfix">\s*<i class="fl">.*</i>\s*<div class=".*">(.*?)</div>'
|
||||
title = title + re.findall(title_rule, html_work)
|
||||
|
||||
# <div id="" class="ml20 mb5 bgf3 mr10" data="102432997">
|
||||
# <div id="courseChapterSelected" class="ml20 bbe pl0 bg1e mr10" data="102433017" rel="">
|
||||
|
||||
#re_rule = '<a class=".*" href="\?courseId=' + courseId+'&knowledgeId=.*" data="(.*)">'
|
||||
# re_rule = '<div id="(courseChapterSelected)?" class="[\s\S]*?" data="(\d*)">?'
|
||||
re_rule = '<div id="c?o?u?r?s?e?C?h?a?p?t?e?r?S?e?l?e?c?t?e?d?" class="[\s\S]*?" data="(\d*)">?'
|
||||
datas = re.findall(re_rule, htmls)
|
||||
|
||||
return(title, datas)
|
||||
|
||||
def getTextByCourseId(self, courseId):
|
||||
data_now = self.__getFristData(courseId) # 第一个data需要再单独的一个链接里获取
|
||||
j = 1
|
||||
while data_now:
|
||||
listR = self.__returnTitle(courseId, data_now)
|
||||
|
||||
title = listR[0]
|
||||
data = listR[1]
|
||||
|
||||
for i, x in enumerate(data):
|
||||
if data_now == x:
|
||||
if len(data) > (i+1):
|
||||
data_now = data[i+1]
|
||||
else:
|
||||
data_now = None
|
||||
print('获取题目结束.')
|
||||
|
||||
break
|
||||
|
||||
# 打印题目 去除题目中的<p></p>获取其他标签,只有部分题目有,可能是尔雅自己整理时候加入的。
|
||||
for t in title:
|
||||
p_rule = '<.*?>'
|
||||
t = re.sub(p_rule, '', t)
|
||||
p_rule = '&.*?;'
|
||||
t = re.sub(p_rule, '', t)
|
||||
|
||||
print(j, t)
|
||||
j += 1
|
||||
|
||||
|
||||
mooc = Mooc()
|
||||
courseId = '200080607'#input('请输入courseId:') # '200837021' 200080607 = 189题
|
||||
if courseId:
|
||||
mooc.getTextByCourseId(courseId)
|
||||
else:
|
||||
print('请输入正确的courseId.')
|
||||
|
||||
```
|
||||
|
|
|
|||
|
|
@ -0,0 +1,112 @@
|
|||
import re
|
||||
from urllib import request
|
||||
from urllib import error
|
||||
|
||||
|
||||
class Mooc:
|
||||
urlInit = 'https://mooc1.chaoxing.com/course/{{courseId}}.html'
|
||||
urlK = 'https://mooc1.chaoxing.com/nodedetailcontroller/visitnodedetail?courseId={{courseId}}&knowledgeId={{knowledgeId}}'
|
||||
workUrl = 'https://mooc1.chaoxing.com/api/selectWorkQuestion?workId={{workId}}&ut=null&classId=0&courseId={{courseId}}&utenc=null'
|
||||
|
||||
headers = {
|
||||
'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
|
||||
r'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3'
|
||||
}
|
||||
|
||||
def __returnWorkUrl(self, courseId, workId):
|
||||
url = self.workUrl.replace('{{courseId}}', courseId).replace(
|
||||
'{{workId}}', workId)
|
||||
return url
|
||||
|
||||
def __getRequest(self, url):
|
||||
req = request.Request(url, headers=Mooc.headers)
|
||||
try:
|
||||
page = request.urlopen(req).read()
|
||||
page = page.decode('utf-8')
|
||||
return page
|
||||
except error.URLError as e:
|
||||
print('courseId可能不存在哦!', e.reason)
|
||||
exit()
|
||||
|
||||
def __getFristData(self, courseId):
|
||||
# 组装初始URL,获取第一个包含knowledge
|
||||
url = self.urlInit.replace('{{courseId}}', courseId)
|
||||
|
||||
htmls = self.__getRequest(url)
|
||||
|
||||
# <a class="wh nodeItem" href="?courseId=200080607&knowledgeId=102433017" data="102433017">
|
||||
#re_rule = 'courseId='+courseId+'&knowledgeId=(.*)">'
|
||||
|
||||
# <div id="" class="ml20 mb5 bgf3 mr10" data="102432997">
|
||||
# <div id="courseChapterSelected" class="ml20 bbe pl0 bg1e mr10" data="102433017" rel="">
|
||||
|
||||
re_rule = 'courseId='+courseId+'&knowledgeId=(.*)">'
|
||||
url_frist = re.findall(re_rule, htmls)
|
||||
|
||||
if len(url_frist) > 0:
|
||||
return url_frist[0]
|
||||
else:
|
||||
print('courseId错误!')
|
||||
|
||||
def __returnTitle(self, courseId, knowledgeId):
|
||||
url = self.urlK.replace('{{courseId}}', courseId).replace(
|
||||
'{{knowledgeId}}', knowledgeId)
|
||||
htmls = self.__getRequest(url)
|
||||
|
||||
re_rule = '":"work-(.*?)"'
|
||||
wordId = re.findall(re_rule, htmls)
|
||||
wordId = list(set(wordId)) # 先转集合,再转队列 去重复
|
||||
|
||||
title = []
|
||||
for x in wordId:
|
||||
wordUrl = self.__returnWorkUrl(courseId, x)
|
||||
html_work = self.__getRequest(wordUrl)
|
||||
title_rule = '<div class="Zy_TItle clearfix">\s*<i class="fl">.*</i>\s*<div class=".*">(.*?)</div>'
|
||||
title = title + re.findall(title_rule, html_work)
|
||||
|
||||
# <div id="" class="ml20 mb5 bgf3 mr10" data="102432997">
|
||||
# <div id="courseChapterSelected" class="ml20 bbe pl0 bg1e mr10" data="102433017" rel="">
|
||||
|
||||
#re_rule = '<a class=".*" href="\?courseId=' + courseId+'&knowledgeId=.*" data="(.*)">'
|
||||
# re_rule = '<div id="(courseChapterSelected)?" class="[\s\S]*?" data="(\d*)">?'
|
||||
re_rule = '<div id="c?o?u?r?s?e?C?h?a?p?t?e?r?S?e?l?e?c?t?e?d?" class="[\s\S]*?" data="(\d*)">?'
|
||||
datas = re.findall(re_rule, htmls)
|
||||
|
||||
return(title, datas)
|
||||
|
||||
def getTextByCourseId(self, courseId):
|
||||
data_now = self.__getFristData(courseId) # 第一个data需要再单独的一个链接里获取
|
||||
j = 1
|
||||
while data_now:
|
||||
listR = self.__returnTitle(courseId, data_now)
|
||||
|
||||
title = listR[0]
|
||||
data = listR[1]
|
||||
|
||||
for i, x in enumerate(data):
|
||||
if data_now == x:
|
||||
if len(data) > (i+1):
|
||||
data_now = data[i+1]
|
||||
else:
|
||||
data_now = None
|
||||
print('获取题目结束.')
|
||||
|
||||
break
|
||||
|
||||
# 打印题目 去除题目中的<p></p>获取其他标签,只有部分题目有,可能是尔雅自己整理时候加入的。
|
||||
for t in title:
|
||||
p_rule = '<.*?>'
|
||||
t = re.sub(p_rule, '', t)
|
||||
p_rule = '&.*?;'
|
||||
t = re.sub(p_rule, '', t)
|
||||
|
||||
print(j, t)
|
||||
j += 1
|
||||
|
||||
|
||||
mooc = Mooc()
|
||||
courseId = '200080607'#input('请输入courseId:') # '200837021' 200080607 = 189题
|
||||
if courseId:
|
||||
mooc.getTextByCourseId(courseId)
|
||||
else:
|
||||
print('请输入正确的courseId.')
|
||||
Loading…
Reference in New Issue